|
본 리뷰는 2021년도 CICC의 Session 31, SAR Converters에 대한 것이다.
총 4개의 논문이 이번 session 31에서 소개가 되었다. 미국[S31-1]과 네덜란드[S31-3]에서 각각 1개의 논문을 발표하였고, 중국[S31-2, S31-4]에서 나머지 2개의 논문을 발표하였다.
4개의 논문 모두 CMOS 공정에서 칩으로 제작되었고 그 중 2개는 28-nm 공정에서[S31-1, S31-2], 각각 남은 1개씩은 65nm 공정[S31-3]과 130nm 공정[S31-4]에서 제작되었다.
이번 SAR Converters session에 소개된 논문들은, RF sampling transceivers, autonomous sensor node등의 application을 타겟으로 한 high resolution, high linearity, high energy-efficiency SAR ADCs 설계에 초점을 맞추고 있다.
소개된 4편의 논문을 주제별로 살펴본다면, [S31-1]에서는 Pipelined-SAR ADCs, [S31-2]에서는 Noise-Shaping Pipelined-SAR ADCs, [S31-3]에서는 Oversampling SAR ADCs, [S31-4]에서는 Noise-Shaping SAR ADCs을 각각 주제로 다루고 있다. 이 4편의 논문 중에서 2편의 논문[S31-2, S31-4]이 Noise-Shaping(NS) SAR ADCs에서 기존 논문들의 단점을 보안, 개선한 noise-shaping techniques들을 소개하고 있어서, 이번 session에서 눈여겨볼만한 점이라고 할 수 있다.
앞서 언급한 내용처럼, 제시된 4개의 구조들은 높은 resolution과 linearity을 가지면서도 적은 power을 동작 할 때 사용하는 특징이 있다. 4편의 논문에서 제시한 spec을 확인해 보면 1V 근방의 power supply을 사용하여 low power을 달성하면서, 동시에 비슷한 구조 대비 상대적으로 높은 SFDR, SNDR을 얻을 수 있어 결과적으로 좋은 수치의 FoM(Figure of Merit)을 나타내고 있음을 확인할 수 있다.
4가지의 논문에 소개된 주요 idea, techniques에 대하여 간단하게 살펴보겠다.
Session 31-1은 direct RF sampling을 할 때 RF frequencies 대역에서 발생하는 제한된 SFDR/SNDR 문제점을 개선하기 위하여 high speed, high linearity, medium resolution을 가지는 1GS/s 12bit single-channel Pipelined-SAR ADCs을 제안하였다. 이 구조는 3-stage의 Pipe-SAR ADCs로 이루어져 있으며 동작은 fully asynchronous하다. High-sampling-rate의 ADC을 설계하기 위해서는 residue amplifier과 sampling switch가 신중히 설계되어야 한다. 이 논문에서는 novel harmonic-injecting cross-coupled pair(HXCP) 구조를 Gm-R 기반의 residual amplifier에 포함시켜 harmonic의 영향을 감소시켜 linearity을 개선하였다. 또한, fast N-replica bootstrap switch을 이용하여 sampling clock의 transition time을 줄여 linearity을 증가시켰다.
Session 31-2는 느린 sequential integration 과정 때문에 band-width을 제한하는 dynamic amplifier(D-amp)을 단 1개만 사용하면서 noise-shaping(NS) efficacy을 optimized zeros와 함께 2차까지 증가시킨 구조를 제시하고 있다. 결과적으로 6.5의 작은 OSR을 가지면서도 8.5dB의 높은 SQNR 성능을 나타내었다.
Session 31-3은 autonomous sensor node에 필요한 low power, high linearity, high resolution을 구현하기 위하여 DAC의 mismatch을 개선시킨 구조를 설계하였다. 이 논문에서는 pre-comparison technique을 이용하는 mismatch error shaping(MES) oversampling SAR ADC을 제안하였다. 이 구조의 특징으로는 segmentation, DWA 등의 복잡한 구조를 사용하지 않는다는 것이다. 또한, DAC mismatch 이외의 comparator noise을 개선하는 방법으로서, 부가적인 회로들이 더 필요한 noise shaping 구조 대신 area-efficient 한 chopping을 사용한 구조를 선택하였다. 결과적으로, 이 구조는 103dB의 SFDR과 0.033mm²의 면적, 0.98μW의 power 소모를 달성하였다.
Session 31-4는 기존에 noise shaping(NS) SAR ADC에서 noise filtering을 할 때 많이 사용하던 cascaded integrator feed-forward(CIFF) 또는 error-feedback(EF) 구조 대신 2개의 EF NS stage와 CIFF stage을 합친 구조를 사용하여 설계를 진행하였다. 제시된 hybrid error-control(HEC) 구조는 앞서 언급된 두 구조의 장점을 가져가면서도 그들의 단점은 보완할 수 있기 때문에 단순하고 PVT에 둔감하다. 8bit SAR을 사용하여 이 논문은 79.57dB의 SNDR, 170.7dB의 Schreier FoM을 달성하였다.
본 리뷰는 2021년도 CICC의 Session 26, Delta-Sigma Converters에 대한 것이다.
총 5개의 논문이 이번 session 26에서 소개가 되었다. 중국[S26-1, S26-5]에서 2개의 논문을 발표하였고, 독일[S26-2, S26-3, S26-4]에서 나머지 3개의 논문을 발표하였다. 특히 이 중에서 S26-3, S26-4 논문은 한 저자가 발표한 논문이다.
5개의 논문 모두 CMOS 공정에서 칩으로 제작되었고 그 중 1개는 180-nm 공정에서[S26-1], 1개는 28-nm 공정에서[S26-2], 1개는 40-nm low power(LP) 공정에서[S26-5], 남은 2개는 22-nm FDSOI 공정[S26-3, S26-4]에서 제작되었다.
이번 Delta-Sigma Converters session에 소개된 논문들의 큰 trend는 IoT application의 발전과 상용화에 따른, IoT application에 적합한 microwatt(low power) data converter의 설계이다. Battery나 harvested energy로 동작하는 IoT application들은 작은 신호를 감지하기 위하여 높은 dynamic range(DR)을 가지면서도 micro 단위의 low power, 높은 linearity와 band-width등이 필수적이다. 기존 구조의 단점을 개선하면서 이러한 필요성에 부합하는 구조들을 이번 session에서 소개하고 있다.
소개된 5편의 논문을 주제별로 살펴본다면, [S26-1]에서는 Dynamic Discrete-time delta-sigma modulator(DTDSM), [S26-2]에서는 Continuous-time incremental delta-sigma ADCs, [S26-3]에서는 Continuous-time delta-sigma modulator with inter-symbol interference(ISI) calibration, [S26-4]에서는 Continuous-time delta-sigma modulator with input signal tracking, [S26-5]에서는 VCO-based continuous-time delta-sigma ADCs을 각각 주제로 다루고 있다. 이 5편의 논문 중에서 특징적인 부분은 continuous-time delta-sigma ADCs을 다룬 다른 4개의 논문과 다르게 discrete-time delta-sigma ADCs을 제안한 S26-1 논문과, 최근에 인기를 얻고 있는 VCO-based delta-sigma ADCs을 제안한 S26-5가 있다. 그 두 가지 논문에서 소개한 주요 idea, techniques에 대하여 간단하게 살펴보겠다.
Session 26-1은 programming overhead 없이 4x band-width/power scaling이 가능한 fully dynamic discrete-time delta-sigma modulator(DTDSM) 구조를 제안하고 있다. 논문의 저자는 high-resolution을 얻기 위하여 DTDSM 구조를 선택하였다. 하지만, 이 구조에서는 OTAs에서 static bias current가 흐르고 common-mode feedback(CMFB)가 필요해 settling에 추가적인 시간이 필요한 문제가 있다. CTDSM(continuous-time) 역시 high power efficiency을 가지지만 동일한 문제가 있다. 이러한 문제를 해결하기 위하여 논문에서는 capacitively biased swing-enhanced floating inverter amplifier(SEFIA)을 이용했다. SEFIA는 기존 FIA보다 output swing을 더 키울 수 있고, robust 하며, f_s-adaptive operating point control이 가능하다. 이러한 개선점들은 switch, capacitor들로만 구현이 가능하기 때문에 power면에서 효율적이다.
Session 26-5는 VCO-based delta-sigma ADCs을 제안하고 있다. 이러한 구조에서 high resolution, wide detection range phase quantizers는 energy efficiency을 증가시키기 위해서는 필수적이다. 하지만 기존 PFD-based quantizer의 여러 문제점 때문에 이 논문에서는 double-PFD(DPFD) quantizer을 가지는 구조를 제안하고 있다. 이 구조는 두 가지 큰 장점이 있는데, 1번째는 rising, falling 두 개의 edge을 다 detect하며 VCO phase output을 이용한다는 것이다. 이를 통해 PFD-based quantizer에 비해 2배 높은 resolution을 얻을 수 있다. 2번째는 기존과 비교하여 2배의 gain 증가가 있다는 점이다. 같은 loop gain을 가지는 상황에서 VCO gain requirement을 2배 완화시키거나, sampling rate을 2배 증가시킬 수 있다. 또한, inter-symbol interference(ISI)와 digital logic power도 2배 감소시킬 수 있다. 이를 통해 81.5dB DR, 1.25MHz BW, 379μW의 성능을 보여준다.
앞서 언급한 내용처럼, 제시된 5개의 구조들은 적은 면적, 저전력, 높은 resolution등의 지표를 보여주고 있다. 5편의 논문에서 제시한 spec을 확인해 보면 3mW 이내의 low power을 달성하면서, 동시에 1〖mm〗^2 이내의 active area을 사용하여 area-efficient한 성능을 보여주고 있음을 확인할 수 있다.
 |
|
| #Digital Circuits, SoCs, and Systems |
|
ㆍSession 22 / Circuits for Machine Learning and cryo-CMOS Applications
|
|
CICC의 Session 22에서는 전체적으로 딥러닝 관련 연산을 고성능, 효율적으로 수행하는 방법에 대한 연구들이 소개되어 있다. 특히 딥러닝 관련 Figure of Merit (FoM)을 향상시키기 위해 연산을 빠르고 에너지 효율적이게 하는 방법들에 대해 중점적으로 연구되어 있다. Computing-in-memory (CIM) 방식의 혼성신호 회로를 소개하는 2개의 논문과 알고리즘 개선 방식의 아키텍처를 소개하는 1개의 논문을 다뤄보겠다.
|
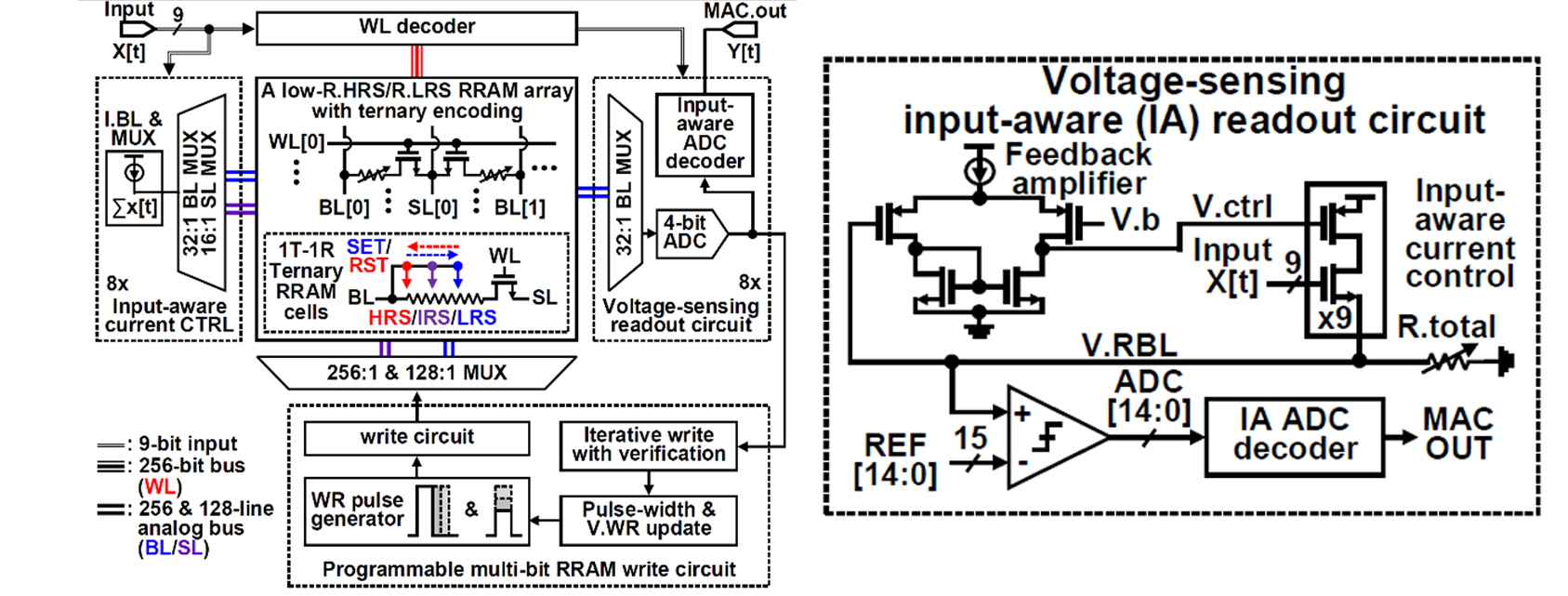 |
| [그림 1] (좌) Ternary 가중치 CIM RRAM macro의 아키텍처, (우)제안하는 전압 sensing readout 회로 |
|
#22-1는 Georgia Tech와 DGIST에서 발표한 논문으로 RRAM (Resistive RAM)을 이용해 CIM 기능을 구현했다. 이를 이용해 multi-bit encoding을 진행할 때, high resistance state (HRS)와 low resistance state (LRS) 사이의 높은 저항비가 read margin에 유리한데, 이는 endurance에 영향을 주는 tradeoff 관계가 존재한다. 그래서 이 논문에서는 이러한 ternary weight 네트워크 구조에서, multiply-and-accumulate (MAC)된 출력을 전압 기반으로 read하는 CIM RRAM macro를 제안한다. 그림 1의 오른쪽과 같이 켜지는 RRAM 셀의 개수에 비례하게 전류를 제공하는 input-aware (IA) readout 회로를 통해 감지하고 비선형성을 줄이기 위해 active feedback 구조를 적용해, 이 출력을 4b flash ADC를 통해 읽는다. 또한 RRAM의 저항값의 분포를 좁히기 위해서 iterative write with verification (IWR)을 도입해 bitline (BL)의 전압으로 해당 RRAM의 저항값이 목표 저항값에 도달했는지 추정한고 이를 조절한다. 이러한 방식을 통해 AI benchmark에서 5%보다 적은 정확도 손실로 118.44TOPS/W의 에너지 효율을 보여줬다.
|
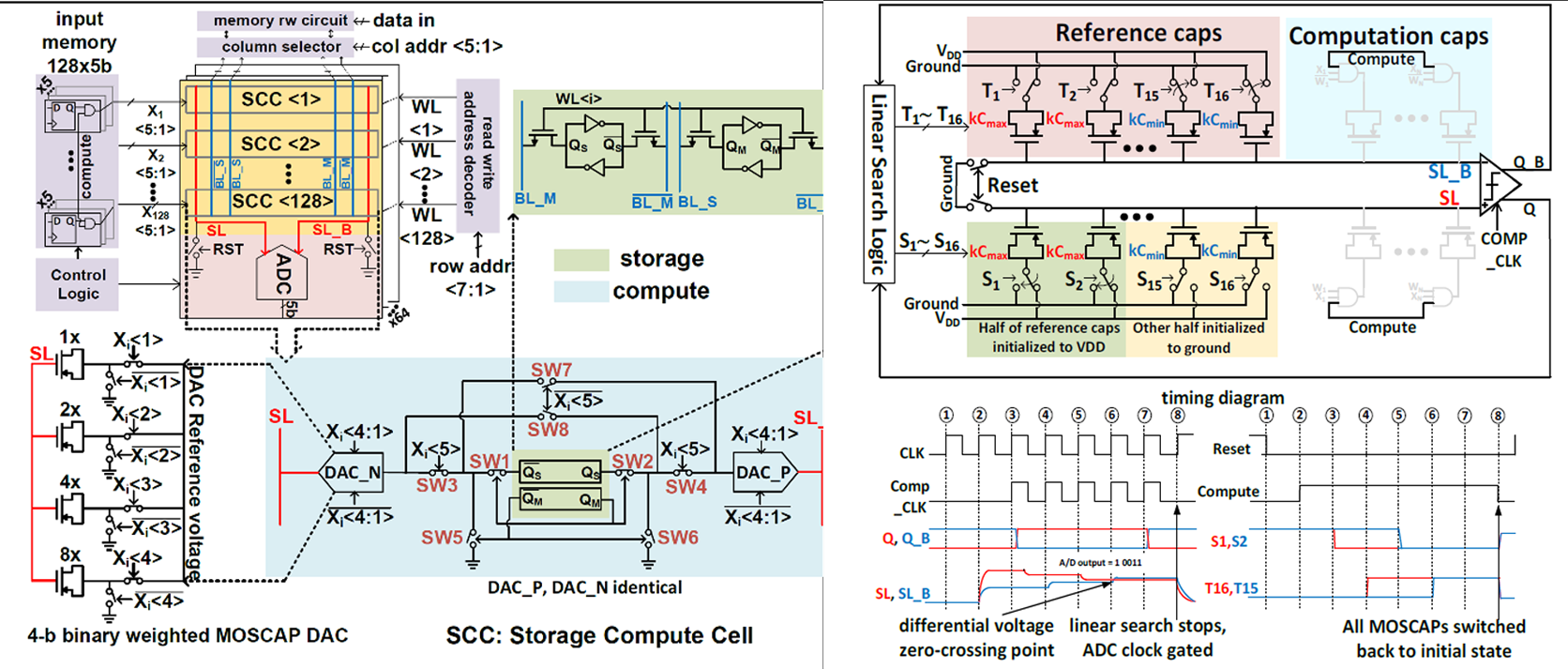 |
| [그림 2] (좌) 제안하는 CIM 회로, (우) MAV quantization 할 때의 5b linear search 회로 |
|
#22-2는 Southern California University에서 발표한 논문으로 딥러닝 연산에서 주로 사용되는 Matrix-Vector Multiplication (MVM)의 가속에 대한 방법을 논한다. 이전 연구들의 전류 기반 연산은 DAC의 정적전력 소모와 전류원의 비선형성에 의해 제한을 받게 된다. 그래서 전하 기반인 MOSCAP 기반의 in-memory DAC를 사용하는 CIM 아키텍처를 그림 2의 왼쪽과 같이 제안한다. 각 storage compute cell (SCC)이 elementwise로 multiply-and average (MAV) 연산을 하게 되고 그 bitwise 곱이 DAC_P나 DAC_N으로 부호에 따라 쌓이게 된다. 그리고 이 128개의 SCC가 differential voltage로 다 합해지면서 ADC를 통과하면서 MVM이 이루어지게 된다. 이 때 MOSCAP DAC 같은 경우, 전압에 비례하는 캐패시턴스 특성을 이용해 passive gain을 얻게 되고 reset과 computation phase를 통해 DAC의 출력이 증폭돼 noise 및 정확도에 유리하게 된다. 또한, MAV 출력을 quantize할 때, 그림 2의 오른쪽과 같이 MOSCAP replica를 통한 linear search ADC를 수행하게 되고, 이를 통해 sampling 회로를 없앨 수 있었다. 이러한 방식을 통해 MNIST 데이터셋을 LeNet-5 구조로 테스트했을 때, 98.7%의 정확도와 331TOPS/W의 에너지 효율을 얻을 수 있었다.
|
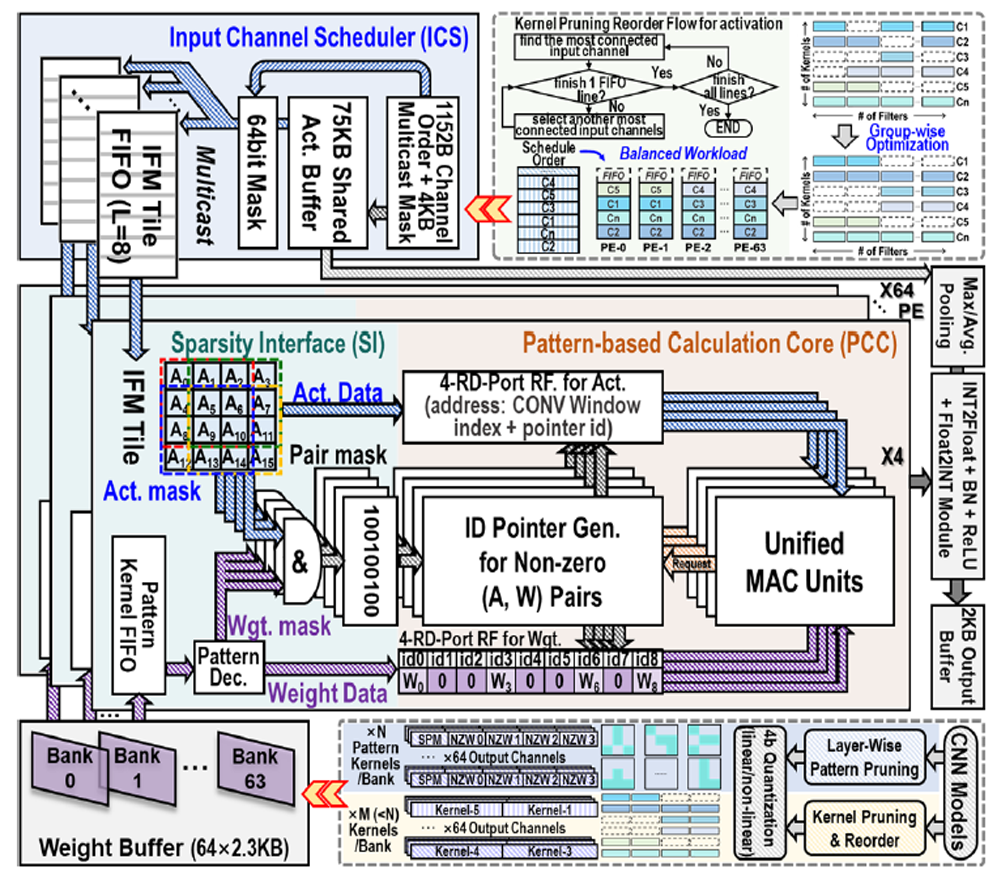 |
| [그림 3] 전체적인 아키텍처 및 pattern과 kernel pruning을 위한 weight와 activation 전처리 과정 |
|
#22-3은 Tsinghua University에서 발표한 논문이다. 딥러닝 가속기에서는 연산과 메모리에 부담을 줄이기 위해 weight pruning과 quantization이 사용한다. 하지만 이는 불균형의 kernel 수를 만들고, resource utilization에 악영향을 끼친다. 이전 연구들은 특정 상황만 고려해서, 통합적으로 다룰 수 있는 아키텍처의 필요성이 있다. 효율적인 processing engine (PE)와 input channel scheduler (ICS)를 통해 SW로 다양한 pruning을 group-wise optimized 방식으로 pattern-kernel encoding을 수행할 수 있다. 특히 이러한 알고리즘 기반으로 PE idle 시간을 많이 줄일 수 있었다. 또한 통합된 MAC 모듈을 만들어 linear, power-2 quantization, mixed power-2 quantization 모드를 지원하면서 기존 decoder나 곱셈기를 대체했다. 이러한 방식으로 VGG-16과 ResNET-18 구조로 8.1TOPS/W 에너지 효율을 얻을 수 있었고 inter/intra-kernel sparsity와 linear/nonlinear quantization을 한 구조로 통합할 수 있다는 것을 보여주었다.
|
| #Power Management |
|
ㆍSession 23 / Emerging Power Converters
|
|
이번 CICC 2021에서 power management 분야에 관하여 다양한 논문들이 발표되었다. Power management 분야에서는 여러 분야에서 공통으로 적용되는 converter를 보다 효율적으로, 보다 소형화하고 동시에 전력 소모는 줄이는 방향으로 연구가 이루어진 것을 알 수 있다. 보다 소형화하기 위해 인덕터와 같은 off-chip 부품은 최소한으로 줄이고, 에너지 소모 최소화를 위한 최적화도 진행되었다. 최적화를 위해 기존과는 다른 알고리즘이나 신경망을 적용하는 등 다각화된 연구 결과를 볼 수 있었다.
#23.2 Envelope-Tracking Supply Modulator with Trellis Search-Based Switching and 160MHz Capability
기존의 power amplifier는 envelope-tracking supply modulator (ETSM)는 hybrid amplifier(HA)를 이용한 다중 frequency sub-bands와 multi-stage buck converter를 사용해 효율을 높였다. 그러나 여러 개의 converter로 인해 off-chip 인덕터 개수가 그에 따라 증가해 크기가 커지고, amplifier의 error current로 인한 신호 lagging, switching 회수 증가 등으로 효율이 저하된다. HA 대신 ‘Trellis-search’ 알고리즘과 digital bang-bang logic을 적용해 error current를 최소화할 수 있는 switching sequence를 찾아내고, switching 회수를 최적화하여 loss를 줄였으며, 이를 FPGA를 통해 구현하였다. 최종적으로 동일 전력 전달 조건에서 기존 대비 공급 전류가 10mA 감소하였으며, 인덕터는 한 개만을 사용해 크기도 감소하였다.
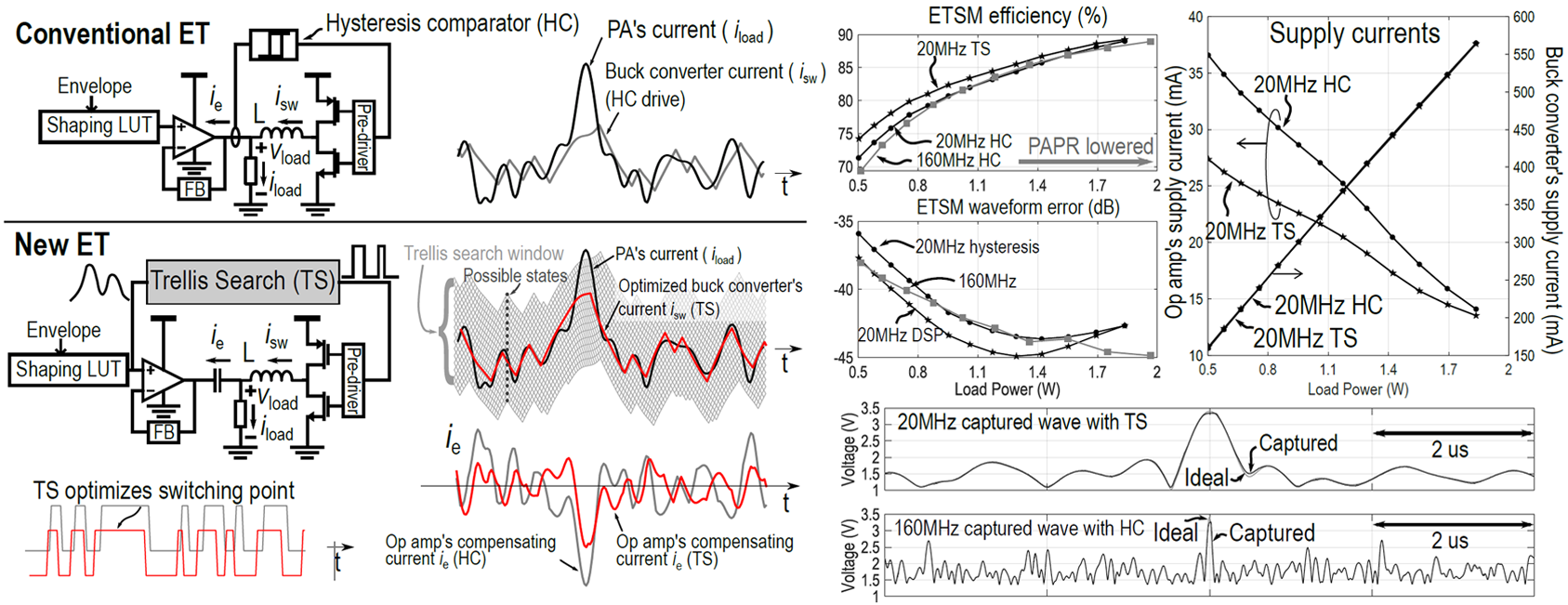 |
| [그림 1] 기존 구조와 제안하는 구조의 비교 (좌), 제안하는 구조의 측정 결과 (우) |
|
#23.3 An Analog Low-Power Highly-Accurate Link-Adaptive Energy Storage Efficiency Maximizer for Resonant CM Wireless Power Receivers
무선 전력 전송이 작동하는 환경은 크게 (1) small-and-continuous (2) large-and-intermittent 두 가지로 분류할 수 있다. 이 중에서 (2) 환경의 경우, mm-scale converter를 사용하면 유도되는 전력 수준으로는 부하를 구동하기 부족해, 외부 에너지 저장소에 의존할 수밖에 없는데, 기존 연구는 저장소 효율 및 동작 시작 후 단계에 최적화되어있지 않아 변화에 능동적으로 대응할 수 없었다. 따라서 최대 전압 크기를 sensing하고 충전 시간과 충전 회수의 곱이 최대가 되는 지점이 저장소의 최적의 충전 cycle이라는 것을 도출하여 이를 적용하였다. 이를 통해 최적의 충전 cycle을 구하고, early 전환 대비 69.7% 개선, late 전환 대비 52.5%가 개선되었으며, IC는 전체 에너지의 1.7%만을 소모한다
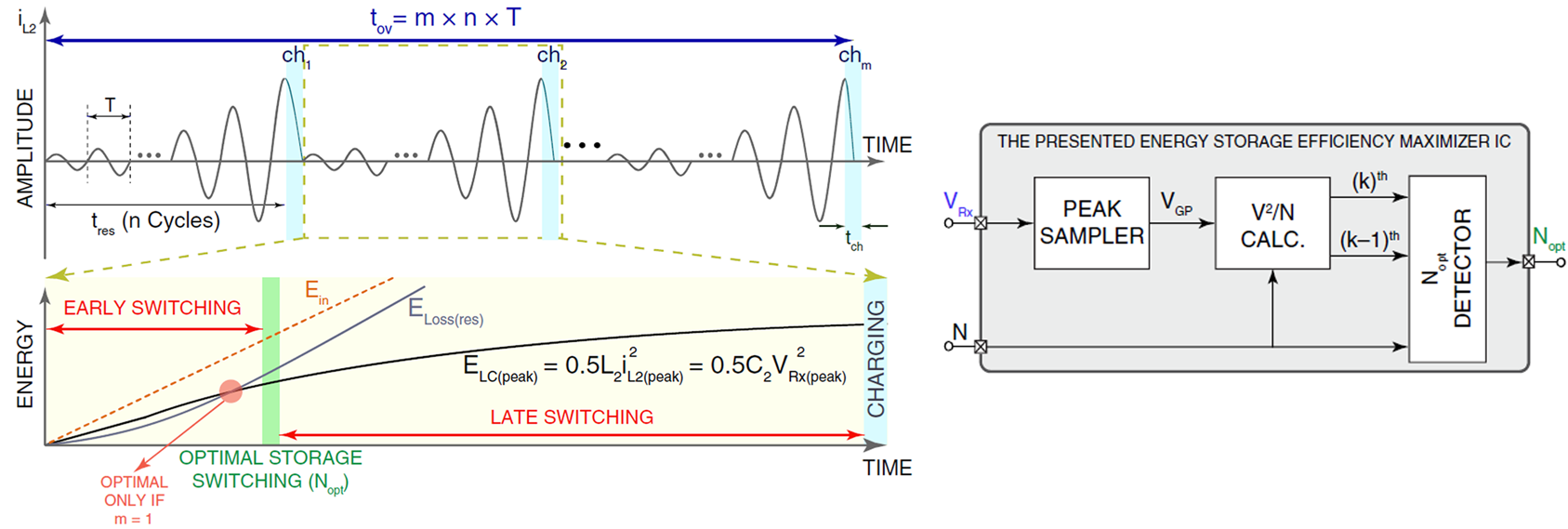 |
| [그림 2] 14.2에서 소개한 multimodal hierarchical sensing |
|
#23.4 A Battery-Connected Inductor-First Flying Capacitor Multilevel Converter Achieving 0.77W/mm2 and 97.1% Peak Efficiency
일반적인 buck converter는 high-side에 인덕터가 위치하는데, 인덕터의 높은 DC Resistance (DCR) loss가 크게 나타나거나, 5V의 high-voltage 트랜지스터가 필요한 문제가 있다. 본 논문은 출력 인덕터를 half-sized 인덕터 두 개로 나누어 입력과 직렬로 연결하는 inductor-first 구조를 적용해 high-side에 위치하지 않게 설계했다. 이를 통해 continuous, non-chopped 입력 전류를 제공해 EMI가 감소하고, 흐르는 전류가 기존 대비 감소해 net conduction loss도 감소했다. 그 밖에도 flying capacitor multilevel(FCML) 구조를 같이 적용해 인덕터에 가해지는 전압 swing 범위를 기존의 1/3로 줄여 CMOS 공정에 호환되도록 설계했다. CMOS 공정 호환으로 전체 시스템을 소형화하여 0.77W/mm2의 power density를 얻고, continuous 입력 전류로 입력 전압 ripple이 3배 감소하는 결과를 얻게 되었다.
 |
| [그림 3] 14.2에서 소개한 multimodal hierarchical sensing |
|
#23.5 An Efficient Wireless Power and Data Transfer System with Current-Modulated Energy-Reuse Back Telemetry and Energy-Adaptive Dual-Input Voltage Regulation
Near-field 무선 전력 전송을 효율적으로 구현하기 위해 coupled coil을 이용하는 방식이 널리 사용되며, 그중에서 short-coil-based back telemetry (SC-BT) scheme을 많이 활용한다. 그러나 해당 방식은 동작 특성상 short-coil 주기마다 ground로 흐르는 전류가 발생해 에너지가 낭비되고, high-rate 동작을 위해 동작 회수를 증가시키면 그에 비례해 short-coil 주기가 짧아져 에너지 소모가 증가하는 문제가 존재한다. 본 논문은 ground로 나가던 에너지를 추가한 커패시터에 저장하여 LDO에 공급하여 재활용하는 energy-reuse(ER) 방식을 제안한다. LDO는 energy-adaptive dual-input 구조로 커패시터 저장소 또는 converter로부터의 입력을 adaptive하게 활용하여 부하에 최대 전력을 전달한다. 기존 대비 전력 소모가 41%가 개선되었으며, 최대 75%의 효율을 보였다.
|
 |
| [그림 4] ER 방식의 개념도와 성능 측정 결과 |
|
#23.6 A General-Regression-Neural-Network Based 5V-to-48V Three-Level Buck/Boost Power Converter with 40dB PSRR 90%-Efficiency for SSD Power Loss Protection
SSD에는 예기치 못한 power loss에 의한 데이터 손상을 막기 위해 예비 전원을 확보하는 power loss protection (PLP) 회로가 필요한데, PLP 회로 converter의 입력은 매우 짧은 시간에 크게 변화해 line regulation에 문제가 있고, compensation network에 의한 slow feedback loop로 인해 transient response가 제한된다. 본 논문은 General-regression-neural-network (GNRR)를 적용해 저장소 전압, 부하 전류, 온도 등의 입력 변수와 원하는 출력 전압 간의 관계를 통해 그에 따른 이상적인 PWM 신호를 생성하기 위한 전압을 연산하여 도출하는 방식을 제안한다. GNRR approach를 통해 compensation network를 제거해 response time을 개선하고 전력 소모도 감소했다. 그 밖에도 three-level 구조로 GaN power switch에 가해지는 voltage stress를 완화했다. 100 세트의 raw data를 학습 시켜 출력 전압의 최대 오차 값은 0.16 V(ideal 출력 전압=5 V)로 제한되고, line/load transient response = 200 mV/200 μsec, PSRR = 40 dB 의 결과를 얻었다. Converter에 신경망을 적용하여 데이터를 학습시키는 접근 방식이 인상적이다.
|
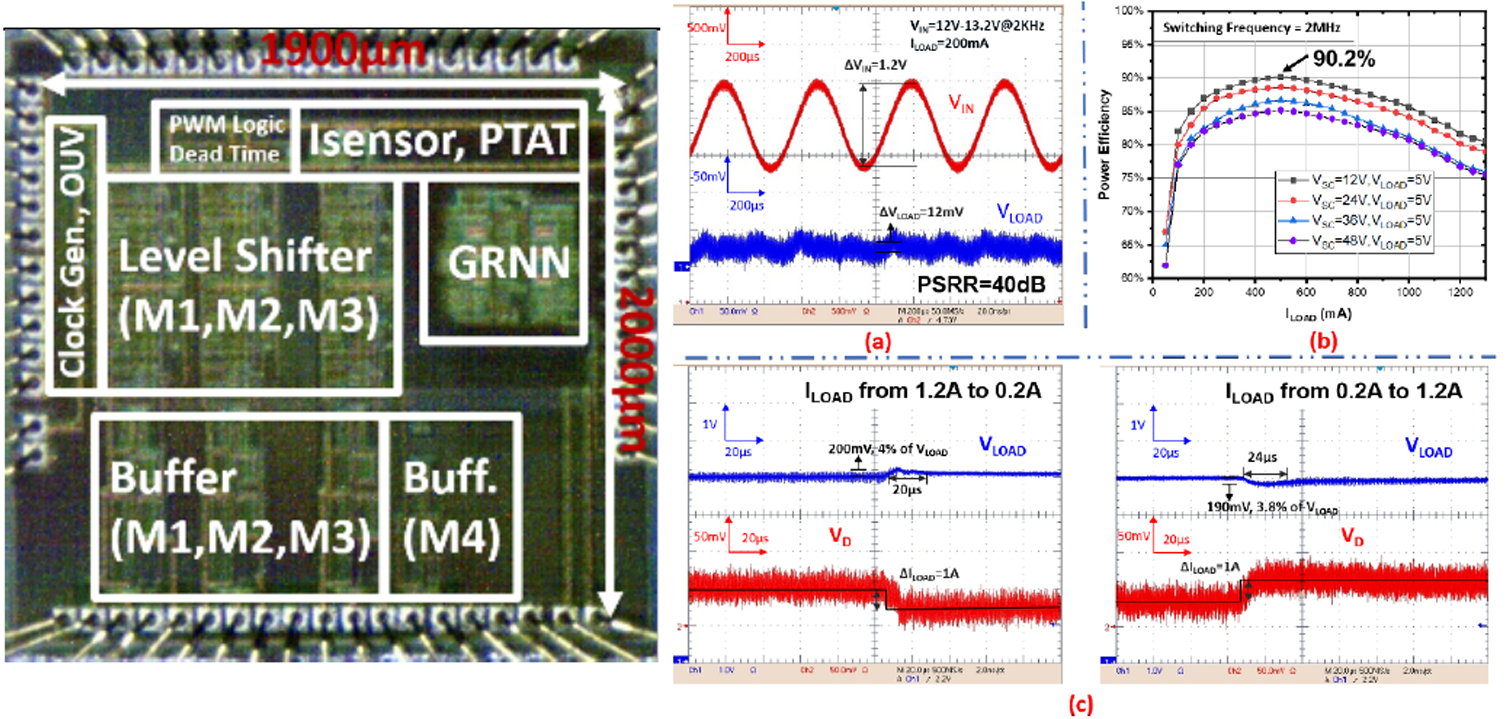 |
| [그림 5] Die micrograph 및 측정 결과 |
| #Wireless Transceivers and RF/mm-Wave Circuits and Systems |
|
ㆍSession 12 / mm-Wave Circuits and Transceivers
ㆍSession 16 / Frequency Generation
ㆍSession 24 / Millimeter Wave Power Amplifiers and Transmitters
ㆍSession 30 / Low Power and High Precision – RF Potpourri
|
|
CICC 2021에서는 총 8개의 분과('Analog Circuits and Techniques', 'Data Converters', 'Design Foundations', 'Digital Circuits, SoCs, and Systems', 'Emerging Technologies, Systems, and Applications', 'Power Management', 'Wireless Transceivers and RF/mm-Wave Circuits and Systems', 'Wireline and Optical Communications Circuits and Systems')가 18개의 세션으로 나누어져 89개의 논문들이 발표되었다. 그 중 Wireless Transceivers and RF/mm-Wave Circuits and Systems 분과는 4개의 세션(12, 16, 24, 30 세션)으로 구성이 되어 8개의 분과 중 가장 많은 세션을 포함하고 있고, 19개의 논문들이 발표되었다.
세션별 논문들을 살펴보면,
세션 12(mm-Wave Circuits and Transceivers)에는 mm-Wave 대역에서 회로 설계 아이디어와 송수신기 아키텍처를 제시하는 8개의 논문이 포함되어 있다. 이 논문들은 노이즈, 에너지 효율성, 어레이 확장성, 공간 간섭, 편광 및 신호 추적과 같은 문제를 해결하는 것을 목표로 하고 있다. [12-1]은 초청 논문으로 6G 무선 통신 회로에 대한 최신 연구에 대해 발표하고 있고, 이어서 [12-2]는 coupled-line-based gm-boosting 및 노이즈 캔슬링을 활용하여 84.9 ~ 107GHz에서 저잡음 및 고 선형성을 가진 LNA를 제시하고 있다. [12-3]에서는 23 ~ 39GHz에서 작동하는 매우 낮은 잡음을 보여주는 새로운 LNA 기술을 제안하고 있다. [12-4]는 확장 가능한 Phased-Array 수신기에 대한 논문이며, [12-5]는 빠른 편광 정렬 추적 수신기에 대하여 보여주고 있다. 그 다음에는 향상된 신호 추적 및 blocker rejection을 위해 새로운 기술을 제안하는 두 개의 논문[12-6, 7]이 이어진다. 마지막으로 [12-8]은 220GHz에서 완전히 통합된 에너지 효율적인 20Gbps OOK 무선 송신기를 제안하고 있다.
세션 16(Frequency Generation)에는 mm-wave 및 양자 컴퓨팅 애플리케이션을 위한 고급 주파수 생성 기술에 대한 4개의 논문이 포함되어 있다. [16-1] 논문은 10mW 미만을 소비하면서 192fs의 최소 RMS 지터를 달성하는 40.5GHz 서브 샘플링 PLL을 제안하고 있다. 두 번째 논문[16-2]에서는 FoMT가 201dBc/Hz인 8.2 ~ 21.5GHz 듀얼 코어 쿼드 모드 VCO를 제안한다. 세 번째 논문[16-3]은 8 ~ 101.6GHz의 넓은 작동 주파수를 가진 링 오실레이터 기반 Injection-Locked Frequency Divider에 대해 발표하였다. 마지막 논문[16-4]은 4.2K의 극저온에서 45fs RMS 지터를 달성하는 양자 컴퓨팅을 위한 2.7mW 서브 샘플링 PLL을 제시하고 있다.
세션 24(Millimeter Wave Power Amplifiers and Transmitters)에서는 피크 및 백 오프 효율 향상, 넓은 대역폭, 감소된 면적을 위한 고급 mm-wave PA 및 TX 아키텍처에 대한 논문과 상위 mm-wave 대역의 고효율 실리콘 및 III-V PA에 대한 초청 논문을 포함해 4개의 논문이 발표되었다. [24-1]은 300MHz 64-QAM OFDM 신호를 전송하면서 효율 향상을 달성하는 디지털 폴라 4-way 시리즈 Doherty 송신기를 제안하고 있고, [24-2]는 초청 논문으로 100 ~ 300GHz 대역에서 고효율 실리콘 및 III-V 전력 증폭기에 대해 주장하고 있다. [24-3]에서는 피크 및 백 오프 효율 향상을 달성하는 Class E/F2,2/3 PA에 대해 제시하고 있고, 초소형 광대역 PA를 설계하기 위한 folded 변압기 기술을 [24-4] 논문에서 제안하였다.
세션 30(Low Power and High Precision – RF Potpourri)에서는 저전력과 광대역, 센싱을 위한 고정밀 기술, 스펙트럼 분리를 포함한 다양한 애플리케이션에 적합한 신호 처리, 자율 전자 시스템 및 LiDAR에 대한 논문들 3개가 포함되어 있다. [30-1]은 초청 논문으로 나노리터 / power-scale 초저면적 / 자율센서 / biomedical 응용을 위한 시스템 달성을 대해 논의하고 있다. [30-2]에서는 PWM-LO 기반 서브 밴드 이퀄라이제이션을 지원하는 800MHz, 광대역 1.6GS/s 스펙트럼 채널 라이저를 제시하고 있는데, 스펙트럼 대역 분리에 적합한 채널 라이저는 채널 대역폭 당 100MHz로 100 ~ 800MHz에 걸쳐 있다. [30-3]에서는 튜닝 범위가 40dB인 Inverter-Based Phase-Invariant PGA (PI-PGA)가 있는 6μm 정밀도, ± 10cm 동적 범위 펄스 코히어런트 LiDAR 센서를 제안하고 있다.
|
 |
|
| #Wireline and Optical Communications Circuits and Systems |
|
ㆍSession 11 / Advanced Electrical and Optical Communication Circuits and Systems
|
|
COVID-19가 발생한 이후, 온라인 스트리밍 서비스와 직장 내에서의 커뮤니케이션 프로그램의 수요가 여러 배로 증가했다. 이에 따라 Session 11의 논문들에서는 기하 급수적으로 증가하는 데이터의 용량을 감당하기 위해 전송 속도를 향상시킬 것을 공통적으로 언급했다. 또한 송수신기가 맞이할 문제로는 1) 서버가 부담하는 처리량의 증가, 2) 채널 손실이 유발하는 한계, 3) 전력 제약 4) Clock의 위상 노이즈, 5) 신호의 비선형성 가 언급되었다. 뒤에 이어질 본문의 내용에서는 각 논문들이 위의 문제들을 해결한 방법에 대해 서술하겠다.
56/112Gbps Wireline Transceivers for Next Generation Data Centers on 7nm FINFET CMOS Technology[11.1] 는 송수신기가 맞이할 문제 중에서 2) 채널이 유발하는 한계를 극복하는 법을 제시한다. 이 논문에서는 목표로 삼고 있는 데이터 전송률은 112Gb/s이고, 112Gbps의 데이터를 처리하는 모든 채널은 장거리 채널이다. 예를 들어 일반적인 WAN 포트 스위치 채널은 56Gbps 속도에서 최소 20dB 손실이 있고, 대부분의 112Gbps 채널은 35dB 이상의 채널 손실이 있다. 채널 손실이 유발하는 한계를 극복하기 위해 이 논문에서는 DSP 기반 송수신기를 설계하였다. DSP 기반 송수신기를 사용하면 아날로그 송수신기에 비해서 장거리 채널의 영향을 좀 더 극복할 수 있다는 장점이 있기 때문이다. 하지만 단점으로는 전력 소모가 더 많고, 공간을 많이 차지한다.
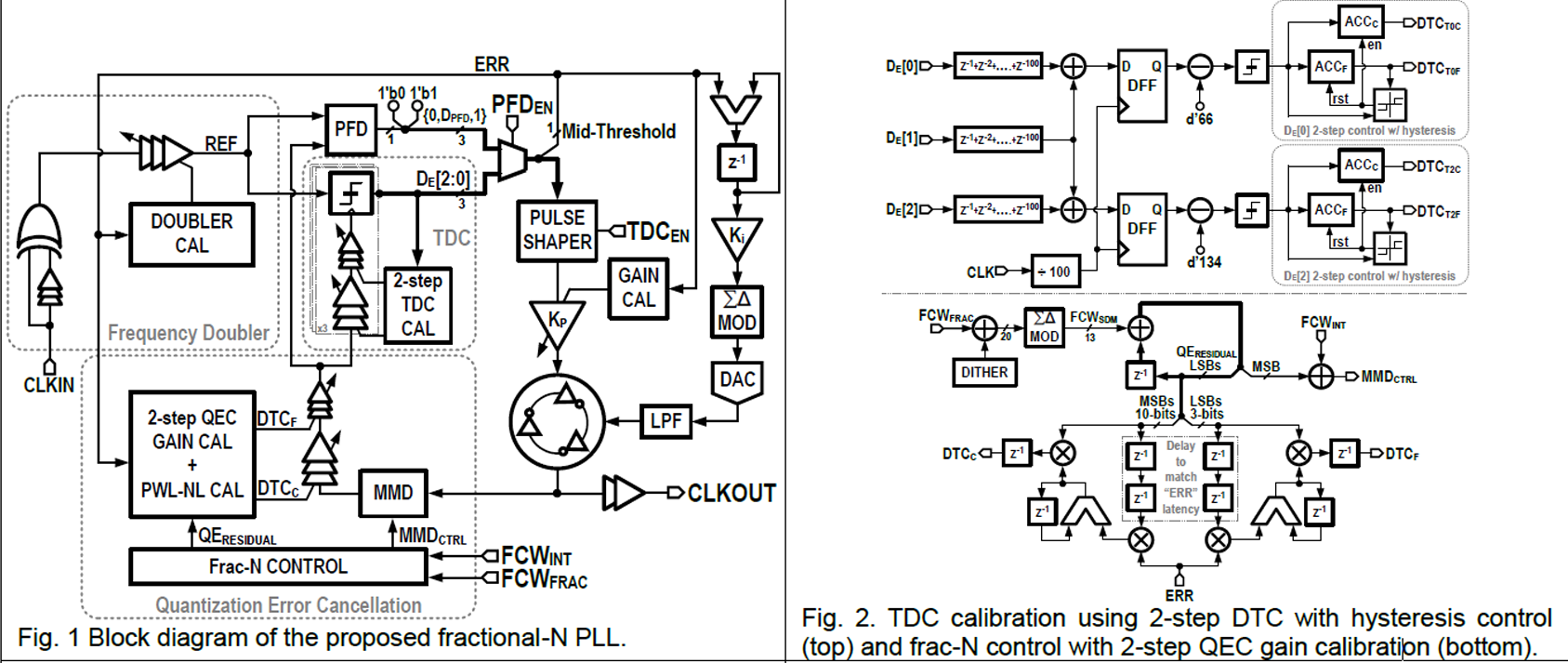 |
| [그림 1] TDC calibration |
|
A 3.2GHz 405fsrms jitter -237.2dB-FoMJIT ring-based fractional-N synthesizer using two-step quantization noise cancellation and piecewise-linear nonlinearity correction[11.2] 은 송수신기가 맞이할 문제 4) 클럭의 위상 노이즈를 해결하는 방법을 제시한다. 본래 발진기는 LC 발진기가 Phase Noise가 작아서 주로 사용되었으나, CMOS 공정을 사용하면서 크기의 제약 때문에 RO(Ring Oscillator)를 대부분 사용한다. RO(Ring Oscillator)는 넓은 튜닝 범위를 제공하고 더 작은 영역을 차지하며 Multi-phase Clock을 제공한다는 점이 장점이지만, 단점으로는 Phase Noise 성능이 좋지 않아서 데이터 속도가 높은 어플리케이션에서는 사용할 수 없다. 이를 해결하기 위한 보통의 방식은 전력 소모량을 키우는 것이기 때문에 매우 비효율적이다. [11.2]의 논문에서는 양자화 오류 제거(QEC)와 DTC(Digital-to-Time Converter) 기반 아키텍처를 사용하여 출력 지터에 대한 기여도를 낮추는 방식을 채택하여 문제를 해결했다는 점이 의미가 있다.
A 4-to-1 240 Gb/s PAM-4 MUX with a 7-tap Mixed-Signal FFE in 55nm BiCMOS[11.3]는 광통신에서 200Gb/s 이상의 데이터 전송을 목표로 한다. 논문에서는 InP 기반으로 만들어진 송신기는 복잡한 신호를 이퀄라이징 하는 기능이 없다는 것을 문제점으로 보았다. 이를 해결하기 위해 BiCMOS 기반 송신기를 사용했으며, 그러므로 더 복잡한 회로를 구성하는 것이 가능했다. 또한 광학 드라이버에 필요한 높은 신호 스윙을 제공했다. 결과적으로 논문에서는 디지털 및 아날로그 지연 구조를 효율적으로 사용하여 55nm BiCMOS 에서7-tap FFE를 통합한 120Gb/s PAM-4 TX를 제시하였다. 논문의 결과값이 기존의 FinFET 솔루션에 비해 두 배의 작동 속도를 보여 주며 FFE 기능이 없는 InP 에서의 속도 및 전력과 거의 일치한다는 점에서 성능이 뛰어난 송신기이다.
A Scalable 32-to-56Gb/s 0.56-to-1.28pJ/b Voltage-Mode VCSEL-Based Optical Transmitter in 28nm CMOS[11.4]는 수직 캐비티 표면 방출 레이저(VCSEL)를 기반으로 하는 Optical communication을 사용한다. 이는 데이터 센터에서 주로 사용되는데, 수십 미터 이상의 데이터를 전송할 수 있기 때문에 가성비가 좋은 방법이다. 하지만 서버의 플랫폼 내부에 Optical 송수신기를 통합하려면 에너지 효율성을 향상시켜야 하고 비선형성을 개선해야 한다. 논문에서는 5) 비선형성 을 개선하면서 56Gb/s의 850nm VCSEL을 구동하는 광학 송신기를 제안한다. 공정은 28nm Bulk CMOS를 사용하였다. 결과적으로, 논문에서 사용한 드라이버는 CMOS로 설계된 드라이버보다 에너지 효율이 2배 좋고, 사용한 면적이 2~4배가 작다는 것이 강점이다.
A 50Gb/s High-Efficiency Si-Photonic Transmitter With Lump-Segmented MZM and Integrated PAM4 CDR[11.5] 에서는 1) 데이터 센터에서 늘어나는 통신 대역폭을 개선하기 위해 실리콘 포토닉스 커뮤니케이션을 사용한다. 이는 고밀도 데이터 센터에 필수적인 고집적 및 저전력을 달성할 수 있는 방법이다. 모든 전기-광 변환 방법 중에서 MZM(Mach-Zehnder Modulator)는 대역폭이 넓고 선형성이 우수하지만 변조 효율이 낮다는 단점을 지녔다. 변조 효율을 개선하기 위해 일반적으로 위상 Shifter를 사용하지만, 내부의 손실 전극은 고주파에서 상당한 감쇠를 발생시킨다는 단점을 여전히 지니고 있다. 논문에서는 여러 개의 Capacitor segment로 구성된 MZM을 사용하여 단점을 개선하였다. 이를 통해 50Gb/s 데이터를 전송할 때, 1.39pJ/bit/dB의 우수한 전력 효율을 달성했다는 점의 의미있다.
 |
|
|
|
| | | |