




IDEC NEWS
반도체 설계분야 최고권위학회 ISSCC! IEEE SSCS Chapter 임원들과 ISSCC TPC 위원들이 세션별로 리뷰합니다.

김 철 우 교수 고려대학교 전기전자공학부
E-mail ckim@korea.ac.kr
IEEE International Solid-State Circuits Conference (ISSCC)는 매년 2월에 25개국 3천여명의 반도체 칩 설계 관련 연구자들이 모여 최신 연구 성과를 발표하고 미래의 반도체 산업과 기술을 논의하는 가장 권위있는 학회이다. 참석자들의 60% 이상이 기업체에서 올 만큼 실제적인 연구 결과들이 주를 이룬다. 지역별로 보면 최근 몇 년간 유럽의 논문이 줄고 극동 지역의 논문이 증가하고 있다. 올해 ISSCC에서 우리나라는 총 24편의 논문을 발표하여 미국 다음으로 2등을 했다. 최근 일본의 약세 대비 중국(마카오와 홍콩 포함)의 성장세가 눈에 띈다.
올해 ISSCC 주제는 “Envisioning the Future”이다. 반도체 회로 및 시스템의 끊임없는 발전이 우리의 일상 생활에 큰 영향을 미치고 있고 우리가 일하는 방식, 소통하는 방식은 물론 사회 생활의 방식도 변화시킨다. 지난 수 십 년간 반도체 기술은 엄청난 속도로 발전해 왔으나 최근 들어 이러한 빠른 발전의 추세는 기술적, 경제적 난관을 직면하고 있다. 이러한 난관을 극복하기 위해 큐비트, 스핀트로닉스, 3D 및 photonic integration등의 새로운 소자 기술 및 인공 지능 및 기계 학습과 같은 새로운 시스템 구현 방법, IoT, 가상 현실, 자율 주행, 로봇 기술 등의 새로운 어플리케이션 등 최신 반도체 회로 설계 기술이 올해 ISSCC에서 소개되었다.
Plenary talk은 Facebook, KAIST, Eindhoven University of Technology, Intel의 전문가들이 발표를 했다. 특히 KAIST의 유회준 교수가 “Intelligence on Silicon: From Deep Neural Network Accelerators to Brain-Mimicking AI-SoCs”라는 주제로 그 동안 KAIST와 칭화대 등에서 진행한 많은 연구 결과를 발표해 주목을 받았다.
IEEE SSCS 서울 챕터 임원들과 IEEE ISSCC TPC 멤버 중심으로 올해 ISSCC에서 발표된 논문들을 주제별로 정리하여 이번 ISSCC를 한 눈에 파악할 수 있도록 했다. 이와 관련하여 5월 이화여대 축제 마지막 금요일에 워크샵을 진행하려고 한다. 매해 IEEE SSCS 서울 챕터에서 주최하는 행사로 ISSCC의 전반적인 흐름을 파악하고, 5월의 아름다운 캠퍼스의 낭만을 즐길 수 있는 행사이니 많은 관심과 참여 부탁드린다. ISSCC 심사위원을 역임하신 분이 강사로 많이 참여하여 좋은 논문 작성을 위한 팁도 기대되니, 향후 ISSCC 투고가 목표인 학생들이 참여하면 도움이 될 것이다.

김 현 식 교수 KAIST 전기및전자공학부
E-mail hyunskim@kaist.ac.kr
Power Management Subcommittee에서는 #8 DC-DC Converters (7편), #15 Power for 5G/Wireless Power/GaN Converters (8편), #27 Energy Harvesting & DC/DC Control Techniques (8편) 세션을 통해 총 23편의 논문이 발표되었다. DC-DC Converter의 경우 전력효율을 높이는 동시에 인덕터 등 외부 수동소자의 크기를 대폭 줄이거나 칩 내부에 완전히 집적하기 위한 연구들이 다수 발표되었다. 특히 인덕터 크기를 줄이기 위해 인덕터와 커패시터를 혼합하여 구성된 새로운 hybrid topology를 제시하는 연구가 이목을 끌었다. 패키지 레벨로 집적된 인덕터를 포함한 14nm CMOS DC-DC converter chip이 발표되어 PMIC의 소형화 및 고집적화가 눈에 띄게 발전하고 있음을 확인하였고, 더불어 inductive DC-DC converter의 최대 전력밀도의 개선 또한 빠르게 진행되고 있었다. 이외에 최근 트렌드를 반영하듯 스마트 자동차, 5G통신, IoT 에너지 하베스팅을 위한 PMIC 연구들이 다수 발표되었다.
![[그림1] 전력변환 효율 및 전력밀도 그래프 (◆: hybrid, ■: SC, ●: inductive buck, *: #8.2논문)](./2019/03/resources/images/sub/01/04_02_01.jpg)
[그림1] 전력변환 효율 및 전력밀도 그래프 (◆: hybrid, ■: SC, ●: inductive buck, *: #8.2논문)
#8.1 Intel에서는 22nm CMOS 공정으로 개발된 flying capacitor multi-level buck converter를 발표하였다. 2개의 flying-capacitor를 사용하는 4-level generator를 활용하여 스위칭 주파수를 높이고 인덕터의 크기를 획기적으로 줄여 (10nH) 작은 면적의 footprint를 실현하였다. 5MHz의 동작주파수에서 최대 10A의 출력과 93.8%의 전력변환 효율, 그리고 198W/cm3의 부피당 전력밀도를 달성하였다. Multi-level converter의 핵심이 되는 flying-capacitor balancing controller 회로의 구체적인 구현내용이 본 발표에서 공개되지 않은 점은 아쉬운 부분이다.
#8.2 UCSD에서는 연속적인 입력전류를 갖는 passive-stacked 3rd-order buck converter를 발표하였다. 전압을 강하하는 buck converter의 특성상 입력전류보다 출력전류가 크게 되는데 출력단에 연결되는 인덕터의 기생 DCR이 큰 출력전류를 만나 전력누수가 발생하는 문제가 있었다. 따라서 높은 효율을 위해 낮은 DCR을 갖는 부피가 큰 인턱터를 사용하는 것이 일반적이다. 본 논문은 하나의 인덕터를 반으로 쪼개 2개를 사용하고 하나의 flying 커패시터와 혼합하여 인덕터 위치를 입력단으로 이동하는 passive-stacked 3rd-order buck (PS3B) 회로구조를 제안하였다. 이러한 구조의 효과는 출력대비 작은 입력전류가 인덕터에 흐르기 때문에 DCR에 의한 전력누수를 줄일 수 있고, 반대로 큰 DCR을 갖는 작은 부피의 인덕터를 사용할 수 있어 전력밀도를 개선할 수 있다. 더불어 종래의 불연속 입력전류가 연속 전류형태로 바뀔 수 있기 때문에 잡음 및 EMI 문제를 개선할 수 있다. 반면, 인덕터를 다수 사용하는 multi-phase buck converter 대비 효율개선이 크지 않고, 향상된 효율이 특정 출력전압(buck 전압비)에서만 유효하다는 점은 본 구조의 한계점으로 보인다. 본 연구는 5mm2 면적의 footprint 크기에 최대 0.7W/mm2 전력밀도를 달성하였다.
#8.3 Univ. of Colorado에서는 USB-C 입력전력으로부터 1s 또는 2s 배터리의 충전을 위한 buck DC-DC converter를 제안하였다. 본 논문에서는 flying-inductor hybrid topology를 제안하여 buck converter 임에도 불구하고 인덕터를 입력단에 위치할 수 있도록 하였다. 따라서 인덕터에는 출력단 대비 적은 입력전류가 흐르기 때문에 인덕터에서의 전력누수를 줄일 수 있고, USB-C 케이블의 기생 인덕턴스를 flying-inductor로 활용하여 온보드에는 인더터 등의 마그네틱 소자 없이 전력 컨버터를 구성할 수 있게 되었다. 입력단의 인덕터는 switched-capacitor (SC) network에 전류를 공급하고, SC network에서는 2개의 flying-capacitor와 스위치 조합을 통해 1s 또는 2s 배터리 충전에 필요한 전압을 출력한다. 본 논문은 1m 길이의 USB 케이블(522nH & 272mΩ)을 활용하여 2.3MHz의 동작속도로 최대 92.4%의 효율을 달성하였다.
#8.4 Washington State Univ. 에서는 65nm CMOS 공정에서 집적된 buck converter를 발표하였다. (#8.2) 및 (#8.3)과 유사하게 인덕터를 입력단으로 이동시키고 flying-capacitor와 조합된 switched-inductor-capacitor (SIC) topology를 제안하였다. 인덕터(0.85nH)와 커패시터(4.82nF) 모두를 포함하는 칩 면적은 0.65mm2에 불과하며, 450MHz의 동작속도에서 78%의 전력효율(최대 전력밀도 730mW/mm2)을 달성하였다. 제안하는 buck topology는 입출력 전압비(VOUT/VIN)가 1/(2-D)로 결정되기 때문에 전압강하의 폭이 크지 않다는 것이 본 연구의 한계점이라고 할 수 있겠다.
#27.1 Fudan Univ.에서는 열전소자(TEG) 에너지 하베스팅을 위한 bipolar-input boost/flyback hybrid converter 논문을 발표하였다. TEG 소자는 각 plate의 온도차(ΔT)에 따라 양전압 또는 음전압이 발생하는데 본 소자로부터 고효율 에너지 수확을 위해서는 인터페이스 회로가 bipolar-input에 대해 모두 대응해야하는 어려움이 있다. 본 논문에서는 TEG에서 양전압 발생시 boost mode로 동작하고, 음전압 발생시 flyback mode로 동작하여 전류 방향을 전환하는 boost/flyback hybrid converter 구조를 제안하였다. 또한 bipolar start-up 회로를 제안하였는데, start-up를 위한 charge-pump 동작시 필요한 clock 신호를 TEG가 음전압일때도 clock을 생성할 수 있도록 하였다. 그 구현 방안은 TEG가 음전압일때 inverter의 양전원은 ground로, 음전원은 TEG의 음전압으로 하여 ring oscillator를 동작시키는 방식이다. 본 논문은 0.18μm CMOS 공정을 이용하여 구현되었으며 VTEG = 0.26V에서 84%, VTEG = -0.3V에서 79%의 효율을 달성하였다.
#27.2 U. Michigan에서는 압전소자(piezoelectric device) 에너지 하베스팅을 위한 Sense-and-Set (SaS) rectifier 회로를 제안하였다. 교류(AC) 전류 입력의 압전 에너지 하베스팅에서 최대전력을 수확하기 위해서는 인터페이스 회로에서 기생 커패시터에 의한 전력누수를 막기위해 임피던스 매칭과 압전소자 전압을 항상 최적으로 유지하는 MPPT(maximum power point tracking) 등의 기술이 필요하다. 종래 연구에서는 bias-flip 등의 테크닉을 이용하여 기생 커패시터에 의한 전력누수는 많이 줄였지만 여전히 MPP 구간이 짧아 최대 전력을 수확하는데 어려움이 존재하였고, full-bridge rectifier (FBR) 구조로 인해 출력전압에 따라 수확 전력량이 많은 차이를 보이는 것이 한계점이었다. 본 논문은 이러한 문제점을 해결하기 위해 인덕터를 사용하여 국부적인 up-down converter 동작으로 압전소자 전압이 항상 MPP 전압을 추종하며 에너지를 수확하는 SaS 방법을 제안하였다. 또한 인덕터를 재사용하여 AC형태의 MPP전압파형을 정밀하게 추정하기위한 센싱회로도 함께 발표되었다. 제안된 rectifier 회로는 연속진동과 충격진동 형태 모두 대응할 수 있으며, 연속진동에서는 FoM 5.41x, 충격진동에서는 FoM 4.59x를 달성하였다. 본 연구는 압전 에너지 하베스팅에서 처음으로 MPPT가 가능한 방법을 제시하여 의미가 있었다.
#27.4 Pennsylvania State Univ.에서는multi-axial human motion에서 에너지 수확을 위한 multi-beam으로 구성된 압전 에너지 하베스팅 인터페이스 회로를 발표하였다. 에너지 하베스팅을 위해 기본적으로 buck-boost 기반의 synchronous electrical charge extraction (SECE) topology를 사용하고 있지만, rectifier 전압이 출력전압보다 높을 때는 비교기와 스위치로 구성된 direct path를 병렬로 연결하여 인덕터를 거치지 않고 rectifier 전압을 출력에 직접 전달하여 효율을 개선하였다(VM-SECE). 본 논문의 에너지 하베스팅 chip은 각 piezo-beam에 대응하는 6개의 채널로 구성되어 있으며, SECE 모드를 위한 인덕터와 power stage는 하나를 공유하는 구성을 갖는다. 350nm 5V CMOS로 구현된 chip은 VM모드로 단독 동작시 95.6%, VM-SECE 모드로 동작시 84.6%의 효율을 달성하였다.

이 정 협 교수 대구경북과학기술원 정보통신융합전공
E-mail jhlee1@dgist.ac.kr
Session 10 Sensor Interfaces
본 세션에서는 혁신적인 결과를 바탕으로 한 4편의 논문이 발표 되었다. 적은 논문 편수에 비해 주제는 다양해서 전력 사용량 측정 시스템, MEMS Accelerometer, 그리고 본 세션의 주요 단골인 온도 센서 주제로 2편 발표 되었다. 발표 기관을 살펴 보면, 앞의 두 논문은 각각 Analog Devices와 Hitachi로 산업체에서 발표하였고 2 편의 온도센서는 이 분야 절대적 강자인 델프트 공대에서 발표하였다. 이번 후기에서는 3편의 논문을 살펴보고자 한다.
#10.2 매우 오랜만에 MEMS Accelerometer 논문을 ISSCC에서 만나는 것 같다. 오일/가스 탐사 시스템이나 기반 시설 모니터링 시스템과 같은 곳에서 매우 높은 민감도를 가지는 Accelerometer를 많이 필요로 한다. 이러한 응용분야에 적합한 본 논문에서 제안하는 MEMS Accelerometer는 17mW 전력 소모로 22ng/√Hz 의 노이즈 성능을 얻어 FOM기준 기존 Accelerometer 대비 10배 이상 성능 향상을 보여준다. 뛰어난 노이즈 성능 획득은 몇가지 주요 기술에 바탕을 두고 있는데 가장 먼저 MEMS 구조에 있다. 제안 하는 MEMS 소자는 Capacitive 타입으로 감지와 서보 제어를 위한 Capacitive센서들을 각각 분리시켰다. 그 결과 Servo-signal leakage를 줄일 수 있었다. 또한 Differential difference detection방법으로 본질적으로 Common-mode noise에 강인한 구조이다. 회로 시스템적으로도 좋은 노이즈 성능을 얻기 위한 노력들이 보인다. 앞서 MEMS 소자가 Servo-signal leakage를 개선하였다고 하였지만 Parasitic mismatch에 의한 영향은 여전히 크다. 이를 줄이기 위해 FIR 필터를 기반으로 한 Digital cancellation 기술을 이용하였다. 또한 1b servo 신호를 만들기 위해 1bit quantizer를 사용하는 대신 Digital bandpass delta-sigma modulator를 이용하였다. 이를 통해 High-order mechanical resonance의 위치에 Notch를 만듦으로써 Noise-shaping된 고주파 Quantization noise들이 Signal band에 주는 영향을 최소화 할 수 있었다. 마지막으로 MEMS를 구동하는 Driver를 Low flicker noise, high voltage DAC 및 voltage reference를 바탕으로 구현함으로써 노이즈 성능을 더욱 개선할 수 있었다.
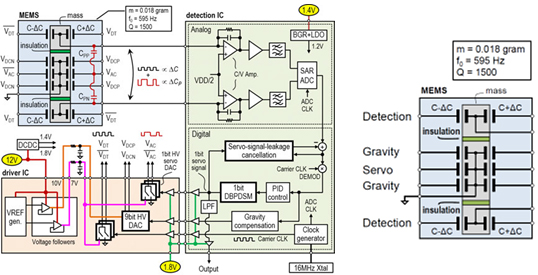
그림 1. #10.2의 MEMS Accelerometer의 블록 다이어그램 및 MEMS 구조
#10.3 델프트 공대에서 발표한 이 논문은 지금까지 많이 발표된 Wien-Bridge 온도 센서를 개선한 것이다. Wien-Bridge 방식은 BJT 방식에 비해 에너지 효율성 및 정확성은 좋은 반면 큰 면적을 차지하는 단점이 있었다. 면적을 줄이기 위해 먼저 기존 구조를 살펴본 결과 전체 면적의 60%를 Cint가 차지하고 있었다. Cint의 크기는 Wien-Bridge센서에서 나오는 전류에 의해 결정되는데 이 전류를 줄이기 위해 센서 저항 크기는 두배로 키우는 동시에 커패시터 크기는 반으로 줄였다. 더불어 Opamp 성능 개선을 통해 첫번째 Integrator의 output swing을 크게 가져감으로써 Cint를 더욱 줄일 수 있었다. 기존 구조에서 면적의 10%를 차지하고 있는 두번째 Integrator는 큰 값의 저항을 Switched-capacitor 구조의 active저항으로 대체함으로써 개선하였다. 이러한 방식들을 통해 본 논문에서 제안하는 구조는 기존 구조 대비 1/6배 작은 면적으로 구현이 가능하였다. 더불어 온도 동작 영역은 76% 더 넓어졌다.
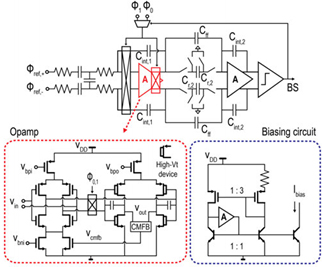
그림 2. #10.3의 제안하는 온도 센서의 블록 다이어그램
#10.4 앞의 #10.3논문과 같은 델프트 공대에서 발표한 이 논문은 같은 그룹이 작년 ISSCC에서 발표한 Wheatstone-bridge 온도 센서 논문을 개선한 것이다. 작년 논문에서 저항을 이용한 온도 센서가 BJT를 사용한 온도 센서보다 더 높은 Resolution과 Energy efficiency를 얻을 수 있는 장점이 있는 반면 면적이 늘어나는 단점이 있어 이를 개선하는 방법을 제안하였고 아래 그림에서 보여준다. 그 구조는 보여주듯이 Multi-bit Quantizer+DWA와 Multi-bit DAC를 바탕으로 한 Delta-sigma modulator 이다. 이 온도 센서는 0.25mm2의 면적으로 구현이 가능하였고 저항을 기반으로 한 온도센서 중 가장 좋은 Resolution FOM인 32fJ∙K2을 얻었다. 이번 #10.4논문은 이전 논문에서 복잡하고 큰 면적을 차지하는 Multi-bit quantizer + DWA를 간단한 방법이지만 같은 효과를 기대할 수 있는 1bit quantizer + FIR-DAC으로 대체함으로써 성능을 개선할 수 있었다. 그 결과 면적은 작년 논문 대비 1/2배 작은 면적으로 구현이 가능하였고 FOM은 20fJ∙K2을 얻어 작년의 최고 성능을 갱신하였다.
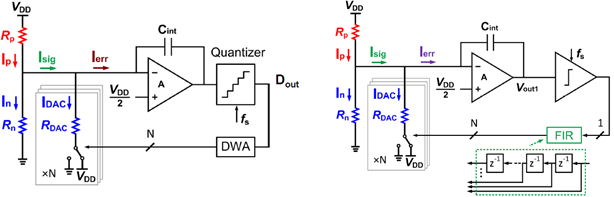
그림 3. 작년 ISSCC에서 발표된 Wheatstone Bridge 온도 센서와 #10.4에서 제안하는 온도센서

배 준 성 교수 강원대학교 전기전자공학과
연구분야 Biomedical Circuits E-mail baej@kangwon.ac.kr
Biomedical Systems 분야는 Session 11 : Diagnostics 와 Session 22 : Physiological Monitoring을 통해 각각 5편, 8편으로 총 13편의 논문이 발표되었다. 해당 분야는 기업체 보다는 학교 및 연구소 주도를 통해 연구되고 있는 분야로 총 13편의 논문 중 12편을 학교 및 연구소에서 발표하였고, 1편은 바이오센서 제작 업체에서 발표하였다. 특히 Biomedical Systems는 한국에서 강세를 보여온 분야로써 이번 년도에도 KAIST, 연세대, KIST에서 5편의 논문을 발표하였다. 해당 분야는 Biomedical 응용에 적합하고 최적화된 반도체 칩을 제작하여 In-vitro 혹은 In-vivo 측정을 통한 검증을 요구하고 있어 다양한 기관들의 협업이 활발하게 이루어지고 있음을 볼 수가 있었다.
# Session 11 : Diagnostics
Session 11에서는 의학적 진단에 활용이 가능한 다양한 종류의 바이오센서, 신경 세포 이미징, 초음파 이미징을 위한 CMOS Chip의 개발에 대한 내용이 발표되었다. 이 가운데 KAIST [11.1] 에서는 심내 초음파 영상 획득을 위해 5MHz의 초음파 신호 파장에 크기를 맞춘 250um x 250um의 픽셀 안에 송신기, 수신기, ADC를 모두 집적한 고집적 초음파 ASIC을 발표하였다 (그림 1).
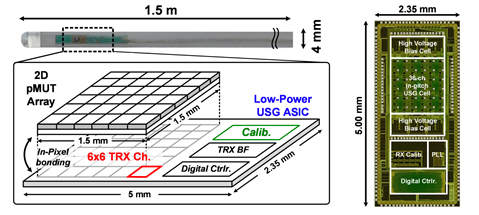
그림 1. 심내초음파 시스템
pMUT Transducer를 통해 기존의 PZT, cMUT 방식의 Transducer에 비해 낮은 전압으로 Transducer를 구동할 수 있게 하여 Standard CMOS Process로 전체 ASIC 구현이 가능하게 하고 pMUT의 process variation은 채널 별로 calibration이 가능하도록 하여 선명한 영상 획득이 가능함을 보여주었다.
InSilixa Inc. [11.2] 와 UC San Diego [11.4]에서는 각각 Electrochemical, Magneto-resistive Sensor ASIC을 발표하였다. 피(blood) 성분 분석, DNA Sequencing, Point of Care (PoC) 응용에 활용이 가능함을 보여주었는데 이와 같은 Bio-sensing ASIC은 baseline 신호 대비 측정하고자 하는 신호의 크기가 상대적으로 미약하게 측정이 되므로 AFE 회로의 Dynamic Range를 최대한 확보하기 위해 SDM을 통해 신호를 얻는다거나 Replica Sensor를 통해 baseline 신호를 제거하는 회로 구조가 발표되었다.
특히, 연세대 [11.3]는 최초로 CMOS ASIC을 통해 혈관내의 VEGF 농도를 검출하여 초기의 암 진단에 활용할 수 있는 바이오 센서 플랫폼을 발표하였다. 마이크로 니들에 결합된 VEGF의 양에 따라 변화하는 Capacitance의 변화량을 미세하게 검출하기 위한 Two Step (Coarse ADC + Fine SDM) Capacitance 검출 회로 구조를 제안하여 15fM 수준의 VEGF 농도 검출이 가능함을 보여주었다.
KIST [11.5]에서는 Brain Activity를 고해상도로 관찰할 수 있도록 이미지 센서 기반의 Neural Imaging Probe를 발표하였다 (그림 2).
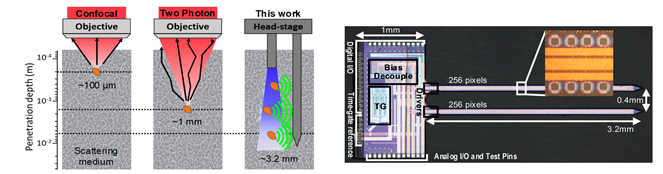
그림 2. Neural Imaging Probe
기존의 전극을 활용한 전기적인 방식과 렌즈를 활용한 광학적 방식의 한계를 뛰어넘기 위해 256개의 SPAD (single-photon-avalanche-diode)를 활용하여 40Hz의 낮은 DCR을 확보하고 SPAD를 25um 피치로 배열하여 angle sensitive grating을 통해 렌즈 없이도 3k의 프레임의 이미지 데이터를 얻을 수 있음을 보여주었다.
# Session 22 : Physiological Monitoring
Session 22에서는 wearable 및 implantable 응용을 위한 다양한 ASIC 기술이 발표되었다. IMEC [22.1] 에서는 다양한 생체 신호 획득을 위해 자신들이 기존에 개발했던 플랫폼에 추가로 BLE 까지 집적된 Single Chip SoC를 발표하였고, UC San Diego [22.2]는 Motion Artifact에 강인한 ExG 신호 검출 Active Electrode platform을 발표하였다. KAIST [22.3]에서는 bio-impedance획득을 위해 최초로 10uW 이하의 전력 소모를 갖는 impedance sensor IC를, KAIST [22.4] 에서는 two electrode ECG 검출을 위해 common-mode interference에 강인한 증폭기 구조를 발표하였다. IMEC [22.5]에서는 [22.3]과 같이 bio-impedance 센싱 IC를 발표하였는데 기존 tetra polar 방식과 달리 two electrode를 통한 방식을 제안하고 two electrode 동작에서 생길 수 있는 추가적인 노이즈 성분을 baseline cancellation과 reference current noise cancellation을 통해 효과적으로 줄여주었다. Shanghai Jiao Tong University [22.6]은 Impedance Tomography용 SoC를 발표하였는데 Frequency Division Multiplexing을 통하여 동시에 다채널을 동작 시켜서 기존대비 Throughput을 10배 이상 향상 시켜주었다. National Cheng Kung University [22.7]은 EEG 신호 검출, 신호 처리, 전기적 자극 및 광학적 자극에 추가로 무선 인터페이스 기능까지 집적 시킨 고집적 SoC를 발표하였고, 동물 실험을 통해 간질 반응이 억제됨을 보여주었다. University of Toronto [22.8]에서는 두 개의 고주파 신호를 통해 저주파 신호 자극을 할 수 있도록 하는 Temporal Interference Stimulation 기능과 Stimulation Artifact를 빠르게 회복할 수 있는 64채널 recording 회로, machine learning 기반 brain state classifier 기능이 집적된 neuro-stimulator ASIC을 발표하였다.
전체적으로 지난 년도와 비교하였을 때, 새로운 응용을 구현한 발표는 없었고 기존에 개발된 시스템에 집적도를 높이거나 특정 성능을 개선하는 내용들이 주로 발표되었다. 해당 세션의 8편의 논문 중에서는 IMEC의 “Battery-Powered Single-Chip SoC with BLE for Multi-modal Vital Sign Health Patches” 발표가 큰 주목을 받았는데 기존 Biomedical SoC는 상용화와는 거리가 먼 Proof of Concept이나 아이디어 검증 수준에서 개발이 된 반면 해당 논문은 55nm 공정으로 Cortex M4 계열의 프로세서와 BLE 4.2, 그리고 검증된 다양한 종류의 센서가 모두 집적되어 해당 분야의 세계 최고 수준의 기술 수준과 상용화 가능성을 보여주었기 때문으로 보인다. Biomedical Systems 분야는 상대적으로 회사의 관심이 적은 분야이지만 현재 개발되고 있는 유망한 기술들이 상용화 수준으로 적용이 되어 기업체의 활발한 참여를 기대해 본다.
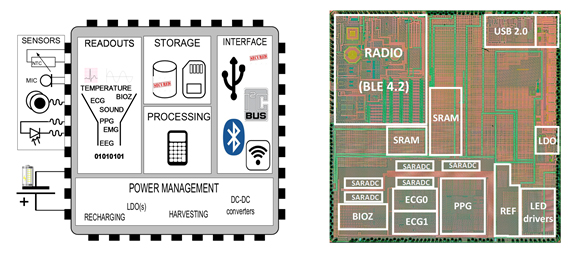
그림 3. Single Chip SoC for Multi-modal Vital Sign Health Platform

최 재 혁 교수 울산과기원 (UNIST) 전기전자컴퓨터공학부
연구분야 RF/Analog IC Design E-mail jaehyouk@unist.ac.kr
ISSCC2019에서 Frequency generation 관련 기술은 세 개의 세션에서 (Session 16, 26, 30) 총 14 개의 논문을 통하여 소개되었다. 몇 년간 이 분야 논문 발표는 저전력 구현과 고성능 구조 개발의 두 가지 방향에서 이루어졌는데, 올해는 특히 고성능을 목표로 하는 두 번째 방향에 관한 연구가 두드러졌다. 5G 시대가 다가오면서 유무선 통신시스템이 초고속 데이터 통신을 목표로 하고 있으며, 이러한 통신시스템에서 요구하는 고주파, 초저잡음 신호 생성을 위한 연구가 주류가 되었기 때문이다. 구조적인 측면에서는 올해도 Injection-locking 기반 clock generator와 Sub-sampling 기반 PLL 구조를 발전시키는 연구들이 많이 소개되었으며, 특히 Sub-sampling PLL의 근본적인 문제들을 해결하려는 노력들이 눈에 띄었다.
Session 16 “Frequency Synthesizers” 세션에서는 총 9개의 PLL 논문이 소개되었다. #16.1 논문은 Sub-sampling 구조를 이용하여 높은 FoM을 달성할 수 있는 2.4GHz 저전력 PLL 구조를 발표하였다. 이 PLL은 Locking 이 이뤄지는 조건에 따라 Sub-sampling과 Sampling 동작 사이에서 switching이 이뤄지며, 이를 통하여 Sub-sampling 구조의 dynamic range 제한 문제를 해결하였다. #16.2 논문은 Cascading 구조를 이용하여 100fsRMS 미만의 초저잡음 성능을 획득한 PLL을 소개하였다. 두 번째 단의 injection-locking 기반 주파수 체배기는 첫 번째 단에서 생성된 GHz 대역 신호의 주파수를 28 – 30GHz 대역의 mmW 신호로 증폭시키는 역할을 수행하는데, 이 주파수 체배기의 lock range가 매우 넓기 때문에, 주파수 증가시에도 노이즈 성능열화가 나타나지 않는다. 첫 번째 단에서는 digital 기반의 sub-sampling PLL이 이용되었다. 제안된 구조는 기존의 digital 기반의 sub-sampling PLL에서 사용되었던 multi-bit ADC 대신 3개의 parallel 1-bit voltage quantizer를 사용하여 quantization 노이즈를 효과적으로 제거하였다. #16.6는 mixer를 이용하여 fractional resolution을 구현하는 고전적인 heterodyne 방식의 주파수합성기를 sub-sampling PLL, bang-bang PLL 등 최근 인기를 얻고 있는 PLL 구조를 사용하여 구현하였다. 주파수 Plan을 전략적으로 사용하여 높은 FoM과 좋은 spur 특성을 달성하는 동시에, 3개의 PLL 루프 사이의 pulling 문제를 해결하였으나, 시스템의 면적과 복잡도 증가라는 구조적인 한계를 가지고 있다. #16.7 논문은 최근 몇 년 새 지속적으로 발표되고 있는, BBPLL을 기반으로 넓은 bandwidth를 확보하여 저잡음 성능을 획득할 수 있는 구조를 발표하였다. 넓은 bandwidth를 확보하는 동시에 fractional resolution을 확보하기 위하여 BBPD 앞에서 DTC를 이용하여 phase를 accumulation하는 방식을 채택하였다. 이 논문의 핵심은 BBPD의 rising edge 뿐 아니라 falling edge도 사용하여, DTC 구현에 필요한 range를 반으로 줄이는 것이다. #16.4와 #16.9 논문은 fractional-N spur를 줄일 수 있는 새로운 기술을 발표하였다. 특히 #16.9 논문은 DSM Quantization 노이즈 에너지의 분포를 재분배하는 probability mass redistributor (PMR) 기술을 이용하였다. 기존의 DSM PLL에서 Gaussian 분포를 따르는 DSM 노이즈가 (charge pump 등에 의한) 비선형 함수를 통과할 때 fractional spur의 level이 높아지며 특성이 열화 되는 문제를 해결하고자 하였으며, 이를 위하여 의도적으로 DSM 노이즈의 분포를 reshape하는 방식을 제안하였다. PLL은 180nm SiGe BiCMOS을 사용하여 제작되었는데, 전구간에서 -80dBc 미만의 in-band fractional spur를 달성하였다.
Session 26 “Frequency Generation & Interference Mitigation” 세션에서는 1개의 PLL과 3개의 VCO 논문이 소개되었다. #26.1은 28nm CMOS 공정을 이용하여 16GHz 주파수 대역에서 광대역 chirping FMCW를 구현하였다. 역시 subsampling PLL을 이용하여 고주파 신호를 생성하고 DTC를 이용하여 fractional resolution을 구현하였으며, 30us의 chirping speed와 1.5GHz의 bandwidth를 달성하였다. #26.2와 #26.3 논문은 5G 시스템을 타겟으로 하여 mmW 대역에서 초저잡음 특성과 넓은 tuning range를 달성할 수 있는 LC VCO 회로를 제안하였다. #26.2 논문은 공진 주파수의 1, 2, 3 번째 하모닉에서 공진조건을 가지는 LC tank를 transformer를 이용하여 구현하였으며, 발진 조건을 하나의 common-mode capacitor만을 이용하여 tuning하였다. #26.3 논문은 4-port coupled inductor를 이용하여 dual-mode resonator를 만들었으며, 이를 이용하여 25 – 39GHz의 광대역 주파수를 생성하였다. #26.5 논문은 IoT application을 타겟으로 하였으며, supply voltage가 0.1V 이하로 내려갈 시에도 저잡음 특성을 유지할 수 있는 4 – 5 GHz 대역의 LC VCO를 제안하였다. 회로는 22nm FDSOI 공정을 이용하여 제작되었으며, 197dBc/Hz의 peak FOM과 40MHz/V의 supply pushing을 보였다.
Session 30 “Advanced Wireline Techniques” 세션은 다양한 high-speed link 시스템의 논문이 발표되었는데 그 중에서 2개의 PLL 논문이 building block 레벨의 최신기술로서 소개되었다. #30.8 논문은 0.65V supply voltage에서 동작 가능한 sub-sampling PLL을 소개하였다. #30.9 논문은 낮은 잡음 성능과 낮은 레퍼런스 성능을 동시에 획득할 수 있는 ring VCO 기반의 injection-locking clock multiplier를 소개하였다. 이 논문은 reference spur를 발생시키는 주 요인을 세 가지로 분석하였으며, orthogonal한 특성을 갖는 triple-point calibration을 수행하여 이 세 가지의 원인을 모두 제거하는 방법을 제안하였다. 이를 통하여 140fsRMS 지터 성능과 -70dBc 미만의 스퍼 성능을 획득하였으며, 이를 통하여 ring VCO를 기반으로 작은 실리콘 면적을 사용하면서도 큰 면적을 차지하는 LC VCO를 사용하는 PLL의 사용 시에 준하는 지터 및 스퍼 특성을 획득하는 것이 가능함을 보였다.

김 성 진 교수 UNIST 전기전자컴퓨터공학부
E-mail kimsj@unist.ac.kr
Image Sensors에서는 8개의 논문이 발표되었는데 예년과 달리 75%의 논문이 학교의 연구 결과로 기존의 모바일용 카메라 센서의 성능 향상 논문에 비해 참신한 아이디어들을 볼 수 있었다. 특히 에너지 효율을 높이기 위해 복잡한 영상 프로세싱 없이 센서 단에서 다양한 기능을 저전력으로 구동하는 연구들이 많이 발표되었으며 지속적으로 관심을 받고 있는 Single Photon Avalanche Diode(SPAD) 관련 센서 논문도 2편이 발표되었다. 이번 후기를 통해 6개의 논문에 대해 간략하게 살펴보고자 한다.
#5.1은 SmartSens Technology에서 발표한 논문으로 기존에 연구되었던 기술들을 3D stacking 공정과 접목하여 다양한 기능을 이미지 센서 내에서 구현하였다. 설계된 기술들을 살펴보면 voltage domain global shutter를 위한 아날로그 메모리를 포토다이오드 위에 적층하여 픽셀의 크기를 작게 유지하면서 charge domain의 leakage 문제를 해결하였으며, TX gate의 전압을 조절하여 photon transfer curve를 비선형적으로 변경함으로써 dynamic range를 넓혔다. 이 기술은 널리 알려졌으나 TX의 Vth에 의한 fixed-pattern noise가 심하게 나타나는 단점이 있는데 Vth를 읽어내어 보정해 주었다. 또한 rolling shutter로도 동작할 수 있고 하단 wafer에 image processor를 집적하여 binarization이나 depth map 추출이 가능하다. 3D stacking 공정 덕분에 센서 단이 점차 더 많은 functionality를 가지게 될 것으로 전망되는데 이에 대한 훌륭한 예제로 보인다.
#5.2는 University of Michigan에서 발표하였는데 일반적으로 많이 사용되는 Single-slope(SS) ADC를 SAR ADC로 바꾸어 에너지 효율을 높였다. 제안된 SAR ADC는 주저자가 전에 발표했던 charge injection 방식으로 이미지 센서에 맞게 2-step 구조로 해상도를 향상시키고 multiple sampling까지 적용할 수 있도록 개선하였다. 저전력 동작 인식 기능도 추가하여 재미있는 데모를 보여주었으나 ADC와 디지털 회로의 크기가 센서보다 상당히 큰 점이 아쉽다.
#5.3은 Stanford University의 논문으로 상기 두 논문과 같이 저전력으로 센서 단에서 물체를 인식하기 위한 log-gradient 기법을 제안하였다. 적은 bit으로 넓은 dynamic range를 다루기 위해 영상으로부터 Histogram of Oriented Gradient(HOG)를 추출하여 log로 표현하였으며 ratio-to-digital converter(RDC)로 구현하였다. 그림 1에서 보듯이 Linear 방식에 비해 1/3 수준의 bit만 사용하면서도 유사한 수준의 물체 인식이 가능하며 빛의 세기에 영향을 덜 받는다. 또한 데이터량을 25배까지 줄일 수 있는 장점이 있어 always-on 센서에 적합하다.
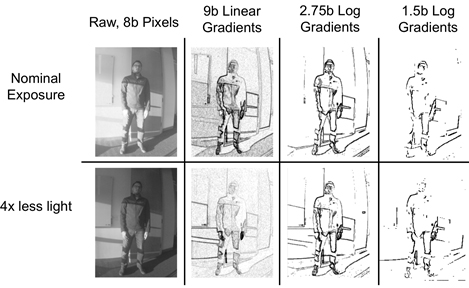
그림 1. 일반 영상과 log-gradient HOG 영상 비교
#5.4에서는 연세대학교에서 SS ADC의 근본적인 문제인 속도를 획기적으로 향상시키는 time stretcher 구조를 발표하였다. SS ADC의 속도를 높이려면 클럭 주파수를 올려야 하므로 이로 인해 전력 소모가 급격하게 늘어난다. Time stretcher 구조는 그림 2와 같이 기본적으로 2-step 구조로 6-b coarse 변환 후 클럭의 남은 시간을 16배로 늘려서 4-b fine 변환을 한다. 동일한 전류원에 캐패시터의 크기를 늘리는 간단하면서도 매우 효율적인 시간 증폭기를 구현하였으며 기존의 고속 센서에 비해 20% 수준의 전력만을 사용하였다.
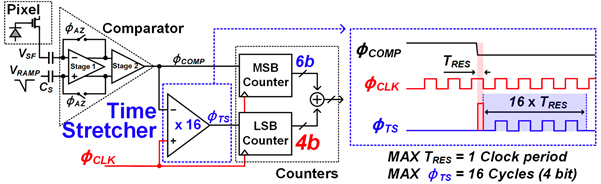
그림 2. Time stretcher 기반 SS ADC
#5.5은 University of Toronto에서 발표한 논문으로 coded exposure를 카메라 시스템 상이 아닌 센서 내부에서 구현한 재미있는 아이디어를 보여주었다. 픽셀 내부에 두 개의 tap과 메모리를 두고 code에 따라 charge를 원하는 tap으로 보냄으로써 하나의 센서로부터 두 장의 영상을 얻어낸다. Code에 따라 다양한 기능을 수행할 수 있으며 structured light을 이용한 disparity map을 시연하였다. Time-of-flight(ToF) 픽셀에서 주로 사용하는 2 tap 구조를 다른 방식으로 활용한 점이 인상적이었으며 발전 가능성이 커 보인다.
#5.7은 University of Edinburgh에서 STMicro와 함께 오랜 기간 연구해오고 있는 SPAD 기반 ToF 센서에 관한 논문이다. SPAD는 감도가 매우 높으면서 출력이 시간 축에 표현되는 디지털 pulse이므로 dynamic range도 매우 높은 장점이 있으나 ToF를 측정하기 위해서는 정교한 time-to-digital converter(TDC)가 필요하고 데이터양이 1 Pb/s에 달할 정도로 큰 단점이 있다. 이 논문에서는 3D stacking 공정을 활용하여 TDC를 SPAD와 적층하여 구현하면서 TDC의 많은 데이터를 칩 내부에서 히스토그램 화하여 줄일 수 있었다. TDC 등의 회로는 기존과 유사하나 작은 픽셀에 TDC와 히스토그래밍을 집적하여 어레이 형태의 flash LiDAR 구현 가능성을 보여주었다.

채 영 철 교수 연세대 전기전자공학과
연구분야 Mixed-Signal ICE-mail ychae@yonsei.ac.kr
Analog Techniques (Session 3) 에서는 Audio DAC, Capacitance-to-digital Converter, Amplifier, X-tal Oscillator, References 등의 8편의 논문이 발표되었으며, Analog building block 을 구성하는 새로운 기법이 다양하게 소개되었다. 특히 IoT 기기의 증가로 인해서 이에 사용되는 X-tal Oscillator 의 관심이 증가되어 3편의 논문이 발표된 것이 특징으로 볼 수 있다.
첫 번째 논문 (MediaTek) 은 Audio DAC 을 발표하였는데, 크게 3가지 technique 을 제안하였다. 3가지 기법은 Reference noise 저감 기법, frequency compensation 기법, 저항 parasitic 으로 인한 선형성 저하를 보상하는 기법 이다. 이를 통해서 -105dBc 의 THD+N 와 2.8Vpp swing 그리고 120dB 의 dynamic range 를 확보하였다.
두번째 논문 (UT Austin) 은 에너지 효율이 매우 높은 capacitance-to-digital converter (CDC) 를 제안하였다. 해당 CDC 는 Coarse 는 SAR ADC 를 fine 은 VCO 기반의 ADC 를 사용하였다. 이를 통해 빠른 속도와 높은 해상도를 동시에 달성해 16fJ/conv-step 의 높은 에너지 효율을 달성하였다.
![[그림1] 제안하는 Two-step CDC: Paper 18.2](./2019/03/resources/images/sub/01/04_07_01.jpg)
[그림1] 제안하는 Two-step CDC: Paper 18.2
세번째 논문 (TU Delft)은 Voltage buffer 용 증폭기로 ADC 등에 다양한 형태로 사용되는 buffer 를 입력 leakage current 를 최소화 할 수 있는 Auto-zeroed (AZ) Stabilization 기법을 도입한 증폭기를 제안하였다. 해당 논문은 전년도에 발표한 논문의 개선된 버전으로 AZ 시에 발생하는 noise folding 을 저감하기 위해 Chopping 기법을 추가로 제안하였으며, 이 기법을 통해 AZ amplifier 의 노이즈의 이론적 한계인 2 x white noise 를 달성하였다.
네번째 논문은 (UCLA) 는 32kHz crystal oscillator 를 0.55nW 만을 사용해 구현하였다. 해당 논문은 crystal oscillator 에 사용되는 amplifier 를 frequency translation 을 이용해 near DC에만 동작해도 무방하게 구현하여 매우 낮은 에너지소모만 가지고 동작이 가능하게 만들었다. 더불어 Allan deviation floor 역시 14ppb 에 해당하는 매우 우수한 stability 를 구현하였다.
![[그림2] Crystal Oscillator Based on a DC-Only Sustaining Amplifier: Paper 18.4](./2019/03/resources/images/sub/01/04_07_02.jpg)
[그림2] Crystal Oscillator Based on a DC-Only Sustaining Amplifier: Paper 18.4
다섯째 논문 (UIUC) 와 여섯째 논문 (Dialog semiconductor)은 Crystal oscillator에 필요한fast startup 을 달성하기 위한 기법을 제안한 것으로 UIUC 에서 제안한 논문은 PLL을 이용하여 precise injection 을 Two-step 형태로 구현하여 30배 빠른 startup이 가능하게 만들어 20us startup time 을 industrial temperature range (-40~80˚C)에서 달성하였다. 여섯째 논문은 32MHz 의 relaxation oscillator 를 사용하여 injection 시켜 startup time 을 경감 시켰다.
일곱째 논문 (TSMC)와 여덟째 논문 (Postech)은 voltage reference 논문으로 TSMC 는 처음으로 12nm 공정을 이용한 BGR 을 발표하였다. current-controlled feedback loop 를 이용하여 current mirror 의 matching condition 을 완화하였고 이를 통해 sub-1V (0.7V supply) 동작과 더불어 2.35% 의 3σ inaccuracy 를 달성하였다. Postech 은 BJT와 MOS 를 결합한 hybrid BGR 을 제안하였으며, 이는 process-dependent compensation 기법을 처음으로 제안하였다. 해당 연구는 모든 corner 에서 0.52% 만의 variation 을 가지는 매우 우수한 성능을 보였다.

류 승 탁 교수 KAIST 전기 및 전자공학부
E-mail stryu@kaist.ac.kr
Data Converters 분과에서는 두 세션에 걸쳐 총 14편의 논문이 발표되었다. 기술적인 아이디어들에서도 흥미로운 것들이 많았고, 중화권 (대만 포함)의 강세도 눈에 띄었다 (University of Macau 4편, MediaTek 3편).
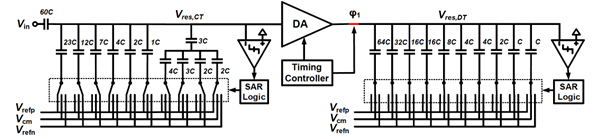
Session 3에서는 11 ~ 16bit 해상도와 2MS/s ~ 5GS/s 변환속도를 갖는 7편의 Nyquist-rate Analog-to-Digital Converter (ADC)들이 발표되었는데, 이러한 높은 성능은 주로 파이프라인 구조를 이용함으로써 달성하였다. 지난 10년 남짓의 기간 동안 Successive Approximation Register (SAR) ADC를 기반으로 한 저전력화 기술과 time-interleaving 구조를 이용한 고속화 기술이 매우 발전되어 왔으나, SAR 구조에 의한 ADC의 제한된 변환속도와 해상도가 점차 한계를 보이고 있어 최근에 파이프라인 구조 적용의 필요성이 다시 공감을 얻는 것으로 보인다. 파이프라인 구조의 가장 큰 부담인 residue amplifier에 의한 전력소모 문제가 open-loop gm-R 구조, dynamic amplifier, ring-amplifier 등의 회로기술로 극복되었으며, 고해상도 구현과 process-voltage-temperature (PVT) 에 둔감한 회로 구현을 위한 calibration 기술이 광범위하게 사용되었다.
IMEC에서는 Ring amplifier를 이용한 ADC 두 편을 발표하였는데, (#3.1)에서는 1.5b/stage 구조의 pipelined ADC 4 채널을 time-interleaving (TI)하여 3.2GS/s 변환속도를 갖는 16nm 10ENOB ADC를 구현하였다. Residue 증폭기로 사용된 ring amplifier의 비선형성에 의한 signal-to-distortion ratio를 background tracking하기 위해, 복잡한 ADC의 사용 없이, single-comparator stochastic ADC를 이용하여 summing node 전압을 출력코드별로 모니터링하는 기법을 제안하였다. 그러나, error estimator의 결과를 이용한 실제 feedback control 부분은 구현되지 않았다. (#3.6)에서는 동일한 저자가 (#3.1)과 유사한 ADC 구조를 이용하되, event-driven asynchronous pipelined ADC를 구현했는데, ring amplifier의 settling done (i.e. event driven)을 센스하기 위해서 단순 logic 회로를 이용하여 3rd stage의 입력 전압을 monitoring하는 기법을 제안하였다. Asynchronous pipelining 기법의 사용이 처음은 아니나 (ex: Xilinx, ISSCC 2017), 저전력 ring amplifier의 특성과 매우 잘 맞는 기술이라는 면에서 주목할 만 하다고 생각된다. 16nm 공정에서 구현된 단일 채널 11b 600MS/s ADC는 6mW의 전력소모와 60dB의 SNDR을 보였다.
(#3.2) University of Macau에서는 pipelined SAR ADC 구조를 이용하여 28nm 단일 채널 12b 1GS/s ADC를 구현하였다. 고속 residue amplification을 위해서 open-loop gm-R 구조의 증폭기를 구현하였는데, residue의 선형성 확보를 위해 flipped voltage follower (FVF)형태의 입력단을 이용하였다. 한편, open-loop gm-R 증폭기의 온도변화에 따른 성능의 변화를 줄이기 위한 temperature compensation 회로를 제안하였는데, 정작 그 회로를 위해 필요한 바이어스가 구현되지 않은 것은 기술의 완성도 측면에서 단점이라 하겠다. 구현된 ADC는 60dB 이상의 SNDR을 얻었고, 7.6mW의 전력소모를 보였다.
(#3.3) KU Leuven에서는 dynamic amplifier를 이용한 12b pipelined-SAR ADC를 구현하였고, 8채널 TI 구조를 이용하여 5GS/s의 변환속도를 얻었다. Input buffer없이도 6GHz의 대역폭을 얻기 위해서 sampling network을 주의 깊게 설계하였다. 특히, input과 clock routing에 별도의 shield line을 두지 않음으로써 parasitic을 줄이면서도, intertwisted Y-tree 구조를 제안하여 input과 clock의 차동신호가 동일한 coupling을 갖도록 하여 서로의 coupling 영향을 제거하도록 하였다. 구현된 28nm ADC는 2.4GHz 입력에서 58.5dB의 SNDR을 얻었고 158.6mW를 소모하였다.
(#3.4) University of Texas Austin에서는 two-stage pipelined-SAR ADC를 구현함에 있어서 두 stage간의 decision redundancy를 이용하여 first stage가 sampling없이 MSBs를 얻는 continuous-time pipelined-SAR ADC를 제안하여 kT/C noise의 영향을 대폭 줄였다. 40nm 공정을 이용하여 13b 2MS/s를 구현하여 73.5dB의 최대 SNDR을 얻었고 25.2uW의 전력을 소모하였다.
#3.4: Continuous-Time (first stage) Pipelined-SAR.
(#3.5) University of Macau에서는 또 다른 논문으로 two-step TDC를 이용한 20MS/s 13b SAR ADC를 제안하였다. 65nm 공정에서 제작된 ADC는 0.6V 전원을 사용하여 1.4fJ/conversion-step의 우수한 Walden FoM을 얻었다.
(#3.7) Oregon State University에서는 ring amplifier를 residue 증폭기로 사용한 180um 16b 15MS/s two-step SAR ADC를 선보였고, 10mW의 전력을 소모하면서 91dB의 높은 SNDR을 달성하였다. 16b 선형성 구현을 위해 최종 출력에 bit weight correction 기능을 넣었다. Ring amplifier를 구현함에 있어서 높은 slew current와 stable한 동작 및 low bias stability를 동시에 달성하기 위해서 HVT transistor와 LVT transistor를 병렬로 갖는 출력단을 구성한 것이 주요 아이디어이다.
Session 20에서는 Noise-shaping기법과 VCO-based ADC들 7편이 소개되었는데, 25MHz ~ 2.5GHz의 신호대역폭과 45.2dB ~ 76.6dB의 SNDR 수준의 성능을 보였다. 특히, SAR ADC를 이용한 noise-shaping (NS) 기법은 SAR ADC의 저전력 특성을 최대한 활용하면서도 높은 해상도를 얻을 수 있어 근래에 매우 활발하게 연구되고 있는 분야이다.
(#20.1) KU Leuven에서 multi-phase VCO를 이용한 ADC 구조에서 많은 개수의 고속 counter 부담과 metastability 문제를 해결할 수 있는 기법을 제안하여 28nm time-interleaved VCO-based ADC를 구현하였고, 5GS/s의 Nyquist입력에 대해서 45.2dB의 SNDR을 얻고 22.7mW의 전력을 소모하였다.
(#20.2) MediaTek에서는 저잡음 구현을 위해 single input pair만을 갖는 비교기를 사용하면서도 passive noise coupling이 가능한 NS SAR ADC를 제안하였다. 기존 passive NS 기법들이 summing 기능을 구현하기 위해서 추가적인 잡음 문제에도 불구하고 최소 two input pair를 갖는 비교기를 사용하였던 면에 착안하여, 제안된 기술에서는 CDAC의 차동 residue 전압들을 back-to-back capacitors로 샘플하여 CDAC과 직렬 연결함으로써 추가의 input pair 없이 addition기능을 구현할 수 있도록 하였다. 14nm FinFET 공정에서 제작되었고, 40MHz 대역폭에 대해 66.6dB의 SNDR을 얻었고 1.25mW의 전력을 소모하였다.
(#20.3) University of Michigan에서는 NS SAR ADC를 이용하여 time-interleaving을 시도한 매우 흥미로운 구조를 선보였다. SAR ADC의 decision step들 사이에 적용된 redundancy를 활용하여 decision 과정 중간 중간에 다른 채널들로부터의 residue들을 coupling 시키도록 했는데, 4 채널 TI를 이용하여 4차 noise shaping을 구현하였다. 특히나, 기존 Nyquist TI ADC 구현에서 channel mismatch 문제가 큰 부담이 되었던 반면, 제안된 TI NS SAR ADC에서는 OSR 특성으로 인해 모든 time-interleaving spur들이 out-of-band에 존재하게 되어 어떤 calibration도 필요없는 장점을 갖는 다는 점이 매우 매력적으로 보인다. 40nm CMOS에서 구현된 prototype ADC는 400MS/s 동작속도에서 50MHz 대역폭을 갖고 70.4dB의 SNDR을 달성하였으며 13mW의 전력을 소모하였다.
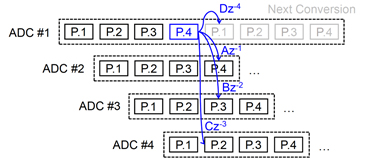
#20.3: Noise coupling in time-interleaved noise-shaping SAR ADC.
(#20.4) MediaTek은 최초로 7nm공정에서 구현된 continuous-time (CT) delta-sigma modulator (DSM)를 발표하였다. 기존 NS SAR ADC의 선형성 개선을 위해 사용하던 mismatch error shaping (MES) 기법을 본 논문에서는 MSB/LSB-segmented feedback DAC 구조에서의 선형성 개선을 위해서 LSB segment에 적용하였고, 그로 인해 DEM 구현의 부담을 크게 줄였다. 또한, SAR quantizer를 이용한 digital noise coupling 기법을 적용하여 추가적인 noise shaping을 구현하되, digital noise coupling 과정에서 발생하는 LSB 양자화 잡음의 문제를 modulator의 loop 밖에서 digital noise compensation filter를 구현함으로써 해결하였다. 1차의 loop filter만을 구성하여 compact한 구현을 하였고, OSR 8로 25MHz 대역폭 내에서 74dB의 SNDR을 달성하였다. 전력소모 3.8mW.
(#20.5) University of Macau에서는 1st stage quantizer에 noise-coupling 기술을 적용한 4차 sturdy-MASH DSM 구조를 제안하였다. STF2 = 1을 갖는 이상적인 sturdy-MASH 구현을 위해 2nd stage를 quantizer만으로 구현하였고 (integrator가 없는 0차), FIR DAC을 이용하여 feedback DAC의 비선형성 영향을 줄임으로써 DAC calibration이나 error shaping의 필요성을 제거하였다. 본 설계는 50MHz 대역폭을 갖고 76.6dB의 SNDR 달성하였으며, 29.2mW의 전력을 소모하였다.
(#20.6) MediaTek에서는 loop filter 내에 low pass filter (LPF)와 programmable gain amplifier (PGA) 기능을 내장하는 dual-mode DSM 구조를 선보였다. 28nm CMOS로 구현된 DSM은 80MHz-대역 모드에서 64.9dB의 SNDR을 (전력소모 7.3mW), 10MHz-대역 모드에서는 76.8dB의 SNDR을 얻었다 (전력소모 4.15mW).
(#20.7) University of Macau에서는 SAR ADC를 quantizer로 갖는 CT DSM에서 quantization에 소요되는 시간을 줄이기 위해서 SAR ADC의 redundancy를 이용한 preliminary sampling 기법을 제안하여 28nm CMOS 공정에서 100MHz의 광대역을 구현하였다. 구현된 ADC는 72.6dB의 SNDR을 얻고 16.3mW의 전력을 소모한다.

김 지 훈 교수 이화여자대학교 전자전기공학과
연구분야 Digital SoC / Processor ArchitectureE-mail jihoonkim@ewha.ac.kr
Digital Architectures & Systems Subcommittee에서는 예년과 유사하게 보안을 포함하는 다양한 신호처리 프로세서와 머신러닝 프로세서에 대한 많은 연구들이 Session 2 : Processors와 Session 7 : Machine Learning 을 통해서 발표되었다. 또한, 딥러닝에 대한 높은 관심을 반영하듯 올해 ISSCC의 Plenary Session에서도 이와 관련한 여러 발표들이 있었다.
# Plenary Session
New York University의 교수이면서 Facebook의 Chief AI Scientist이기도 한 Yann LeCun 교수가 발표한 “Deep Learning Hardware: Past, Present, and Future”에서는 50년대부터 시작된 AI (A에 대한 연구가 현재 딥러닝에 이르기까지의 주요 발전사항을 되짚어보며 딥러닝 하드웨어의 필요성에 대해서 언급하였다. 이와 함께, self-supervised learning의 중요성과 함께 아키텍쳐가 변하는 dynamic network 등과 같이 향후 딥러닝 연구의 주요 방향에 대해서도 소개를 하였다.
KAIST 유회준 교수는 해당 세션의 두번째 연사로 참여하여 발표한 “Intelligence on Silicon: From Deep-Neural-Network Accelerators to Brain Mimicking AI-SoCs”를 통해, cloud computing에 기반을 두던 AI의 중요성이 edge device 및 mobile device로 점차 옮겨오고 있음을 소개하고, 이를 위한 DNN (Deep Neural Network) 하드웨어의 다양한 수준에서의 최적화 방안을 대해서 설명을 하였다. 또한, 리소스가 제한된 기기에서의 AI를 위한 local learning 및 향후 AI하드웨어의 연구 방향인 brain-mimicking 구조 등을 그림1과 같이 소개 해주었기에, 관련 분야 연구자라면 반드시 눈 여겨볼 필요가 있다.
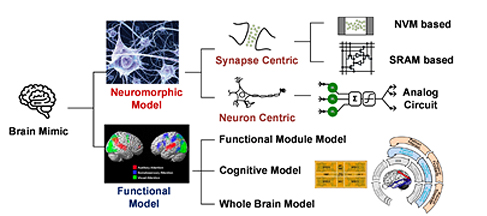
그림 1. Hardware Types of Brain Mimicking
# Session 2 : Processors
MIT는 작년에 발표한 Reconfigurable DTLS (Data Transport Layer Security) Cryptographic Engine에 이어, 최근 많은 주목을 받고 있는 IoT (Internet of Things)에서의 보안을 위한 Configurable Lattice Cryptography Processor를 그림 2와 같이 발표하였다. 현재의 RSA 및 ECC (Elliptic Curve Cryptography)와 같은 공개키 방식의 보안이 대규모 Quantum Computer에 의해 취약성을 보인다는 것이 잘 알려진 상황에서, lattice기반의 암호가 그 대안으로서 많은 주목을 받고 있다. 이를 위해 본 논문에서는 NIST post-quantum standardization process의 Round1에 제안된 다양한 lattice기반 암호들을 수행할 수 있는 하드웨어 구조를 발표하였고, 40nm LP CMOS공정에서 제작된 칩은 106K Gate Count를 가진다.
Intel은 배터리로 동작하는 로봇인 Minibot을 위한 22nm CMOS공정기반의 저전력 Robot SoC를 발표하였다. 해당 로봇은 여러개가 동시에 협력하여 복잡한 활동을 가능케 하는 것을 목표로 하고 있으며, 이를 위해 ‘dstributed / autonmous and collaborative’에 초점을 맞추고 있다. 22nm CMOS 공정으로 제작된 SoC는 그림 3에 나타난 바와 같이 (1)센서신호획득 및 전처리를 위한 x86기반 real-time subsystem, (2) localization / mapping / collision avoidance / collaborative intelligent decision making등을 위한 Tensilica DSP processor, (3) path planning (PP) 및 motion control (MC)를 위한 hardware accelerators, (4) 사람의 음성신호 인식을 위한 always-on subsystem, (5) object detection 및 recognition을 위한 x86 processor 및 CNN (Covolutional Neural Network) 가속기등을 포함하고 있다.
-
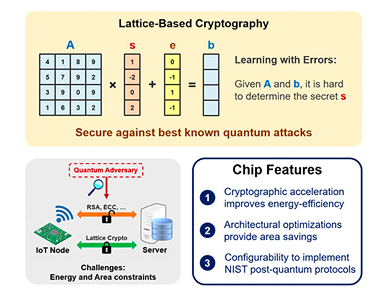
그림 2. IoT를 위한 Quantum-resistant security 및 제안하는 Chip 주요사항
-
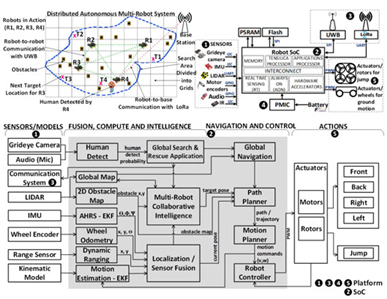
그림 3. System Architecture 및 Algorithmic Flow
# Session 7 : Machine Learning
삼성전자는 자사의 Flagship Smartphone인 Galaxy S10에 탑재된 Neural Processing Unit (NPU)을 발표하였다. 해당 NPU는 전체 SoC의 host system과의 데이터 전송 및 NPU구성을 담당하는 NPU Controller와 실제 MAC연산을 수행하는 dual-core 형태의 NPU Core를 갖고 있다. 1024개의 MAC unit을 탑재하고있는 해당 시스템은 Convolutional Layer 및 Fully Connected Layer연산에 최적화되어 다양한 병렬성 및 sparsity aware 기능을 포함하고 있다. 8nm CMOS공정을 이용하여 제작된 NPU는 Inception-v3을 구동하면서 3.4TOPS/W의 효율을 보였으며 그림 4에 나타난 바와 같이 5x5 kernel을 기준으로 최대 11.5TOPS/W의 성능을 나타내고 있다.
KAIST는 edge device 및 mobile device에서의 local DNN learning의 필요성을 이야기하며, 해당 기능을 포함하는 NPU를 소개하였다. 해당 NPU는 그림 5에 나타난 것과 같은 특성을 고려하여, FP8과 FP16을 혼용하여 동작시킬 수 있는 Fine-Grained Mixed Precision (FGMP)기능을 포함하고 있으며 이를 통해 learning accuracy는 유지하면서 external memory 접근에 대한 최적화를 이루었다. 또한, input load balancer를 포함하여 PE (Processing Element)들의 전체적인 utilization을 높였다. 65nm CMOS공정에서 제작된 해당 NPU는 0.78V에서 최대 25.3TFLOPS/W의 동작 효율성을 보인다.
-
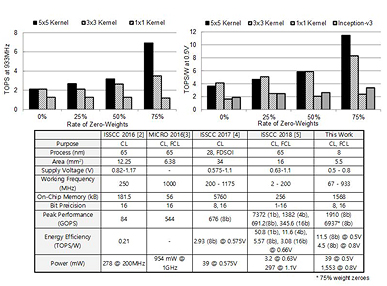
그림 4. 측정결과 및 성능비교
-
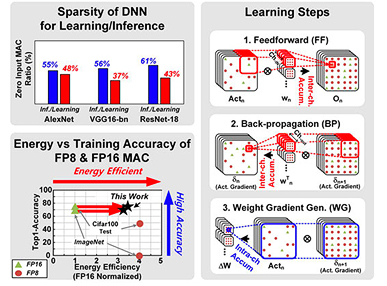
그림 5. DNN Learning의 특성
