|
이번 VLSI에서 Processors, SoCs, quantum computing, and machine learning 분야와 관련해서 Session 8과 Session 9에서 총 8개의 논문으로 소개됐다. 이번 VLSI의 theme은 “VLSI Systems for Lifestyle Transformation”으로 코로나에 의해 바뀐 생활과 관련된 여러 특강들이 포함된 구성을 선보였다. 이 세션에서는 이러한 theme과 특별히 관련있지는 않고 계속 각광받고 있는 딥러닝 연산 관련해서 특정 목적 연산을 가속하는 아키텍처를 소개하는 논문들이 소개됐다. Session 9의 4개의 논문 중에서 효율적인 딥러닝 연산에 관한 논문 3개를 살펴보겠다.
#9-1는 Intel Labs에서 발표한 논문인데 이전에 제시한 뉴로모픽 리서치용 프로세서인 Loihi에 대한 리뷰 형식의 논문이다. 먼저 뉴로모픽 아키텍쳐가 가져야 할 원칙들을 소개했다. Spiking activation에 의한 병렬적 구조에 의한 낮은 연산 지연시간, temporal state를 가지는 뉴런 유닛에 의한 효율성 증가, 가중치값이나 파라미터들이 각 유닛 근처에서 업데이트가 가능한 구조, 에너지 효율에 유리한 asynchronous 동작 등이 점들이 중요하다고 본 논문에 강조되어 있다. 이러한 구조로 인해 그림1에서 볼 수 있듯이 다르 프로세서들 보다 더 좋은 Energy-Delay Product (EDP)를 만들어준다. 다음으로 이러한 뉴로모픽 구조에서 SNN을 학습시키기 위한 spike-rate-coding, backprop 알고리즘을 불연속 SNN에 바로 적용, synaptic plasticity 법칙으로 gradient descent을 적용하는 방법들에 대한 하드웨어 구조가 부족해서 큰 예제들을 Loihi가 소화하기에 한계가 있다고 나와있다. 꼭 딥러닝 목적이 아니라도 그림 1에 나온 여러한 연산들과 저전력, 저지연 시스템에 대해 Loihi의 연산 구조가 효율적이지만 관련 회로나 공정에서의 발전이 필요하다고 강조했다.
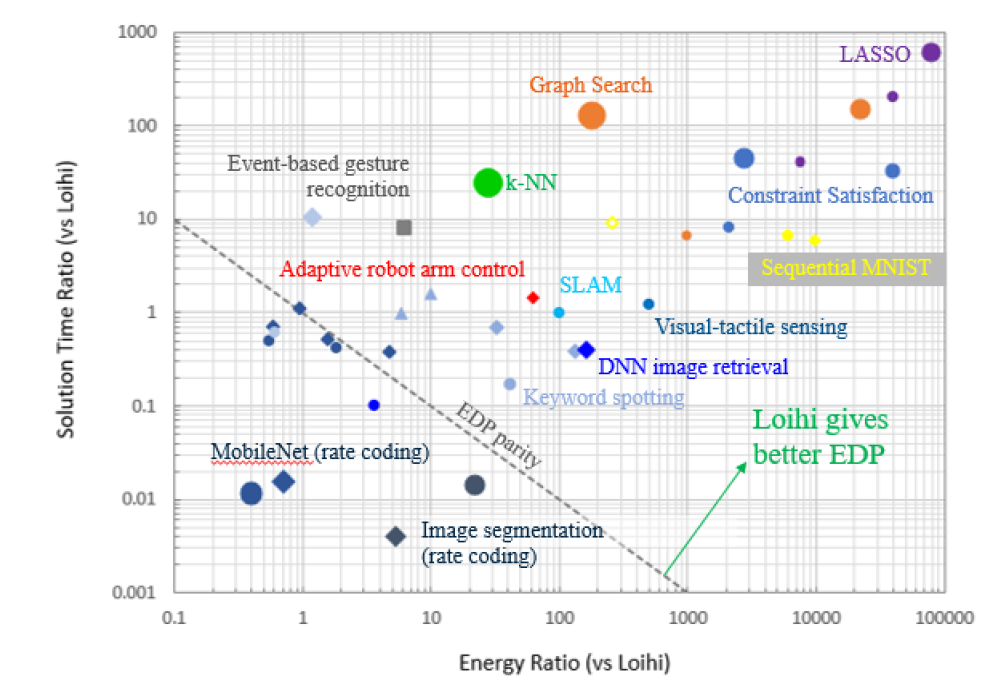 |
| [그림 1] 다른 아키텍처 대비 에너지 측면과 지연시간 측면에서의 Loihi의 상대적 강점 |
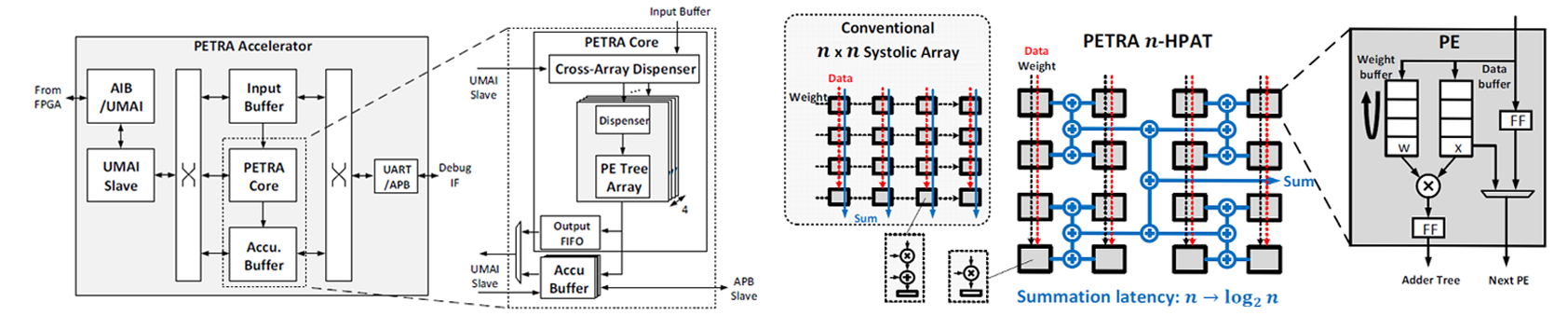 |
| [그림 2] (좌) PETRA 가속기의 전체 아키텍쳐 , (우) PETRA 아키텍쳐의 장점과 PE의 구조 |
|
#9-3은 미시간대학교와 Intel Corp.에서 발표한 논문으로 행렬 곱셈기를 Processing Element TRee Array (PETRA) 방식을 통해 H-tree accumulation을 통해 연산 시간을 O(n)에서 O(log(n))으로 줄였다. PETRA의 PE는 FP16 곱셈기, 회전식 가중치 버퍼, 데이터 버퍼로 그림2의 오른쪽과 같이 구성되어 있다. 행렬 연산에서의 각 부분합을 기존과 다르게 H-tree 방식의 adder tree (HPAT)를 이용해 부분합 축적 시간을 줄일 수 있다. HPAT의 상위 레벨은 configurable adder tree로 구성되어 있어 adder tree를 다양한 구조로 구성할 수 있게 만들어 동시다발적 연산이 가능하다. 전체 PETRA 가속기는 그림2의 왼쪽과 같고 각 코어의 dispenser를 통해 입력 재활용 및 균형잡힌 workload를 가능하게 한다. 이를 이용해 4개의 16x16 PE 어레이를 만들어 FPGA와 Embedded Multi-die Interconnect Bridge (EMIB)를 이용해 합쳐서 이전 연구보다 개선된 6.97TFLOPS/W의 최대 에너지 효율 성능 수치를 얻을 수 있었다.
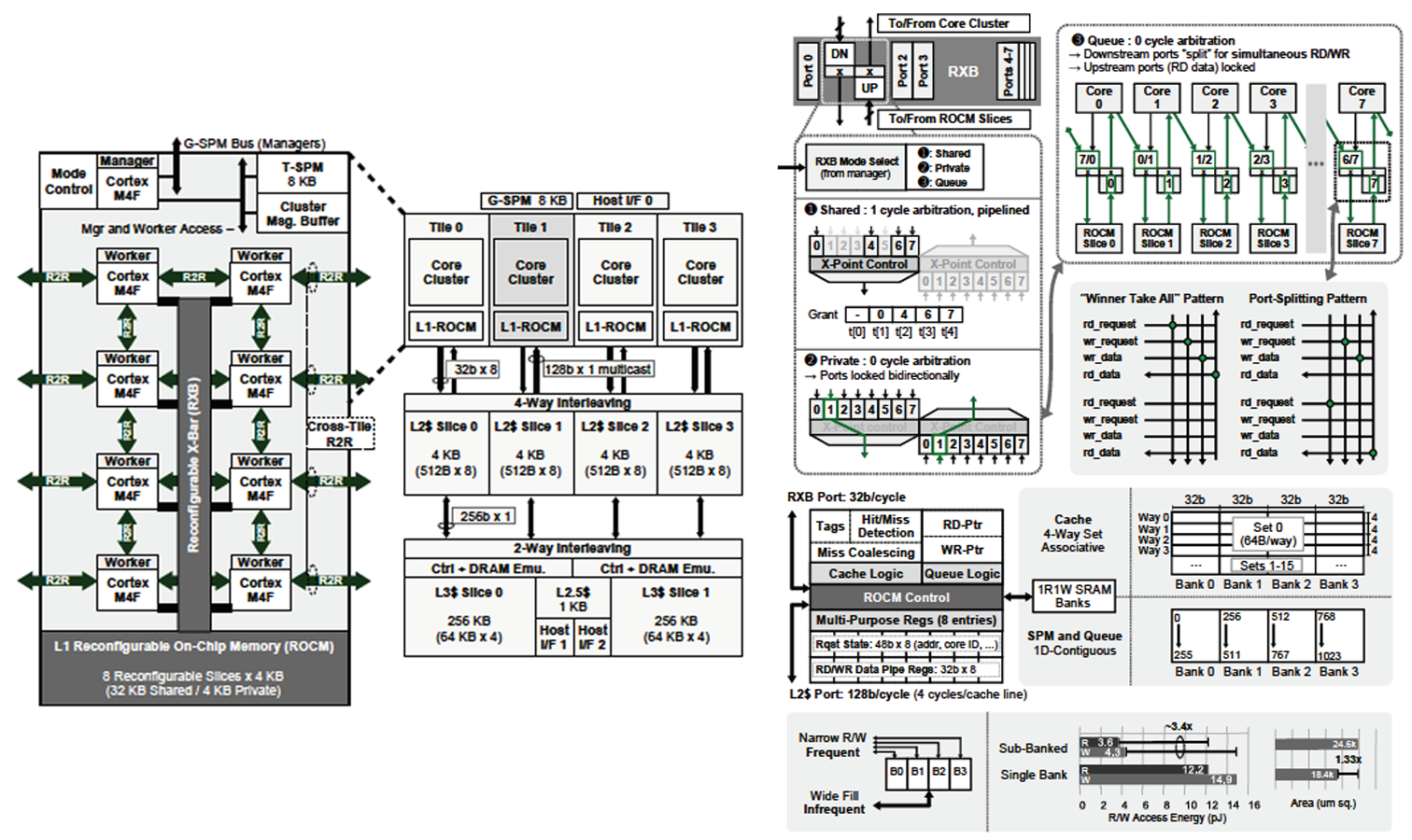 |
| [그림 3] (좌) Versa 타일의 구조와 전체 칩 아키텍쳐, (우) 가변구조형 크로스바의 shared, private, queue 모드와 L1-ROCM 구현 |
|
#9-4는 미시간대학교와 아리조나주립대학교에서 발표한 논문으로 기존 프로그램 가능한 아키텍쳐의 변하는 알고리즘에 대한 제한된 지원 문제를 해결하기 위해 Versa를 제안한다. 전체 구조는 그림3의 왼쪽과 같이 연산 타일과 3레벨 메모리 체계로 구성되어 있다. 각 타일은 8개의 ARM Cortex-M4F의 worker로 이루어져있고 각 worker들은 register-to-register (R2R) 링크로 연결되어서 인접한 코어들과 통신이 효율적으로 이루어지게 설계됐다. 또한 reconfigurable crossbar (RXB)를 통해 그림3의 오른쪽과 같이 shared, private, queue 모드로 전환해 다양한 작업에 효율적이게 데이터 입출력을 관리할 수 있다. L1 reconfigurable on-chip memory (ROCM)도 마찬가지로 cache, SPM, queue 모드로 변환 가능하다. 그리고 scratchpad를 tree 형태로 타일 레벨과 글로벌 레벨에 배치해서 접근 배리어를 낮췄다. MachSuite 커널에 대해 테스트한 결과, 여러 작업들에 대해서 다른 모바일 CPU나 GPU 대비 평균적으로 각각 11.6배, 37.2배 에너지 효율이 향상했다.
| #Sensors, imagers, and display circuits |
|
ㆍSession 6 / Converters and Sensing Analog Frontend
ㆍSession 19 / Circuits for Sensing Applications
|
|
올해 2021 Symposium on VLSI Circuits에서는 sensors, imagers, and display circuits 관련 논문들이 C6에 5편, C19에 4편의 논문이 발표 되었다. C6에는 5편의 논문이 발표되었으며, 각 논문 마다 저전력 저잡음 analog front-end (AFE), Sigma-Delta (ΔΣ) capacitance-to-digital converter (CDC), resistor-to-digital converter (RDC), impedance-monitoring IC, fully-integrated current sensor와 같은 다양한 주제의 아날로그 회로 기법들에 대한 논문들이 발표되었다.
C6-1은 미시간 대학교의 Blaauw 그룹에서 발표한 논문으로 증폭기의 fast restabilization를 위해 automatic saturation detection 및 feedback resistance modulation이 적용된 AFE를 제안하였다. 본 논문에서는 capacitively coupled amplifier 구조에서 feedback resistor의 process, temperature에 robust한 특성을 얻기 위해 feedback resistor를 Delta-Sigma modulation (DSM) 기반의 feedback 기법을 적용하였다. 제안하는 feedback resistance modulation 기법은 첫번째 feedback은 frequency domain averaging을 적용하고 두번째 feedback은 time domain averaging을 적용하여 구현하였으며, counter-based frequency divider로 fb1 및 fb2를 생성하여 1-bit 2nd order DSM을 통해 injection frequency가 fb1 및 fb2 사이의 원하는 average된 frequency를 생성하여 process, temperature에 영향이 적은 안정적인 TΩ-level resistance를 구현할 수 있다. 본 논문에서 제안하는 automatic saturation detection은 증폭기의 saturation 상태를 VBP 와 VBN을 비교기를 통해 비교하여 감지한다. 증폭기가 saturation 되었을 때, 비교기가 trigger feedback frequency clock divider는 고주파 모드 (programmable from 250 Hz – 4 kHz)로 동작시켜 증폭기를 다시 stable 상태로 되돌린다. 제안하는 AFE는 180 nm CMOS 공정으로 제작되었으며 1.463 mm2의 면적을 가진다. 제안하는 기법을 적용한 증폭기의 restabilization를 시간을 10x 빠르게 개선하였으며, 전원전압 1.4 V에서 119 nW의 전력을 소모하며 2.6의 noise efficiency factor (NEF) 성능을 가진다.
|
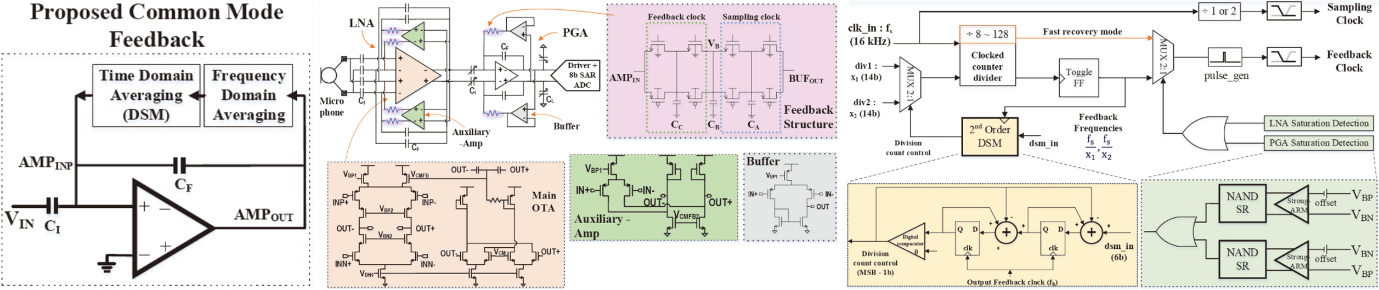 |
| [그림 1] C6-1 논문에서 제안한 automatic saturation detection 및 feedback resistance modulation이 적용된 AFE |
|
C6-2는 KAIST에서 발표한 논문으로 3.68 aFrms의 해상도와 183 dB의 Schreier figure-of-merit (FoMS) 성능을 가지는 4th-order continuous-time bandpass (BP) ΔΣ CDC를 제안하였다. 제안하는 CDC는 기존의 switched-capacitor (SC) discrete-time (DT) ΔΣ CDC의 경우 noise folding에 의해 input-referred voltage noise power가 증가하는 단점을 극복하기 위해 noise folding이 발생하지 않고, 1/f noise와 같은 저주파 noise가 영향을 주지 않는 전력 효율적인 BP-ΔΣ modulator 구조를 적용하였다. 제안하는 CDC의 input stage는 capacitive feedback amplifier를 사용하며, 입력 커페시터 센서 (CSense)의 sensing range를 증가시키기 위해 programmable reference capacitor array (CRef)를 사용하여 조절가능하게 하였다. ΔΣ modulator의 active RC integrator는 high DC gain 및 작은소비전력을 얻기 위해 gain-boosted inverter-based amplifier를 사용하였다. 제안하는 CDC는 180 nm CMOS 공정으로 제작되었으며 1.029 mm2의 면적을 가진다. 제안하는 CDC는 CSense가 각각 10 fF 및 18 pF 일 때 3.68 aFrms 및 11.09 aFrms의 해상도를 가진다. 또한, 제안하는 CDC는 입력 커페시턴스가 18 pF 일 때 183 dB의 FoMS 성능을 가지며, 이것은 state-of-the-art의 CDC들 보다 2배 이상의 효율을 가진다는 것은 보여준다.
|
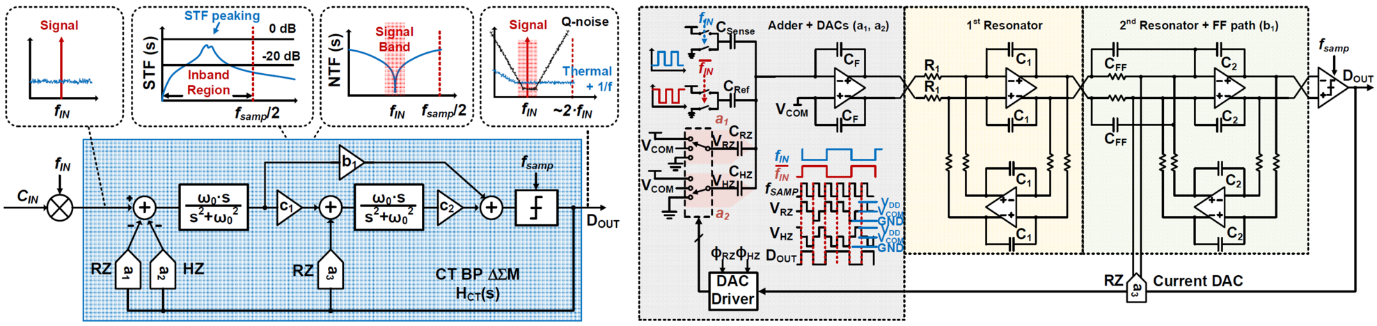 |
| [그림 2] C6-2 논문에서 제안한 4th-order continuous-time BP ΔΣ CDC |
|
C6-3는 연세대에서 발표한 논문으로 benzene, toluene, ethylbenzene, xylene (BTEX) 화학약품 검출을 위한 가스 센서용 resistor-to-digital converter (RDC)를 제안하였다. 제안하는 RDC는 continuous-time delta-sigma analog-to-digital converter (ADC)를 기반으로 heat level이 각기 다른 BTEX 약품들을 단일 저항 R을 통해 검출할 수 있다. 센서 저항 RS는 각각의 BTEX에 따라 온도 300℃에서 저항 범위 40 – 140 kΩ을 가지며, 온도에 따라 각각의 BTEX에 반응한 RS 저항 범위 40 – 200 kΩ 이기 때문에 제안하는 RDC는 온도 조건에 따라 저항 범위 40 – 300 kΩ의 넓은 범위를 구동할 수 있다. 또한, 제안하는 RDC는 current domain에서 신호를 처리하여 더 나은 energy-efficiency를 얻을 수 있다. RDC는 16-level quantizer를 적용한 2nd-order loop filter로 구성되어 있으며 첫 단의 voltage regulation loop와 1st integrator의 증폭기는 inverter-based amplifier가 사용되었으며, 두번째단은 VCO-based integrator 와 phase quantizer으로 구성되었다. 제안하는 RDC의 시제품은 110 nm CMOS 공정으로 제작되었으며 0.093 mm2의 면적을 가진다. 제안하는 RDC는 863 mΩ의 저항분해능을 가지며, 전원전압 1.5 V에서 96 μW의 전력을 소비하며, 0.06 ppb의 가스분해능과 47.5 nJ의 energy per measurement 성능을 가진다.
|
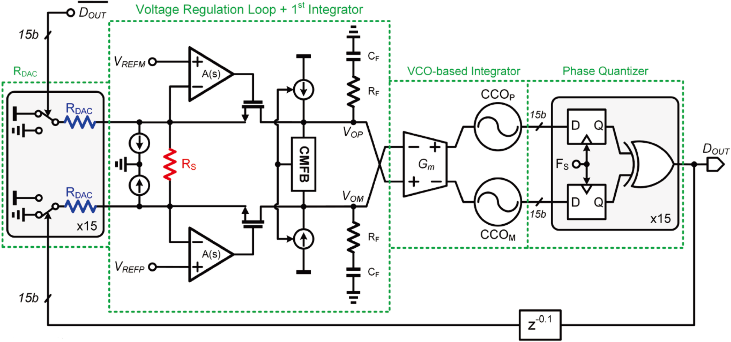 |
| [그림 3] C6-3 논문에서 제안한 BTEX 검출용 47.5 nJ RDC |
|
C6-4는 KAIST에서 발표한 논문으로 IF-sampling architecture 기반의 impedance-monitoring IC을 제안하였다. 제안하는 impedance-monitoring IC는 instrumentation amplifier (IA)에서 single-side-band (SSB) mixer를 사용하여 신호를 intermediate frequency (fIF)로 down-converting 하여 spectral density를 개선하였다. 본 회로에서는 신호를 fIF 대역으로 down-converting 시 current generator에서 harmonic들이 발생하는 것을 방지 하기 위해 Rx단의 current generator에 XNOR gate를 사용한 SSB mixer를 적용하였다. 제안하는 IF-sampling architecture는 narrow-bandwidth (BW) low-pass filter (LPF)를 필요로 하지 않기 때문에 fast output data rate (ODR)를 얻으며, time-interleaved (TI) DFT를 적용하여 더욱 개선된 ODR을 얻을 수 있다. 제안하는 회로는 fIF에서 가장 좋은 노이즈 성능을 얻기 위해 auto-calibration 및 BP truncation이 적용된 band-pass delta-sigma ADC (BP-ΔΣ-ADC)를 적용하였다. 제안하는 impedance-monitoring IC는 180 nm CMOS 공정으로 제작되어 13.3 mm2의 면적을 가지며, 전원전압 1.8 V에서 아날로그 회로는 258 μW의 전력을 소비한다. 제안하는 IC는 4 k – 8 MHz의 주파수 범위에서 0.35 ΩRMS의 임피던스 분해능을 가지며, 122.1 Hz bandwidth에서 31.25 kS/s의 ODR 성능을 가진다.
|
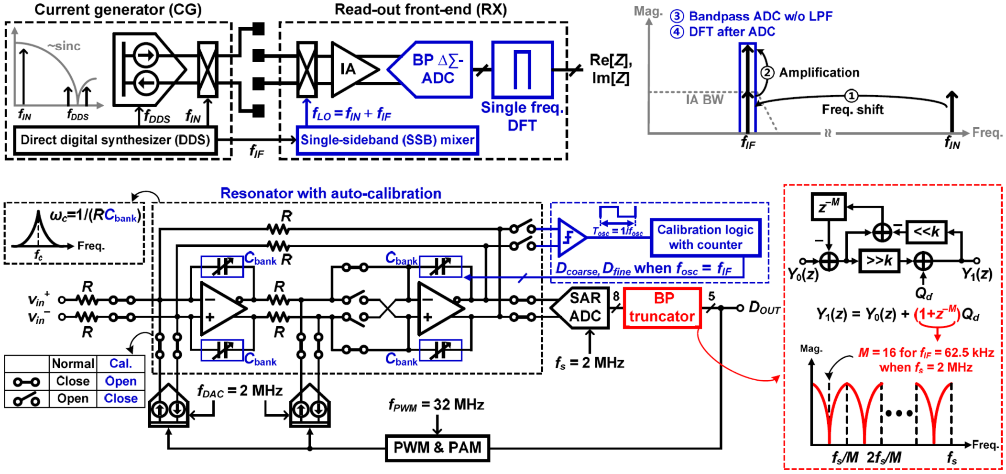 |
| [그림 4] C6-4 논문에서 제안한 impedance-monitoring IC와 auto-calibration 및 BP truncator가 적용된 BP ΔΣ-ADC |
|
C6-5는 Delft 대학교의 Makinwa 그룹에서 발표한 논문으로 analog temperature-compensation scheme이 적용된 current sensor를 제안하였다. 제안하는 ±2A fully-integrated current sensor는 on-chip shunt된 20 mΩ 및 1.4 μA 밖에 소비전류를 사용하지 않는 FIR-DAC를 적용한 energy efficient hybrid sigma-delta ADC로 구성된다. 제안하는 current sensor의 fully differential readout circuit은 1st order ΔΣ ADC 기반이며, modulator가 common mode input 이상의 신호를 구동하기 위해 capacitively-coupled instrumentation amplifier (CCIA)로 summing node를 구성하였다. 본 논문의 current sensor에는 tunable analog non-linear temperature-compensation scheme (TCS)이 적용되어 −40 – 85 °C 온도 범위에서 ±2A current를 0.35 % gain error의 작은 오차로 디지털 신호로 변환 할 수 있다. PCB 상에서 3 mΩ을 shunt하였을 땐 ±15A current를 0.6 % gain error의 오차로 디지털 신호로 변환 할 수 있다. 제안하는 current sensor는 180 nm CMOS 공정으로 제작되어 1.6 mm2의 면적을 가지며, 전원전압 1.8 V에서 1.4 μA의 전류를 소비한다. 본 current sensor는 클록 주파수 32 kHz 일 때 conversion time 15.625 ms에서 5.4 μVRMS의 해상도를 가진다. 제안하는 current sensor는 state-of-the-art의 current sensor들 보다 3× 소비전류를 소모하며, 경쟁력 있는 0.35 %의 gain error 및 25 μA의 offset 성능을 가진다
|
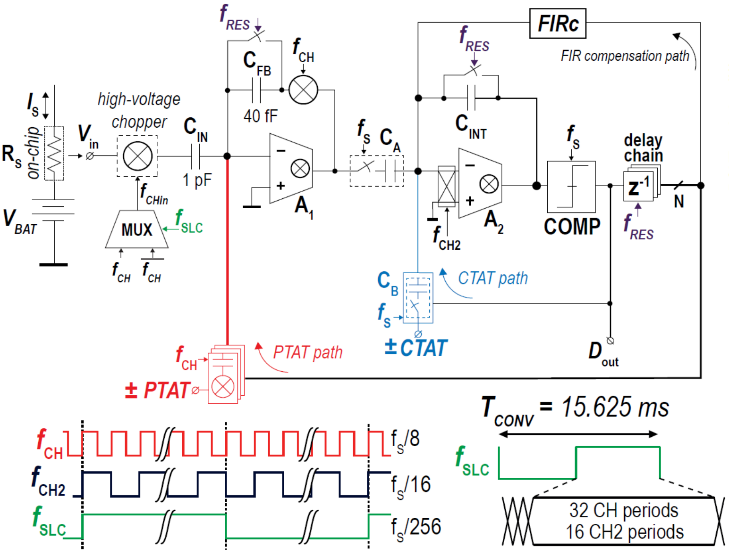 |
| [그림 5] C6-5 논문에서 제안한 current sensor의 single-ended block diagram |
|
C19에는 4편의 논문이 발표되었으며, 각 논문 마다 direct-digitization open-loop gyroscope frontend, self-powered wireless gas sensor node, silicon photomultiplier (SiPM) readout IC, e-skin sensing encoding을 위한 area-, energy-efficient decoder와 같은 다양한 주제의 센서 인터페이스 회로에 대한 논문들이 발표되었다.
C19-1는 Robert Bosch 사에서 발표한 논문으로 state of art의 4× 넓은 input range +/-8000°/s를 갖는 direct-digitization open-loop gyroscope frontend를 제안하였다. 제안하는 gyroscope frontend는 movement 및 sensing structure 사이의 potential difference에 비례해서 생성되는 displacement currents는 CDC를 통해 directly digitize 된다. 전체 gyroscope frontend의 클록은 집적된 phase-locked loop (PLL)에 의해 생성된다. Coriolis channel에서 high resolution sinusoids을 사용하여 CDC output 신호를 demodulation 하며, 이 때 발생하는 demodulation phase error를 sampling-jitter-induced-noise cancellation을 통해 sampling jitter에 의한 noise를 relaxation 시킨다. 제안하는 CDC는 capacitively coupled three-level 8-tap FIR feedback 구조를 적용하여 charge summation circuit을 구성하여 kT/C noise, feedback quantization noise, PLL의 phase-noise performance demand를 relation 시켰다. 또한, dynamic element matching 기법을 적용하여 three-level feedback의 non-linearity 특성을 완화시켰다. 제안하는 gyroscope frontend는 110 nm CMOS 공정으로 제작되어 3.492 mm2의 면적을 가지며, 전원전압 1.62 V – 3.63 V에서 650 μA의 전류를 소비한다. 제안하는 회로에 적용된 sampling-jitter-induced-noise cancellation을 통해 noise floor 를 0.0047°/s/√Hz 수준으로 낮추었으며, Schreier FOMDR 154.4 dB로 지금까지 발표된 state-of-the-art consumer electronic (CE) gyroscope 중 가장 좋은 성능을 가진다.
|
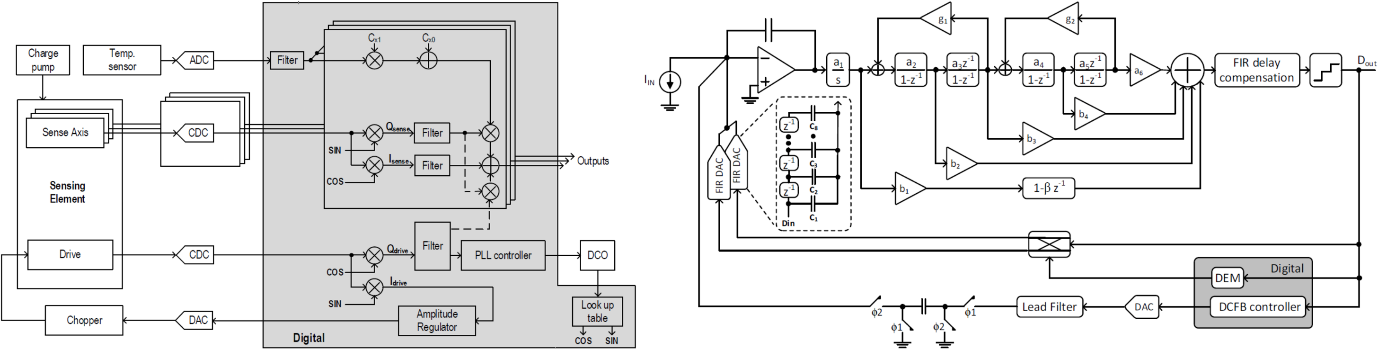 |
| [그림 6] C19-1 논문에서 제안한 direct-digitization open-loop gyroscope frontend 및 CDC |
|
C19-2는 KAIST에서 발표한 논문으로 photovoltaic (PV) energy harvesting (EH) 기반의 compact self-powered wireless gas sensor node를 제안하였다. 제안하는 gas sensor node는 mm3 사이즈의 colorimetric sensor film을 PV cell과 집적하였으며, gas signal processing (GSP)이 EH 회로 기반으로 가능하다. 또한, dual-input shared-inductor boost converter가 집적되어 EH efficiency를 높였다. 또한, 제안하는 회로의 accurate gas-sensing readout을 위해 offset cancellation을 적용하여 external trimming 없이 offset을 보정할 수 있다. 제안하는 회로는 power-on reset & ring oscillator (POR & OSC), maximum-power-point-tracking (MPPT), boost converter & LED controller (BOOST & LED CTRL), 및 GSP로 구성된다. 제안하는 회로의 GSP는 offset-canceled subtractor와 modified split capacitor 구조의 10-bit successive-approximation-register (SAR) ADC로 구성된다. 제안하는 gas sensor readout circuit은 180 nm CMOS 공정으로 제작되어 0.4356 mm2의 면적을 가지며, 전원전압 1.2 V 에서 1.2 μW의 전력을 소비한다. 제안하는 EH 회로의 boost converter는 88 % peak end-to-end efficiency을 성능을 가진다.
|
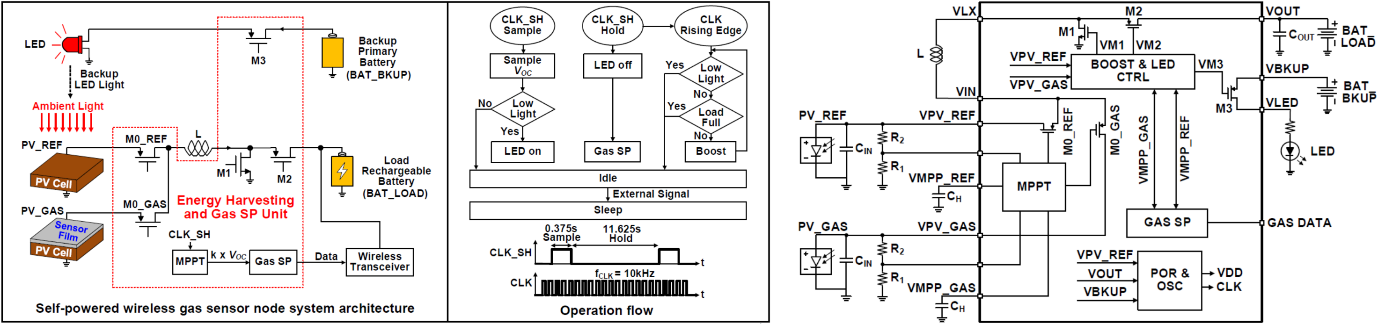 |
| [그림 7] C19-2 논문에서 제안한 self-powered gas-sensing IC |
|
C19-3는 KAIST에서 발표한 논문으로 mobile dosimeter를 위한 SiPM readout IC를 제안하였다. 제안하는 readout IC는 radiation detector 구동을 위한 duty quantizer가 embedded된 boost converter를 적용하여 추가적인 sensor interface circuit 없이 방사선 신호를 디지털화 할 수 있다. 제안하는 radiation detection system은 radiation detector와 DC-DC converter만으로 구성되어 power & hardware efficient 하다. 제안하는 회로는 boost converter에서 생성되어 SiPM에 공급 되는 전류가 방사능 입자가 inject 되어 생성되는 ISiPM과 동일 하기 때문에 radiation detection이 추가적인 sensor interface circuit 없이 control information을 directly 획득 할 수 있다. 방사선 입자가 scintillator를 통해 SiPM에 inject 될 때 ISiPM에 의해 전압강하 (ΔV)가 발생한다. 이때, duty signal (VDT)가 power switch를 껐다, 켜졌다 하면서 원래의 VBIAS 전압으로 regulation 시키며, VDT의 duty를 4-bit duty quantizer를 통해 quantization을 한다. Pulse-width-modulation (PWM) control의 discontinuous-conduction mode (DCM)에서 VDT의 duty에 의해 output charge (QOUT)가 변화하게 되고 이 때 출력으로 얻는 DOUT을 통해 ISiPM 값을 획득 할 수 있다. 제안하는 SiPM readout IC 시제품은 180 nm BCD 공정으로 제작되어 1.2 mm2의 면적을 가지며, 0.217 μArms의 integrated input referred noise 성능을 가진다. 또한, 제안하는 회로에 집적된 boost converter는 SiPM를 동작시키기위해 27 V의 출력전압을 생성하면서 1 – 10 mA의 load range를 구동할 수 있으며, control pulse duty를 DOUT으로 변환시켜 ISiPM을 readout 할 수 있다.
|
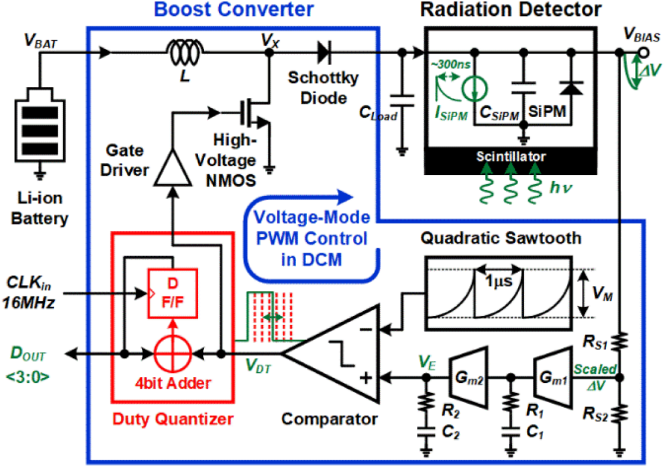 |
| [그림 8] C19-3 논문에서 제안한 mobile dosimeter를 위한 SiPM readout IC |
|
C19-4는 싱가포르 국립대에서 발표한 논문으로 tactile e-skin sensing encoding을 위해 fully-digital self-calibrating decoder를 제안하였다. 본 논문에서는 fully-digital signal-adaptive receptor interface 및 event decoder가 소개되었으며, spread-spectrum tactile pulses 및 noise에 의한 offset을 제거하기 위한 reference-less self-calibrating senseamp을 제안하였다. 제안하는 decoder는 40 nm CMOS 공정으로 제작되어 0.0075 mm2의 작은 면적을 가지며, 전원전압 1.8/1.1 V 에서 채널당 0.5 μW의 전력을 소비한다. 제안하는 decoder는 1.6-fJ/convstep energy per receptor 성능을 가지며 기존 연구 결과 보다 50× 개선되었다.
|
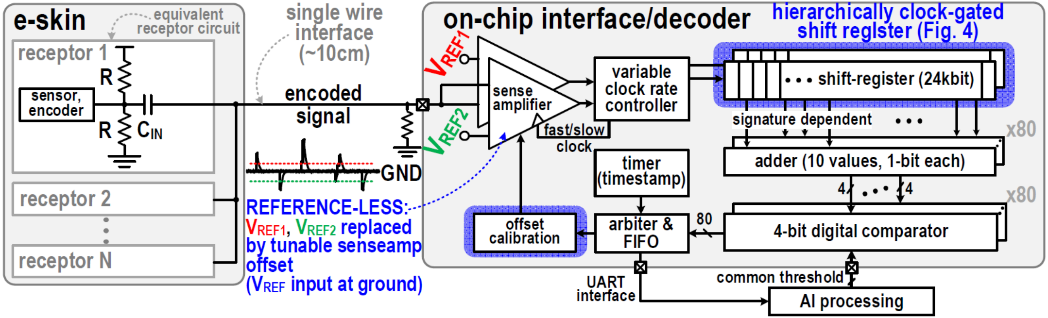 |
| [그림 9] C19-4 논문에서 제안한 e-skin sensing system 및 on-chip interface/decoder |
| #Power Conversion Circuit |
|
ㆍSession 10 / Advancements in Power Management ICs
|
|
#C10-1 An 8Ω, 5.5W, 0.006% THD+N, 2×VBAT-Swing Switched-Mode Audio Amplifier with Fully-Differential Linear Buck-Boost Topology Achieving Total Efficiency of 87%
Class-D audio amplifier (CDA)에서 높은 출력을 내기 위해 쓰이는 two-step (Buck + Boost) 전력 변환은 two-stage를 거쳐 효율이 저하되어 80% 이상의 효율을 얻기가 어렵다. 또한, buck-boost 구조의 switched-mode audio amplifier (SMAA)를 사용하여 효율을 높일 수는 있지만, 인덕터 충전 duty (D), 인덕터 방전 duty (DDE=1-D)의 비율, 즉 “D/1-D”로 duty-to-voltage conversion ratio가 결정되어 비선형적으로 바뀌는 문제가 존재한다.
본 논문은 DDE 값을 고정하고, 스위치를 추가해 충/방전 시간 사이에 freewheeling phase를 추가한 topology를 제안한다. 이를 통해 출력 전압이 D에 비례하는 선형 Class-D 동작을 구현하였으며, single-stage로 높은 효율을 보인다. 그리고 두 개의 인덕터가 사용되는 기존 differential 구조에서, 인덕터 전류 관점으로 common ground를 생략할 수 있다는 점에서 착안하여 한 개의 인덕터만으로 기존과 동일한 효과를 보였다. 두 개의 freewheeling 경로를 통해 fully-differential CDA에서 BD modulation을 구현해 고주파 전류 ripple 손실을 개선한다. 측정 결과, 최대 출력은 입력의 2배이고, 8Ω 부하 조건에서 최대 효율 87%을 달성하였다. 2W 출력 전력 조건에서 0.006%의 THD+N, 107.5dB의 SNR, 78dB의 PSRR을 얻었다.
.png) |
| [그림 1] (좌) 제안하는 구조 및 스위칭 동작 회로도. (우) 동작 파형. |
|
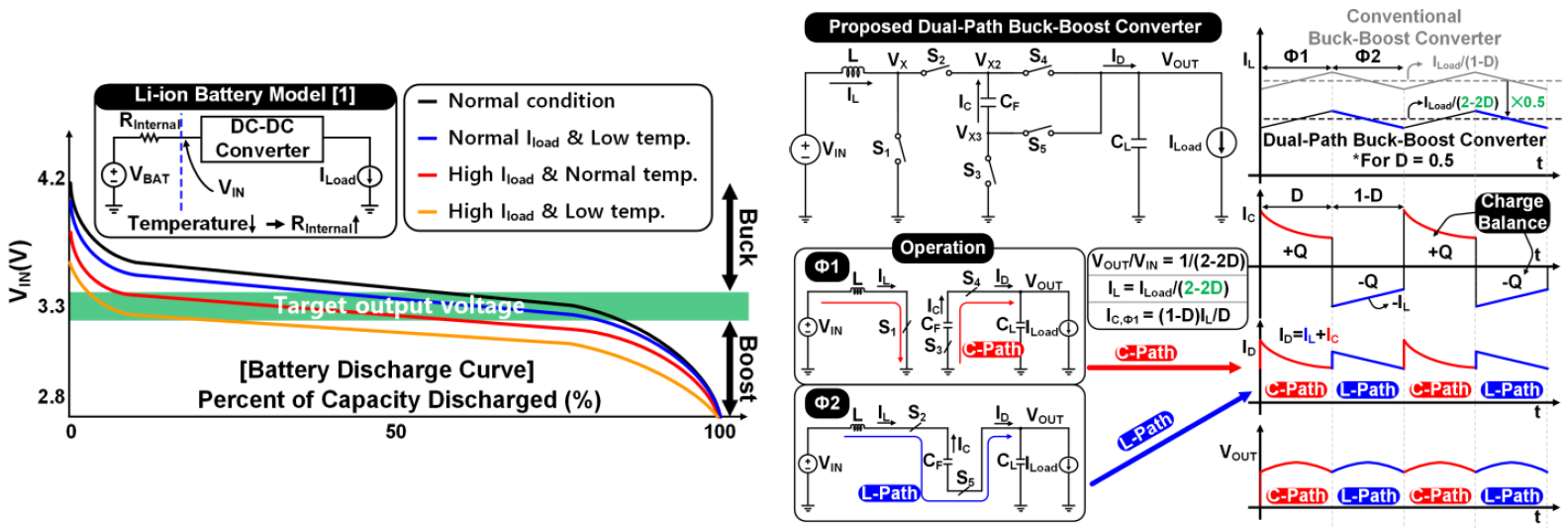
#C10-3 A 96.6%-Efficiency Continuous-Input-Current Hybrid Dual-Path Buck-Boost Converter with Single-Mode Operation and Non-Stopping Output Current Deliver
모바일 디바이스의 경우 배터리를 주 전원 공급 장치로 활용하는데, 배터리 전압은 환경에 따라 큰 범위에 걸쳐 변화하기에 목표 전압 공급을 위해서는 승압/강압 기능이 모두 필요하다. 기존 buck-boost 컨버터 구조는 출력 전류 전달 과정이 한 개 phase에서만 이루어져 출력 전압 ripple이 크고, buck-boost 간의 모드 전환으로 복잡한 제어가 필요하다. 그리고 인덕터와 flying 커패시터가 직렬 연결되는 시간(T)이 duty (D)에 비례해 conduction loss도 이에 비례하고, charge-sharing loss도 존재한다.
본 논문에서는 flying 커패시터가 출력으로 에너지를 전달하는 phase C-path, 인덕터가 출력으로 에너지를 전달하는 phase L-path를 교대로 운용하여 모든 동작 phase에서 출력 전류를 공급함으로써 출력 전압 ripple을 감소시켰다. 두 경로가 분리되어 스위치에 흐르는 평균 전류가 감소해 conduction loss가 감소하여 효율이 개선되고, 제안한 구조에서는 T가 D에 반비례해 더 넓은 범위의 D를 활용할 수 있다. 이를 통해 2.8V, 3.3V, 4.2V의 여러 입력 전압 및 400mA, 3.3V 출력 부하 조건에서 테스트하여 최대-최소 효율 간 2.64%의 낮은 차이를 얻었다. 즉, 넓은 입력 및 부하조건에서 균등하게 높은 효율을 보이며 최대 96.6%의 효율을 얻었다.
 |
| [그림 2](좌) 사용 환경에 따른 배터리 전압 변화. (우) 제안하는 회로 구조 및 동작. |
|
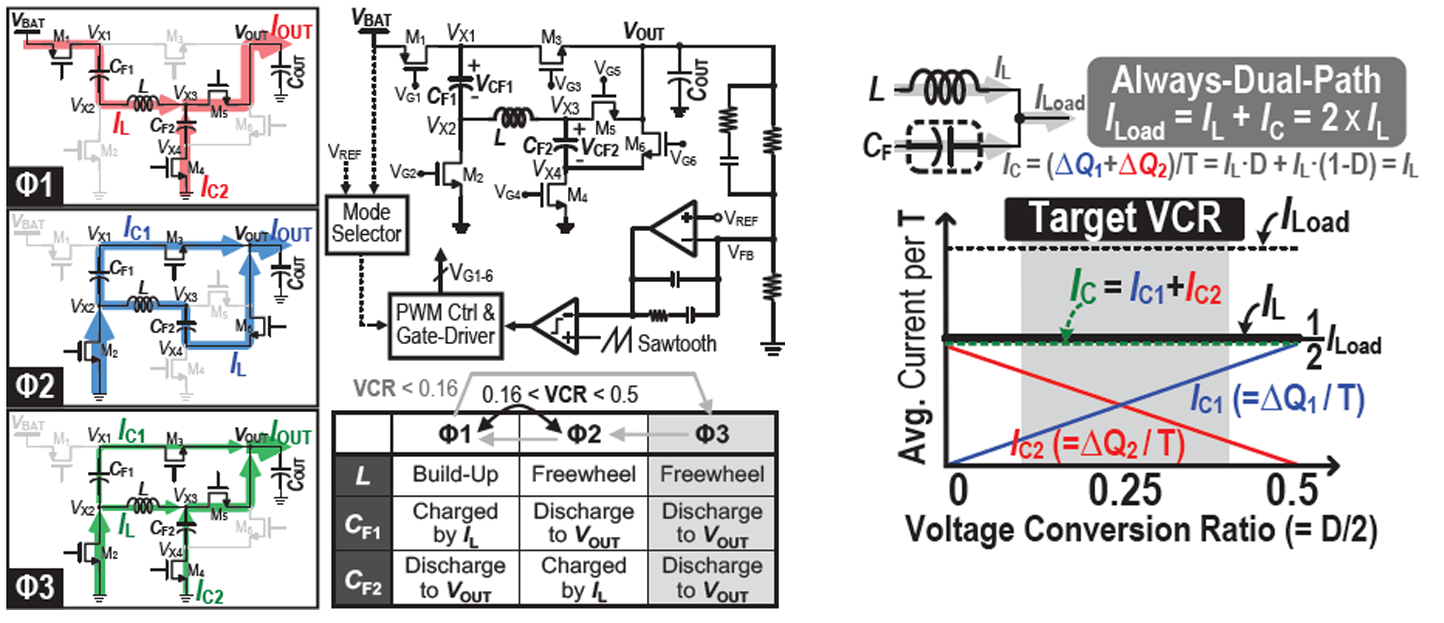
#C10-4 A 4.5V-Input 0.3-to-1.7V-Output Step-Down Always-Dual-Path DC-DC Converter Achieving 91.5%-Efficiency with 250mΩ-DCR Inductor for Low-Voltage SoCs
최신 SoC는 높은 성능을 위해 전류 소모가 증가하는데, 큰 부하 전류를 소모할 경우 주로 인덕터의 DCR에 의한 conduction 손실(∝I_L^2 R_DCR)로 효율이 크게 저하된다. 또한 소형화를 위해 칩 인덕터를 사용하면 크기는 작은 대신 더 큰 저항 값을 갖기 때문에 소형화에 제한이 생긴다.
본 논문에서는 flying 커패시터를 두 개 추가하고, 기본적으로 two-phase로 동작하는 buck 컨버터를 이용해 부하에 always-dual-path (ADP)로 에너지가 전달되는 구조를 제안한다. 각 phase 별로 두 커패시터는 교대로 충/방전 동작이 이루어져, 한 쪽이 충전되는 동안 다른 한 쪽은 부하로 에너지를 전달한다. 커패시터에 흐르는 전류는 인덕터 전류와 동일하기 때문에 인덕터 전류가 부하 전류의 절반이 되는 것을 항상 보장할 수 있어, 인덕터 전류의 제곱에 비례하는 conduction 손실을 줄였다. 추가로 voltage conversion ratio (VCR)에 따라 한 쪽 커패시터가 과 충전되어 큰 돌입 전류를 일으켜 출력 전압 ripple이 커지는 것을 방지하기 위해 두 커패시터에 충전되는 전하 간의 균형을 맞추는 phase를 추가한 three-phase 모드로도 동작할 수 있다. 측정 결과 인덕터 RMS 전류 값이 부하 전류의 절반으로 고정되며, 4mm3의 소형 칩 인덕터를 사용해 250mΩ의 상대적으로 높은 DCR에서도 conduction 손실이 감소한 결과를 얻었다. VCR 0.38, 부하 전류 0.4A 조건에서 91.5%의 최대 효율을 달성하였다.
 |
| [그림 3] 제안하는 회로의 구조 및 ADP에 따른 전류 그래프 |
|
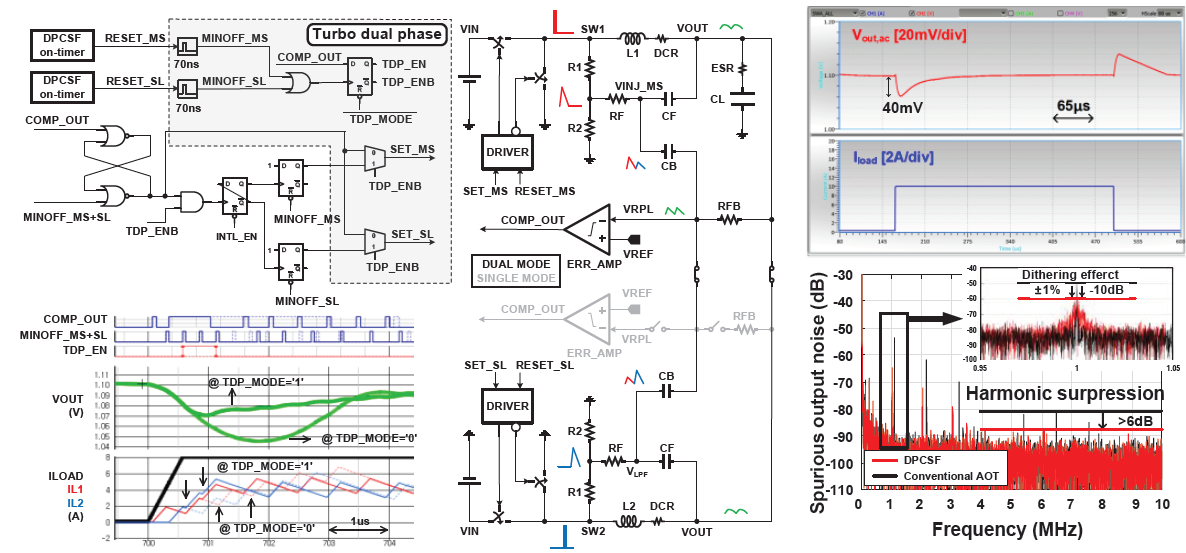
#C10-6 A 10A/μs Fast Transient AOT Voltage Regulator on DDR5 DIMM with Dithered Pseudo-Constant Switching Frequency Achieving -6dB Harmonic Suppression
DDR5 메모리는 차세대 규격으로, 기존 대비 두 배의 성능과 효율을 낼 수 있다. DDR5 메모리 내부 DRAM refreshing 동작으로 인해 최대 10A/μsec의 매우 큰 load transient가 발생할 수 있고 이로 인해 power rail에서 발생하는 dip, oscillation 등으로 인해 메모리 성능이 저하되는 문제가 있다. 추가로 실제 설계에서 스위칭 주파수는 offset, propagation delay, voltage drop 등에 영향을 받기 때문에 주파수 보상이 필요하다.
본 논문에서는 error amplifier를 통해 load 변화가 큰 경우를 감지하고, 이에 해당될 경우 입력이 서로 다른 두 경로의 인덕터를 동시에 충전하는 turbo dual-phase (TDP) 방식으로 동작해 기존 대비 두 배 이상 빠르게 load level을 맞출 수 있는 구조를 제안한다. 그리고 on-time generator의 ramp slope를 디지털 코드를 통해 조정하여 on-phase width가 부하 조건에 부합하도록 만들고, 평형 상태에 도달하면 두 디지털 코드 간에서 전환하여 dithering 하는 pseudo-constant 스위칭 주파수 제어 방식을 제안한다. 이를 통해 실제 스위칭 주파수가 목표 스위칭 주파수의 +/- 1% 내에서 dithering하며 pseudo-constant 스위칭 주파수를 생성하여 출력의 harmonic noise를 효과적으로 억제한다.
|
 |
| [그림 4] (좌) 제안하는 TDP 제어 회로도 및 시뮬레이션, (우) Load transient 측정 파형 및 출력 noise spectrum 파형 |
| #Analog building blocks |
|
ㆍSession 5 / Secure and Energy Efficient Circuits
|
|
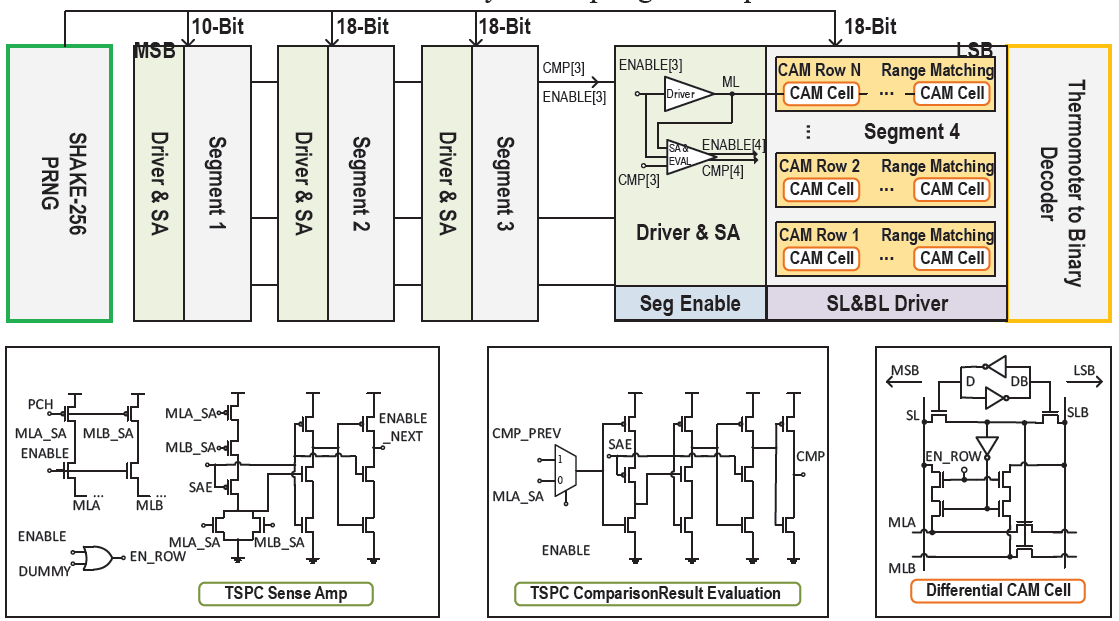
MePLER: A 20.6-pJ Side-Channel-Aware In-Memory CDT Sampler
첫번째 논문에서는 range-matching 을 위한 NAND-Type content-addressable memory (CAM) 에서 파생된 맞춤형 셀, 에너지 감소 및 타이밍 및 전력 side-channel 누설을 억제하기 위한 pipelined and segmented array 를 특징으로 하는 MePLER 라는 in-Memory 누적 분포 테이블 (CDT) sampler 를 제시했다. 기존 논문들은 무작위로 생성된 확률에 대응하는 sample 을 찾으려고 linear 혹은 binary search 를 했었는데, 이는 CDT sampler 들을 느리고 side-channel 누설이 있게끔 만들었다. CDT sampling 이란 미리 계산된 누적 밀도 함수 테이블에 필요한 반전 샘플링의 instantiation 이다. [0,1] 의 균일한 무작위 샘플이 속하는 테이블의 간격을 찾고, 간격의 인덱스는 주어진 CDF 를 따라 무작위 샘플이 된다. 이때, 표준 9-T cell 에 인버터로 제어되는 하나의 extra NMOS 를 추가하여 특수하게 설계된 NAND-type CAM 으로 MSB 에서 LSB 까지 연속적으로 range matching 을 수행하는 것이 이 논문의 핵심 아이디어이다. 또한 직렬 pass gate 가 큰 지연을 유발하기 때문에, array 를 pipelined segments 로 나눌 것을 제안하였다 [그림 1]. 이 방법은 검색이 일찍 종료될 때 중복 검색을 피하고 pipelining 을 통해 처리량을 증가시킬 수 있다. 이 논문에서는 pipelined range-matching CAM 기술을 적용하여, 65-nm prototype 에서 일정한 85.9-MSps, 1-sample/cycle throughput, 20.6-pJ/sample efficiency, 그리고 -0.03mm² 의 footprint 를 달성했다.
|
 |
| [그림 1] Block diagram of the differential segmented MePLER, schematic of cells and peripherals |
|
EQZ-LDO: A Near-Zero EDP Overhead, >10M-Attack-Resilient, Secure Digital LDO featuring Attack-Detection and Detection-Driven Protection for a Correlation-Power-Analysis-Resilient IoT Device
두번째 논문에서는 side-channel attack (SCA) 복원력을 위한 공격 탐지 및 탐지 기반 보호 기능을 갖춘 digital LDO 인 EQZ-LDO 를 제안했다. 제안된 탐지 기반 방식은 AES 가 공격을 받고 있는 경우에만 보호 기능을 실행하기 때문에 IoT 장치의 수명동안 EDP 오버헤드를 낮출 수 있다. CPA를 장착하기 위해 해커는 일반적으로 무시할 수 없는 저항 (Rnn) (즉, VDDoff-chip-VDDon-chip) 에 걸친 전압 강하를 야기한다. 따라서 각 암호화의 시작 부분에서 Rnn의 존재를 감지하는 것이 중요하다. EQZ-LDO는 미리 정의된 시간(tboost) 동안 0mA에서 미리 정의된 값(Iboost)까지 추가 전류를 소모하여 Rnn에서 IR 강하를 감지하도록 설계되었다. Iboost를 적절하게 설정하면 EQZ-LDO가 넓은 범위의 Rnn (0.1~50Ω, 그림 2-1)을 감지할 수 있다. 또한 tboost를 감지에 의해 소모되는 에너지를 줄일 수 있을 정도로 작게 설정했지만 EQZ-LDO가 다른 전원 노이즈에서 Iboost로 인해 발생하는 전압 강하를 잘 캡처할 수 있도록 충분히 크게 설정했다. 드롭을 감지하면 내장된 이퀄라이저를 활성화하기 위해 보호 명령을 보낸다 [그림 2-2]. 이를 통해 일반적으로 0.5%의 energy-delay-product (EDP) 오버헤드로도 여전히 높은 SCA 복원력을 달성하여 >10M-trace correlation power analysis (CPA) 으로부터 128b AES 코어를 보호해준다.
|
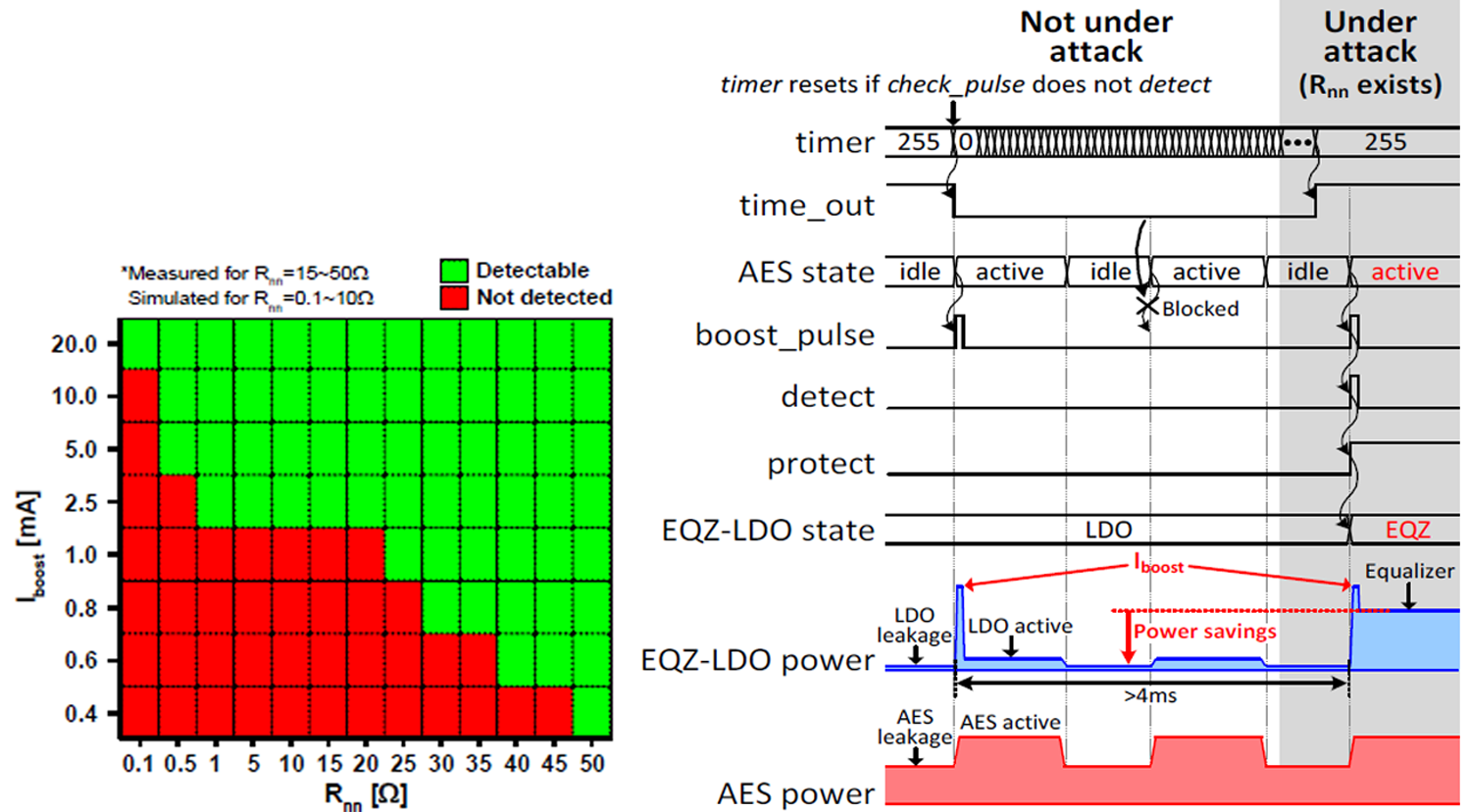 |
| [그림 2] (좌) Rnn vs. Iboost (우) Timing diagram |
|
A 0.186-pJ per Bit Latch-Based True Random Number Generator with Mismatch Compensation and Random Noise Enhancement
세번째 논문에서는 보정 및 피드백 제어가 필요 없는 래치 기반 true random-number generator (TRNG) 를 제안하였다. 이 회로는 불일치 자체 보상 및 random noise 향상 기술을 통해, noise-to-mismatch ratio 를 획기적으로 개선하였다. 최근 저전력, 작은 면적의 장점이 있는 래치 방식의 TRNG 회로가 각광받고 있으나, 인버터 쌍의 불일치 문제는 복잡한 보정 회로와 보상을 위한 피드백 제어 루프를 필요로 했다. 또는 1비트 출력을 위해 수많은 래치 (i.e., 256개) 를 필요로 했다. 이 논문에서는 무보정 래치 기반 TRNG를 제안했다. [그림 3]에 불일치 보상의 개념이 나온다. 일반적으로 한 쌍의 교차 결합 인버터 [그림 3(a)]의 voltage transfer curves (VTC) 는 불일치로 인해 비대칭이 된다. 회로의 초기 상태가 불안정한 점 M(VTC의 교차점)으로 설정되면 동일한 확률로 "1" 또는 "0"의 최종 안정 상태로 안착된다. 상태 "1"과 "0"의 Watershed line 은 항상 M을 통과하며 M의 위치도 불일치 변동에 의해 이동한다. 이때, 그림 3(b)와 같이 초기점 S를 M에 가깝게 설정할 수 있는데, 이 논문에서는 각 인버터의 게이트와 드레인이 연결될 때 equalization 전압인 PL(VeqL, VeqL)과 PR(VeqR, VeqR)을 이용하였다. 즉, Equalization 단계에서 VeqL 및 VeqR 을 각각 래치의 게이트 커패시턴스 CGL 및 CGR에 저장하고, Evaluation 단계에서 드레인 쪽의 기생 커패시턴스 CDL 및 CDR이 전하 재분배를 통해 S의 위치에 영향을 주는 것을 이용해, CGL/CDL(CGR/CDR) 비율을 크게 설정하여 S를 M과 가깝게 만들어 불일치의 영향을 최소화했다. 따라서 제안된 TRNG는 130nm CMOS 공정에서 661 um2 (0.039 MF2)의 코어 면적으로 0.3V에서 0.186pJ/bit의 state-of-the-art 에너지를 달성했다.
|
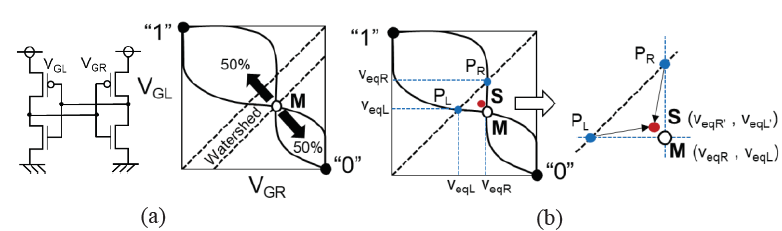 |
[그림 3] Concept of the mismatch compensation.
(a) Voltage transfer curves of inverters pair; (b) position of the initial state S. |
|
All-Digital Closed-Loop Unified Retention/Wake-Up Clamp in a 10nm 4-Core x86 IP
네번째 논문에서는 C1(클럭 게이트 코어), C6(파워 게이트 코어) 및 코어 전압이 유지 전압(VRETENTION)으로 낮아지는 C1LP 상태를 포함하여 코어/IP 에서 전력을 각각 33%/28% 낮춘 10nm 4코어 x86 IP를 제안하였다. 이 IP는 PVT 변동의 영향을 처리하면서도 120ns의 wake up latency 만 소요된다. C1LP는 부분적인 gated 전압 감소를 통해 C1에 비해 누설 전력을 절약하면서 C6에 비해 진입 및 종료 대기 시간을 더 빠르게 만들었다. C1LP 에서는 전력이 제한적이므로 모든 기능을 갖춘 LDO보다 오버헤드가 낮은 고정 클램프가 선호되었다. Open-loop 고정 클램프는 fixed post-silicon-tuned 디지털 코드를 R-ladder 에 적용하여 활성화할 수 있다. 그러나 이 코드는 코어의 OFF(누설) 전류와 유지 중 PPG의 ON 전류 모두에 영향을 미치기 때문에 worst-case PVT 조건에 대해 여유를 가져야 한다. Open-loop R-ladder clamp 는 제한된 코드 범위만 존재하므로 worst-case PVT 변동에서 closed-loop 솔루션을 필요로 한다. 제안된 fully-digital closed-loop 고정 클램프 [그림 4]는 (1) 링-오실레이터(RO) 전압 센서, (2) 전압 슬로프 정보가 추가된 뱅뱅 컨트롤러로 R-ladder 와 PG를 더 세밀하게 조절할 수 있다. 뱅뱅 컨트롤러는 RO 센서의 현재 비트 주파수 (BF(t)) 를 샘플링하고, 이를 기준 비트 주파수 (RBF)와 비교한다. RBF는 RO 센서를 post-silicon 코어 VRETENTION 에서 실행시켜서 한 번만 구한다. Loop 적분기는 1) e(t) = BF(t) - RBF로 정의된 현재 오류 및 2) slope of VGATED = BF(t)-BF(t-i)로 정의된 현재 기울기를 기반으로 VGATED 를 증가, 유지, 감소 중 하나로 업데이트한다. 이러한 fully-digital closed-loop 구현으로 아날로그 구현에 비해, 노이즈에 robust 하고 process-scalable 할 수 있다.
|
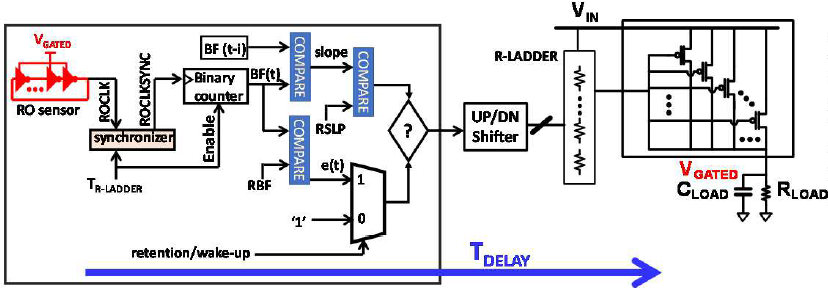 |
[그림 4] Concept of the mismatch compensation.
(a) Voltage transfer curves of inverters pair; (b) position of the initial state S. |
|
A Cost-Effective On-Chip Power Impedance Measurement (PIM) System in 7nm FinFET for HPC Applications
다섯번째 논문은 trig-after-samp를 사용하여 high speed clock 없이 27GHz 속도로 1mV accuracy를 갖고 power distribution network를 측정하였다. On chip에서 Power supply의 power spectral density를 측정하는 방식은 Wiener–Khinchin theorem를 기반으로 2개의 트리거 시점과 샘플링 시점의 정보를 활용한다. 일반적인 PDN 측정 논문들은 ‘samp-after-trig’ 방식을 이용하였는데 이 논문은 그 반대로 이용함으로서 ‘samp-after-trig’ 구조에 존재하던 setup time/hold time 등의 timing margin 문제를 완화하였다 [그림 5-1]. 이렇게 새로운 방식으로 설계된 PIM 시스템 [그림 5-2]은 두가지 본딩 상황, 그리고 programmable한 decap 상황에서 측정되었다.
|
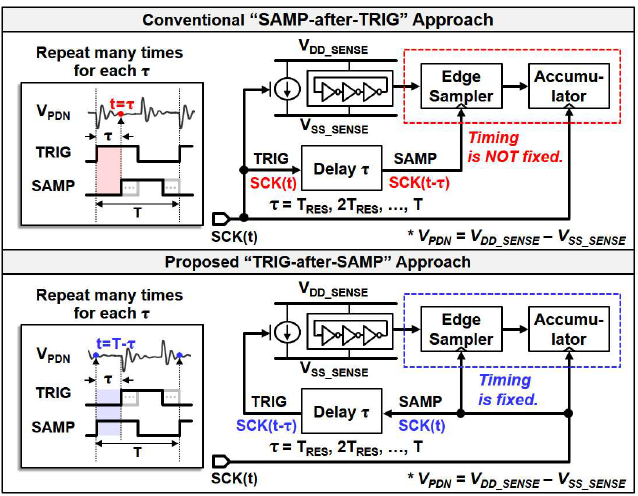 |
| [그림 5-1] ETS approaches for PDN waveform capturing |
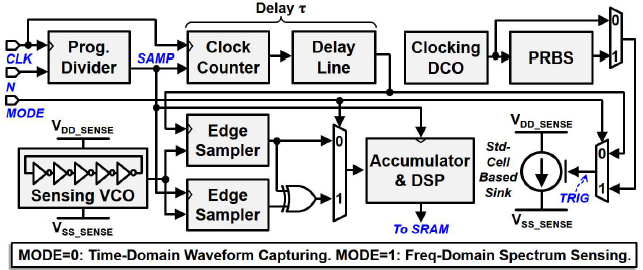 |
| [그림 5-2] High-Level block diagram of the proposed PIM system |
| #Data converters |
|
ㆍSession 14 / Noise-Shaping A/D Converters
ㆍSession 15 / High-Speed ADCs
|
|
Data Converters분야에서는 ADC의 주요 쟁점들( 1) PVT 변화에 둔감한가, 2) 에너지 효율이 높은가, 3) 분해능이 높은가, 4) 고 대역폭인가, 5) 선형성이 높은가 )을 해결한 방법들이 언급되었다. 뒤에 이어질 본문의 내용에서는 몇 개의 논문들을 소개하며 위의 문제들을 해결한 방법에 대해 서술하겠다. FLL을 제안하였다. 이 구조를 통해서 650kHz 에서 1.26pJ/Cycle의 에너지 효율과 1390kHz에서 0.89pJ/Cycle의 에너지 효율을 달성하였다.
A 0.6V 86.5dB-DR 40kHz-BW Inverter-Based Continuous-Time Delta-Sigma Modulator with PVT-Robust Body-Biasing Technique[14-1]에서는 1) PVT 변화에 둔감하고 2) 에너지 효율을 향상시키는 Body-biasing 기술을 제시한다. 디지털 친화적으로 기술이 발달함에 따라 Loop filter의 적분기를 에너지 효율적으로 구현하는 것이 어려운데, 이를 본 논문에서는 Body-biasing 기술이 적용된 인버터 기반 CTDSM(Continuoustime Delta-Sigma Modulators)으로 해결한다. 이 기술이 적용된 프로토타입 CTDSM은 28nm CMOS 공정에서 구현되며, 40kHz 대역폭에서 83dB SNDR, 84dB SNR를 달성하면서 0.6V의 전원에서 33.6uW 밖에 사용하지 않기 때문에 에너지 효율이 높다는 것에 의미가 있다.
OTA-free 1-1 MASH ADC using Fully Passive Noise Shaping SAR & VCO ADC[14-2] 에서는 3) 고해상도이고 5)선형성이 좋은 MASH ADC를 제시한다. 고해상도 일수록 NS-SAR에 쓰이는 샘플링 캐패시터의 크기가 커지는 문제가 발생하는데, MASH 구조에서는 NS-SAR 단계에서 캐패시터의 크기를 줄임으로써 이를 해결한다. 제안된 아키텍처에서는 SAR 단계의 분해능을 줄이고 FPNS SAR에서의 감쇠를 활용하여 VCO의 선형성을 높인다. 65nm 공정을 사용하고 있으며 walden FoM of 23.3fJ/step로 같은 공정을 사용하는 다른 논문들에 비하여 낮다는 특징이 있다.
A 10.0 ENOB, 6.2 fJ/conv.-step, 500 MS/s Ringamp-Based Pipelined-SAR ADC with Background Calibration and Dynamic Reference Regulation in 16nm CMOS[15-1]에서는 조정 시간이 빠른 파이프라인 SAR ADC를 제시한다. 최근 몇 년 동안의 파이프라인 SAR ADC는 rinamp를 굉장히 많이 사용되었으나, 대부분은 추가적인 설계가 더해지고 속도를 희생하면서 PVT 변화를 극복했었다. 그런데 본 논문에서는 PVT 변화를 극복하기 위해 Background calibration을 사용하여 최적화 하는 방법을 설명한다.
|
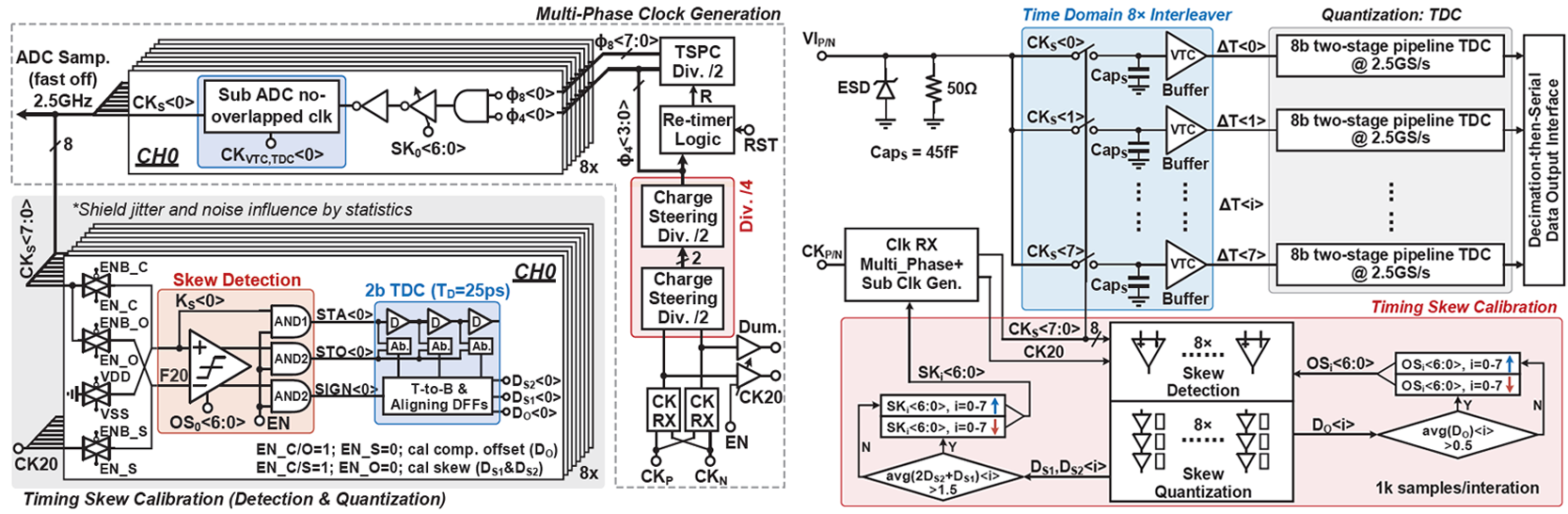 |
[그림 1] (좌) Multi-phase Clock 생성기를 이용한 Background timing skew calibration
(우) 20GS/s 8x interleaved time-domain ADC architecture. |
|
A 20GS/s 8b Time-Interleaved Time-Domain ADC with Input-Independent Background Timing Skew Calibration[15-2]에서는 3)분해능을 높이기 위한 방법을 제시한다. 일반적으로 10GS/s 이상의 분해능을 가지는 ADC에는 Time-interleaved ADC가 불가피하게 사용된다. 하지만 Time-interleaved ADC의 Timing skew를 교정하는 데에는 입력 주파수와 진폭에 따라서 오차가 바뀌기 때문에 다소 까다로운 점이 많다. 논문에서는 이를 Background 구현을 통해 해결한다. 내장되어있는 DAC에서 Calibration 신호를 생성하고 Channel을 교체하여 주기적으로 TI-ADC의 입력 조건이 일관되게 유지되게 한다. 그리하여 24k Sample 에서 -50dB 미만의 timing spur를 억제한다는 점이 의미있다.
|
| #Wireline and optical transceivers |
|
ㆍSession 21 / Ultra-High-Speed-Wireline
ㆍSession 22 / Advanced Wireline Techniques
|
|
본 리뷰는 2021년도 VLSI의 Session 21, Ultra-High-Speed-Wireline에 대한 것이다.
총 5개의 논문이 이번 session 21에서 소개가 되었다. 미국의 Intel과 Xilinx, University of California(Prof. Razavi)에서 각각 1편씩의 논문을 발표하였고[C21-1, C21-2, C21-4], 캐나다의 Huawei Research Center[C21-3], 홍콩의 HKUST[C21-5]에서 나머지 2편의 논문을 발표하였다.
5개의 논문 중 두 편의 논문은 FinFET 공정에서, 나머지 세 편의 논문은 CMOS 공정에서 칩으로 제작되었다. FinFET 공정을 두 편의 논문들은 모두 7-nm 공정을 이용하였고[C21-2, C21-3], CMOS 공정을 이용한 논문들은 각각 10-nm 공정[C21-1], 28-nm 공정[C21-4], 40-nm 공정[C21-5]에서 제작되었다.
이번 Ultra-High-Speed-Wireline session에 소개된 논문들의 큰 trend는 data center의 bandwidth 증가에 대한 수요가 크게 늘어남에 따라, 기존에 많이 사용되던 NRZ Signaling 대신 PAM-4 Signaling 방식을 이용하여 100 Gb/s 이상의 data rate을 지원하는 Transmitter, Receiver의 설계라고 할 수 있다. 최근에 들어 100 Gb/s 이상의 data rate(특히, 112 Gb/s)을 소화할 수 있는 Transceiver(Transmitter + Receiver)들이 여러 논문에 소개되고 있고, 심지어 224 Gb/s data rate을 target으로 한 구조들도 발표되고 있다. 이번 VLSI Session 21에서는 이러한 고속의 wireline 구조에서 낮은 power efficiency(pJ/b)을 가지고 높은 bandwidth를 지원할 수 있는, 성숙해진 Transceiver 들을 확인할 수 있다.
소개된 5편의 논문을 주제별로 살펴본다면, [C21-1]에서는 PAM-4 Receiver Analog Front End(AFE), [C21-2]에서는 PAM-4 Transceiver, [C21-3]에서는 PAM-4 Transmitter, [C21-4]에서는 PAM-4 Clock and Data Recovery(CDR)/DMUX , [C21-5]에서는 PAM-4 Receiver with JTOL CDR(JCCDR)을 각각 주제로 다루고 있다.
5개의 논문에 소개된 주요 idea, techniques에 대하여 간단하게 살펴보겠다.
Session 21-1은 224 Gb/s PAM-4 input을 target으로 한 56 GHz Receiver Analog Front End 구조를 제안하고 있다. 논문에서 제안된 AFE는 input matching network with ESD protection, two-stage hybrid CTLE, VGA로 구성되어 있고 마지막 단의 VGA는 AFE의 characterize를 위하여 interleaved ADC를 drive 하는 것으로 설정 되어있다. 특히, two-stage hybrid CTLE의 경우 linearity와 low to mid frequency zero location control이 우수한 source-degeneration(SD) topology와 동일한 high frequency gain에서 low power을 가지는 inductively peaked topology 두 개를 섞어서 설계를 하였고 총 19dB의 boost를 구현하였다.
Session 21-2는 in-package links에 이용되는 112 Gb/s PAM-4 Transceiver 구조를 제시하였다. 먼저, Transmitter(TX) 경우 4:1 Mux와 2-tap FFE를 이용하여 구성하였다. Clocking architecture의 경우에는 12~16.5 GHz LC PLL을 사용하였다. Receiver(RX) 경우 level shifter, CTLE, 14 slicers, deserializers, PI based baud-rate CDR로 이루어져있다. CTLE에서는 area and metal utilization save를 위하여 active inductor을 이용하였다.
Session 21-3는 106 Gb/s PAM-4 data를 전송하는 Transmitter에 대한 논문이다. 논문에서 제안한 구조는 7-bit DAC-based TX이다. 기존에는 DSP ASIC의 high-speed electrical output과 TOSA(Transmitter Optical Sub Assembly)의 high drive swing requirement 사이에 external driver가 필요하였다. 하지만 TOSA voltage efficiency의 발전으로 인하여 advanced CMOS node로부터 laser을 direct drive 하는 것이 가능해 졌고 본 논문에서는 EML, VCSEL, silicon photonic 등의 optical modulator들을 direct drive 하는 TX를 소개하고 있다.
Session 21-4는 기존 ADC-based PAM-4 Receiver 구조가 가지고 있는 3가지 단점 : 큰 파워 소모, 매우 작은 jitter의 필요성, clock recovery bandwidth와 jitter tolerance의 limitation 을 개선하기 위한 analog receiver(CDR/DMUX) 구조를 제안하고 있다. 이 논문에서는 PAM-4 phase detector(PD), low-power comparator, background offset cancellation technique 세 가지의 idea를 핵심으로 내세우고 있다.
Session 21-5는 jitter transfer(JTRAN)과 jitter tolerance bandwidth(JTOL BW)의 trade-off를 극복하는 jitter compensation CDR(JCCDR)을 포함한 source-synchronous 60 Gb/s quarter rate PAM-4 Receiver에 대한 논문이다. Jitter compensation circuit(JCC)는 delay-locked loop(DLL) filter voltage가 complementary control signal을 생성하도록 이용하고, 이를 통해 complementary voltage-controlled delay lines(C-VCDL)을 조정하여 최종적으로 JTRAN을 상쇄한다.
앞서 언급한 내용처럼, 제시된 5개의 구조들은 높은 data rate을 지원하면서도 power efficient한 지표를 보여주고 있다. 5편의 논문에서 제시한 spec을 확인해 보면 ~100 Gbps의 고속의 data rate을 소화하면서도 power efficiency의 FoM이 2.23pJ/b 이하를 달성한 것을 확인할 수 있다.
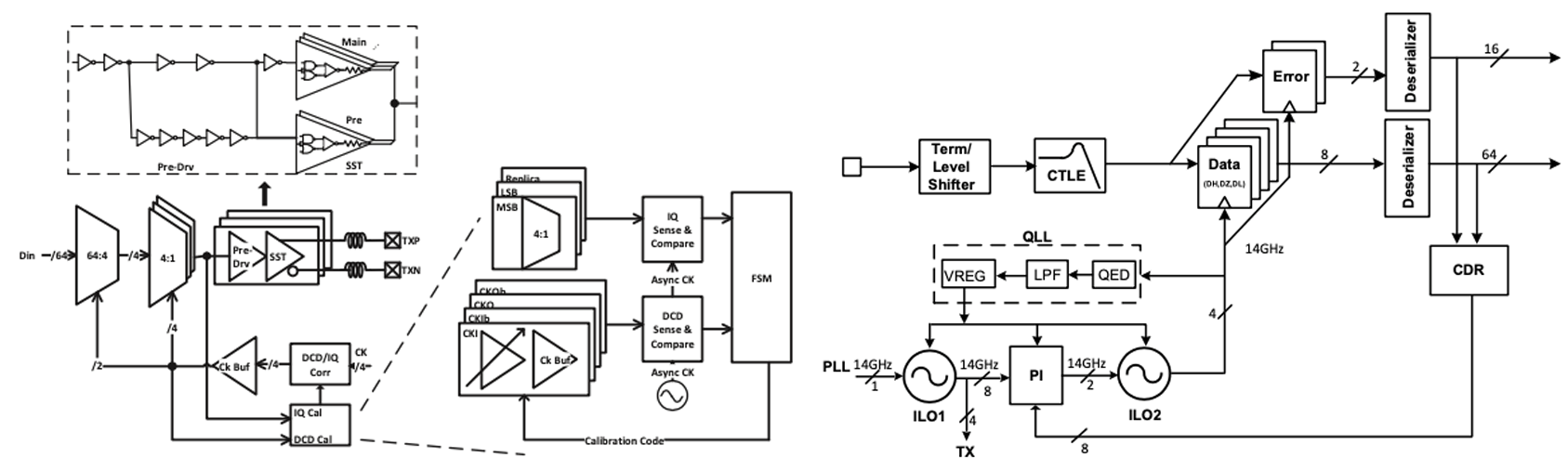 |
| [그림1] (좌) S21-2에서 제시한 Transceiver의 Transmitter, (우)Receiver의 Architecture |
본 리뷰는 2021년도 VLSI의 Session 22, Advanced Wireline Techniques에 대한 것이다.
총 3개의 논문이 이번 session 22에서 소개가 되었다. 미국의 Intel에서 1개[C22-1], Oregon State University에서 2개[C22-2, C22-3]의 논문을 발표하였다. 특히 Oregon State University에서 나온 두 개의 논문[C22-2, C22-3]은 같은 연구실에서 발표한 논문이다.
3개의 논문은 모두 CMOS 공정으로 제작되었다. 그 중 한 편의 논문[C22-1]은 22-nm, 나머지 두 편의 논문[C22-2, C22-3]은 65-nm 공정에서 제작되었다.
이번 Advanced Wireline Techniques session에 소개된 논문들의 큰 trend는 다음과 같다. AI(Artificial Intelligence)와 big data workload의 등장으로 인하여 wireline의 data rate이 112 Gb/s 이상으로 요구되고 있고, 이에 따라 더 큰 baud rate, 더 큰 channel loss, 더 큰 power 소모의 문제가 발생하고 있다. 이런 상황에서 energy efficiency하며 ISI에도 강한 다양한 modulation 기법이나 data encoding 기법을 기반으로 한 transceiver 구조가 나오고 있는 상황이다. 소개된 3편의 논문을 주제별로 살펴본다면, [C22-1]에서는16 QAM Transceiver for dielectric waveguides, [C22-2]에서는 Machine Learning Inspired transceiver, [C22-3]에서는 8-Ary Modulated Wireline Transceiver을 각각 주제로 다루고 있다. 이중에서 [C22-2, C22-3] 두 개의 논문은 기존 NRZ, PAM-4 등 전통적으로 사용하던 modulation 방법 대신 전송할 data를 새롭게 encoding 하거나 modulate 하여 송신하는 scheme을 소개하고 있어서 주목할 만한 논문이라고 생각된다.
3개의 논문에 소개된 주요 idea, techniques에 대하여 간단하게 살펴보겠다.
Session 22-1은 center frequency 134 GHz에서 동작하는 fully packaged waveguide transceiver 구조에 대한 논문이다. 16 QAM modulation과 12 GHz보다 큰 RF BW를 이용하여 single waveguide link에서 50 Gbps data rate를 달성하였다.
Session 22-2는 기존 conventional equalization을 사용하는 ADC-DSP based transceiver 구조에서 bulky한 receiver 단으로 인한 energy efficiency의 문제를 ISI-resilient data encoding scheme을 이용하여 극복한 구조를 제시하였다. 논문에서 제시한 ISI-resilient encoding : hybrid-ternary(HT) coding은 conventional equalization(2-tap FFE & CTLE)와 함께 44.7dB의 channel loss에서 13.8 Gb/s의 data rate를 달성하였다. HT code는 DC 성분이 없는 3-level signal이며 consecutive identical digits(CIDs)가 없고 매 UI에서 항상 transition이 발생한다. HT encoded data가 lossy channel로 전송되면 ISI에 의해 개별 bit이 퍼지게 되고 이를 receiver에서 추출하여 3개의 key features로 구분하게 된다.
Session 22-3는 기존 PAM-8 modulation 방식 대비 SNR과 ISI sensitivity를 향상시킨 8-Ary modulation(SNRE. SNR Enhanced)을 이용한 transceiver 구조를 제시하고 있다. Pulse Amplitude Modulation(ex.PAM-8)은 vertical opening이 감소한다는 단점이 있다. Pulse Width Modulation은 signal의 phase를 조절하는 방식인데 horizontal opening을 감소시켜 jitter에 취약하다는 단점이 있다. 논문에서 제시한 SNRE-8 modulation 방식은 voltage, phase domain 모두에서 modulation을 진행하여 최종에는 PAM-8보다 더 큰 vertical margin과 PWM-8보다 더 큰 horizontal margin을 확보한다. SNRE-8 modulation scheme은 input의 phase modulated(PM) signal이 output에서 amplitude modulated(AM) signal로 변환되는 channel의 특성을 이용한다.
앞서 언급한 내용처럼, 제시된 3개의 구조들은 높은 data rate을 지원하면서도 power efficient한 지표를 보여주고 있다. 3편의 논문에서 제시한 spec을 확인해 보면 고속의 data rate을 소화하면서도 power efficiency의 FoM이 reference로 제시된 논문들 보다 개선된 것을 확인할 수 있다.
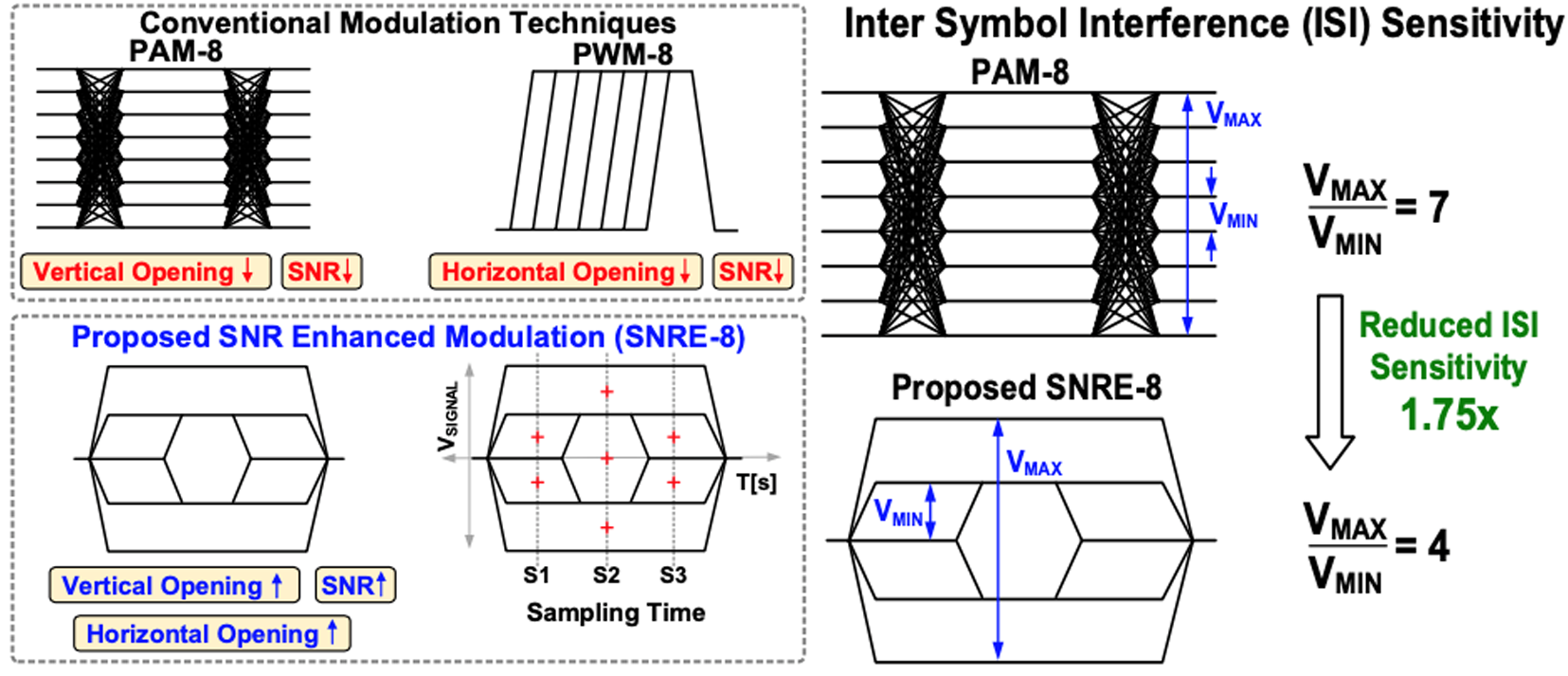 |
[그림2] (좌) S22-3에서 제시한 SNRE-8 Modulation과 PAM-8, PWM-8의 비교,
(우) S22-3에서 제시한 SNRE-8의 기존 PAM-8 대비 ISI sensitivity 감소 |
|
|
| | | | |





