




기획칼럼
제 1기 IDEC 명예기자
강 우 석 성균관대학교 신소재공학부 학사과정
#1. MOS 구조의 트랜지스터가 등장함에 따라서, PMOS, NMOS의 구조를 가지고 있는 MOSFET 디바이스들이 빠르게 발전하기 시작하였고, 둘을 동시에 적용시킬 수 있는 효율성을 갖춘 CMOS가 등장함에 따라서 더욱 빠르게 트랜지스터 시장이 변화하였다. 더 작고 빠른 디바이스들을 원하는 세상의 needs에 맞춰 CMOS의 scaling 기술이 디바이스의 성능을 좌우하게 된다. 7nm node를 넘어서는 기술들 사이에서는 FinFET(Fin Field Effect Transistor) 와 GAA(Gate All Around) nanosheet의 성능들을 살펴볼 수 있다. 250mV 이상의 Vt로 multi-Vt development를 가능하게 하는 두 연구 분야는 앞으로 AI, 5G 세대에 큰 역할을 할 것으로 기대된다. 이와 같은 핵심 차세대 트랜지스터들이 어떤 방식으로 scaling과 Vt 최적화의 장애들을 극복하고 있는지 알 수 있다.
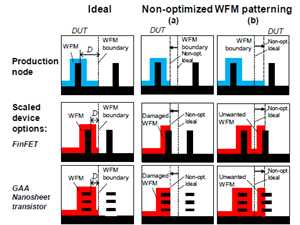
Figure 1. CMOS WFM (Work Function Metal) patterning
Figure 1에서 볼 수 있듯이, 신중한 optimization 없이는 CMOS patterning 과정에서 deviation이 발생할 확률이 높고, 이는 Vt 불안정성에 기여한다. 따라서 optimized WFM (Work Function Metal) patterning이 필요하며, 이를 통해 Vt 범위를 잘 잡을 수 있을 것이다. Cell height scaling 같은 optimized WFM (Work Function Metal) 공정에서는 deviation controlling이 더 유리하고, Vt 범위도 250mV로 늘리는 것도 가능하게 보인다.
CMOS의 발전 성향을 알 수 있었고 트랜지스터들이 항상 겪는 문제인 nano-scaling 과정들이 어떤 후보들로 극복되고, 그 방안들이 어떤 방식으로 시도되고 있는지에 대해서 알 수 있다.

Figure 2. GAA NS transistor (7-stacked channel)
#2 훌륭한 gate controllability와 높은 current drivability를 보이는 7 level stacked GAA nanosheet 트랜지스터에 대해서 알아볼 수 있다. FinFET의 scaling reduction에서 한계를 보이면서, GAA nanosheet stacking 기술이 제안되기 시작하였다. GAA stacking 트랜지스터는 우선 우수한 gate controllability를 보여주고, effective channel width 덕분에 우수한 DC 효율성을 보여준다. 또한 디자인 flexibility도 높으며, 다양한 종류의 metal들을 선정할 수 있기 때문에, Vth의 다양한 분포를 보여준다. Epitaxial growth를 동반한 fabrication 과정도 성공적으로 진행되었음을 알 수 있다. 우수한 Vt 와 더불어 Rtotal 로 인한 current 역시 우수한 성능을 보여 current drivability가 2 layer stacked 일 경우보다 3배가량 증가한 성능을 확인할 수 있다.
#1에서 언급된 GAA nanosheet transistor에 대한 자세한 모습과 성능적 측면을 확인할 수 있었다. 전형적인 fabrication 뿐만 아니라 다양한 방면의 공정 과정이 미치는 성능적 변화가 매우 인상적이다.
#3 이미 우수한 FinFET 성능에도 불구하고, Vth와 기존 누설전류로 인해 0.75V 이하로 떨어지지 않는 Vdd로 인해서 CMOS는 power efficiency에서 한계를 보인다. CMOS의 low temperature operation을 통해서 트랜지스터의 여러 성능을 제어하는데 긍정적인 thermal 효과를 찾아볼 수 있었다. 우선, long channel transistors들은 77K가량의 온도에서 낮은 phonon scattering 효과로 인해서 상향된 mobility를 보였다. 또한, lightly doped 트랜지스터들은 우수한 transconductance와 gate controllability의 결과를 보여줬다. 회로 상으로 볼 경우 Cu wire는 300K(RT)에서 77K로 temperature drop을 할 경우 훨씬 낮은 저항값을 갖게 되며, 실리콘의 thermal conductance 역시 6배로 증가하기도 한다. 이는 낮은 Vdd를 보인다는 점을 고려하였을 때, self-heating 으로 인한 energy loss, 즉 power savings에 대한 효과가 증대될 수 있는 장점도 있다.
#1에서 언급된 FinFET가 또다른 모습으로 상향된 성능을 보이는 모습이 인상적이다. 흔하게 fabrication이나 다른 materials들을 합성하여 성능적 변화를 도모하는데, temperature change를 가하여 성능에 차이를 보는 방법도 있음을 알 수 있었다. 77K면 거의 영하 200도 가량인데, 조금 궁금한 점은 해당 온도에서 쓰일 transistor의 적용성이나, 해당 circuit이 온도를 유지할 수 있는 방안에 대해 생각해 볼 필요가 있을 것 같다.
#4 다양한 방안의 CMOS 공정이 존재한다. JL FDSOI (Junction-Less Fully Depleted Silicon-On-Insulator) 트랜지스터 역시 그 중 하나로, operation 특성들과 drain current variability에 대해서 보여준다. JL 트랜지스터는 P doped Si 반도체에 SOI layer를 epitaxial growth 한 후 도핑하는 방식으로 일반적으로 생성한다. 채널 도핑과 S/D 저항의 상호관계를 최소화시키기 위하여 JAM (Junctionless Accumulation Mode) 트랜지스터의 형태로 만들기도 한다. Figure 3를 참고하여 schematic 한 그림들을 확인할 수 있다. Local variability, total variability에 관련하여 알아볼 수 있는 electrical 특성들도 확인할 수 있다. Offset을 보여주는 측면, IM보다 JL, JAM 구조들이 우수한 variability 측면 등 우수성보다는 연구 진행중인 JAM/JL 특성들 위주로 확인할 수 있다.
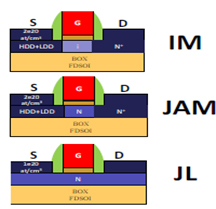
Figure 3. IM, JAM, JL의 schematic
신소재공학부 학부생으로서 반도체 공학에 관련하여 다양한 공부를 경험하며 CMOS에 대해서도 어느정도 배울 수 있었는데, 처음보는 구조들, fabrication method와 우수한 성능을 찍어낼 수 있는 방법들에 대해서 흥미롭게 볼 수 있었던 것 같다. NMOS PMOS의 한계를 넘어 한꺼번에 역할을 수행할 수 있는 CMOS 구조로 발전시킨 근황에 이어 벌써 다양한 방식으로 연구가 진행되는 모습이 놀랍다. 미래의 5G, AI 시대에 더 nano-scaled 되어 작고, 더욱 성능이 우수한 칩들이 요구가 됨에 따라 물리학적 한계를 극복하기 위한 다양한 연구가 진행되고 있음을 알 수 있다. CMOS 공정에 epitaxial growth 같은 새로운 접근법이 궁금하다면 논문을 더 참조해봐도 될 것 같다.
은 남 경 성균관대학교 신소재공학부 학사과정
2020 IEEE VLSI Session TF1에서는 총 5편의 논문이 발표되었고 이들은 주로 다양한 종류의 FeFET들의 성능을 향상시킬 수 있는 방법을 제시하고 있다. 논문들은 이전에 비해 더욱 효율적으로 memory window(MW)를 향상시킬 수 있는 방법과 함께 HZO FeFET, Si FeFET, HfO2 FeFET등의 여러 기존 트랜지스터의 key behavior에 관해 더욱 세밀히 분석하여 이를 보완한 새로운 개념의 모델을 제시하고 있다.
# TF1.1Session TF1.1는 high-k AlON을 이용하는 인터페이스 공학을 기반으로 하여 더욱 큰 memory window와 함께 long pulse cycling에 대해 강한 내구성을 가진 FeFET 모델을 제시하고 있다. 이러한 AlON 기반 메모리는 일반적인 FeFET에 비해 더욱 큰 memory window, 최대 10년까지의 내구성, 10-4 s의 긴 pulse width 등의 훨씬 발전된 특징을 가지며 뛰어난 성능을 보여주게 된다. 저자는 FE-HZO와 SI사이에 high-k AlON을 IL로 사용하여 이러한 결과를 도출하였으며 사용된 AlON은 더욱 작은 voltage drop과 적은 hole trapping을 발현하는데 도움을 주게 된다. 다음의 [표 1]은 기존의 FeFET에 비해 여러 방면에서 향상된 성과를 보이는 AlON 기반 메모리의 특성을 잘 나타내고 있다.
![[표 1] 기존 FeFET와 AlON 기반 FeFET의 memory performance 비교](./2020/07/resources/images/sub/02/02_04.jpg)
[표 1] 기존 FeFET와 AlON 기반 FeFET의 memory performance 비교
Session TF1.2는 memory window와 HfO2 FeFET의 신뢰도를 spontaneous polarization (Ps)과 interface trap charge (Qt)를 메모리 작동 중에 직접 추출해내는 새로운 기술을 통해 재시험하는 방법을 다루고 있다. 이를 통해 Ps의 증가와 안정화가 memory window와 보존력의 향상에 상당히 중요하다는 결과를 보여주며 SiO2를 활용하여 전위의 주입과 추출을 최대한 막는 것이 더 뛰어난 내구성을 보이는데 핵심 요소임을 설명한다.
# TF1.3Session TF1.3에서는 결론적으로 크게 2가지의 새로운 결론을 제시한다. 먼저 매우 얇은 FE층을 가진 경우에는 bulk charge trapping이 크게 의미가 없어 내구성의 변화에도 거의 영향을 미치지 못한다는 점이다. 또한 negative gate biases의 적용 도중에 고온의 전자로 인한 홀 데미지가 FeFET에서의 memory window와 내구성을 크게 낮추는 주요한 원인임을 설명한다. 따라서 FeFET의 내구성을 유지시키고 또 더욱 향상시키기 위해서는 고온 전자의 수를 줄이기 위한 설계가 필요함을 역설하고 있다.
# TF1.4Session TF1.4는 FeFET의 주요 반응들에 관하여 상당히 세밀하고 분석적으로 설명한 논문이라고 생각된다. 저자는 [그림 1]과 같이 geometry scaling, device-to device variation, stochasticity, accumulation의 크게 4가지의 관점을 기준으로 디바이스의 성능을 분석하였고 이 관점들을 모두 충족시키는 새로운 모델을 제안한다. 이 모델은 추후 디바이스의 최적화와 적용에 더욱 효과적으로 사용될 수 있을 것이다.
![[그림 1] FeFET 분석의 핵심적인 4가지 관점인 scalability, variation, stochasticity, accumulation](./2020/07/resources/images/sub/02/02_05.jpg)
[그림 1] FeFET 분석의 핵심적인 4가지 관점인 scalability, variation, stochasticity, accumulation
Session TF1.5는 FeFET의 특성을 파악하는데 있어 정확한 polarization state를 얻는 것이 핵심임을 설명하고 있다. 이는 또한 p-FeFET과 n-FeFET간의 memory window 차이를 설명해 줄 수 있는 주요한 근원이라고 할 수 있다. [그림 2]와 같이 Si FeFET의 polarization-charge coupling에서 전자와 홀의 분극에 대한 서로 다른 행동은 비대칭적인 P-V loop와 함께 p-FeFET에서만 보이는 높은 전도 전하밀도의 원인이 된다.
![[그림 2] (a) p-FeFET과 (b) n-FeFET의 polarization switching에서의 전자와 홀의 반응](./2020/07/resources/images/sub/02/02_06.jpg)
[그림 2] (a) p-FeFET과 (b) n-FeFET의 polarization switching에서의 전자와 홀의 반응
강 우 석 성균관대학교 신소재공학부 학사과정
#1.Transistor 내부에는 다양한 용도로 (dielectric, doping mask, insulator 등) oxide 층들이 구조적으로 많이 분포되어 있다. BEOL(Back-end of Line)1% W-doped In2O3 성분의 옥사이드를 gate로 사용한 transistor의 성능을 분석하고, IWO DGFET(W-doped Indium Oxide Dual Gate Field Effect Transistor) 가 BEOL 트랜지스터로써 높은 성능과 promising한 후보임을 알 수 있다.
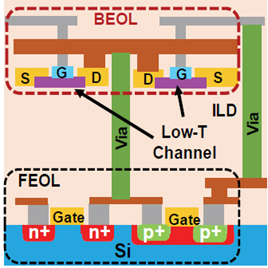
Figure 1. IWO DGFET schematic
IWO DGFET는 높은 Ion/off 비율을 보여주며, BG(Back-gate) FET보다 1.9배가량 높은 saturation을 보여준다. 또한 페르미 레벨을 mobility edge(Em)보다 높게 위치하게 함으로써 높은 mobility를 갖춰 우수한 성능에 기여하는 점을 확인할 수 있다. 또한 BEOL과의 우수한 compatibility를 확인할 수 있으므로, BEOL monolithic 3D integration에서 in-situ 트랜지스터 형성에 우수한 기여를 할 것으로 예측한다.
트랜지스터에서 더없이 중요한 옥사이드 층에 대한 연구를 확인할 수 있었다. 옥사이드 층의 성분에 대한 testing을 통해 성능적 면모를 확인하는 동향을 알 수 있었다.
#2 높은 BEOL compatibility 덕분에 넓은 application 영역을 보여주며, 높은 mobility로 인한 성능을 보여주는 IGZO(In-Ga-Zn Oxide) 반도가 3D vertical FeFET영역에 우수한 후보로 자리잡고 있다. 하지만 effective channel legnth로 인한 nano-scaling의 한계가 있고, 줄어드는 채널 크기가 Vt의 negative effect를 준다는 한계점이 있다. 이러한 dissociation energy가 Al-O가 더 높다는 점과 안정적인 OS channel로 인한 shortening 한계를 낮출 수 있는 점으로 우수한 IAZO (In-Al-Zn Oxide)로의 대체에 대해서 확인할 수 있다. In-Al adjustment로 인해 더 높은 current 발생을 확인할 수 있고, 높은 thermal stability (~420℃)와 여전히 높은 mobility (12.7〖cm〗^2/Vs)를 보여준다. 이처럼 IAZO는 scaling적인 한계의 극복과 더 높은 성능의 가능성을 보여주는 후보임을 알 수 있다.
#1, #2에 이어서 BEOL과의 compatibility 가 높은 물질 위주의 연구가 진행되는 동향을 확인할 수 있다. Scaling 한계를 극복하기 위한 다양한 노력들도 확인할 수 있다.
#3 IPMA를 사용하는 MTJ의 utilization이 커짐에 따라, STT-MRAM(Spin-Transfer Torque Magnetoresistive RAM)의 수요가 급증하고 있다. 이에 따라 더 높은 reliability와 우수한 속도와 용량을 갖춘 MRAM이 요구되고 있는데, 최신 STT/SOT(Spin-Orbit Torque) MRAM들의 발전 동향에 대해 알 수 있다. 기존 MRAM 공정에서는 열적 안정성이 더욱 우수해야 하고, SRAM에 미치는 높은 속도를 따라가야 한다. 우선 Novel Damage Control 공정 과정으로 인해 low-damage, low-temperature 공정을 통해 더욱 안정적인 양산을 바라보고 있다. 또한 Quad interface MTJ technology로 scaling을 강화하여 우수한 성능을 갖출 수 있었다. 물질을 교체하지 않고 20nm를 넘어선 scaling을 위해서는 필수적인 과정일 것으로 확인된다. SOT-MRAM의 효능을 구체화시키기 위하여 magnetic field-free writing 실험을 진행하였고, 높은 열적 안정성을 보임을 확인하였다. 이처럼 20nm를 넘어선 scaling을 갖춘 SOT/STT MRAM의 연구는 향후 CMOS의 우수한 성능에 크게 기여할 것으로 보인다.
다양한 회로 측면의 기기들을 종합적으로 발전시켜 우수한 circuit을 만들기 위한 연구의 동향을 확인할 수 있다. 항상 문제가 되는 것이 scaling 측면인 것 같다. 나노 공학 측면에서의 적용성이 앞으로 중요한 연구 과제가 될 것이라는 생각이 든다.
은 남 경 성균관대학교 신소재공학부 학사과정
2020 IEEE VLSI Session TH3에서는 총 5편의 논문이 발표되었으며 3D integration에 활용할 수 있는 여러 기술들이 발표되었다. 이러한 기술들은 #3.3과 #3.4와 같은 일반적인 CMOS 디바이스에 적용될 수 있는 기술부터 #3.5의 IoT 기술과 연동된 사람의 피부에 적용가능한 기술에 이르기까지 다양한 분야가 소개되었다.
# TH3.1Session TH3.1의 저자는 imec’s N14 플랫폼을 활용하여 300mm 웨이퍼 기판위에서 최초의 획일적인 3D complementary field effect transistor(CFET)을 구현하였다. 이러한 monolithic CFET과정은 연속적인 과정에 비해 훨씬 경제적이며 미래 기술 node에 필요한 궁극적인 장비의 범위확장을 가능하게 한다는 의의를 갖는다. 또한 sequential CFET에 비해 훨씬 뛰어난 성능을 보여주며 최고의 CMOS scaling을 가능하게 하는 기술이 될 것이다.
![[그림 1] Monolitic CFET과 sequential CFET의 생산단가 비교](./2020/07/resources/images/sub/02/02_08.jpg)
[그림 1] Monolitic CFET과 sequential CFET의 생산단가 비교
3D sequential integration에서 가장 최고급의 장비들은 525℃이하의 저온 프로세스에 최적화 되어있다. 저자는 이때 excimer laser anneal과 strained silicon을 활용하여 더욱 뛰어난 성능을 얻을 수 있는 방법에 대해 소개하고 있다. 또한 이러한 strain으로의 laser anneal의 효율성을 설명하며 이에 대한 투자가 필요함을 얘기하고 있다. 이러한 laser anneal은 n, p 타입의 dopant를 전부 활성화시킬 수 있으며 CMOS공정에도 적용이 가능하다는 장점을 갖고 있다.
# TH3.3Session TH3.3에서는 3D sequential integration을 위해 28nm FDSOI CMOS technology(FEOL과 BEOL)에서의 열적 안정성이 중요함을 처음으로 발표하였다. 실험을 통해 28nm FDSOI CMOS와 Cu/ULK BEOL은 500℃ 2시간의 공정에서 제일 안정하며 이러한 환경에서 제일 나은 성능과 결과물이 나오는 것을 보이고 있다. 이러한 열적 안정성을 통해 3D sequential integration에서의 Cu/ULK의 도입은 더욱 활발해질 것으로 예상된다.
# TH3.4Session TH3.4 또한 #3.3과 유사하게 온도와 관련하여 500℃이하의 저온 CMOS장비에서의 RO 와 SRAM bitcell에 관하여 설명하고 있다. 이러한 기술들은 더욱 향상된 성과를 보여줄 수 있는 3D sequential CMOS integration으로의 발판이 될 수 있을 것이다.
# TH3.5Session TH3.5에서는 IoT기술과 접목하여 인간의 신체에 적합하도록 유연하게 적용할 수 있는 3D 센서를 위한 CMOS기술에 관하여 다루고 있다. 이러한 신기술은 polymide substrate(PI)를 활용하여 더욱 유연하고 투명하다. 쌓을 수 있는 Si-MOSFET, CMOS inverter와 6T-SRAM은 유연한 PI를 형성하고 laser anneal과 super CMP과정을 통해 인체의 피부에 적용가능한 IoT 칩에 가동될 수 있다.
![[그림 2] Schematic illustration of flexible monolithic 3DIC](./2020/07/resources/images/sub/02/02_09.jpg)
[그림 2] Schematic illustration of flexible monolithic 3DIC
송 충 석 세종대학교 전자정보통신공학과 학사
본 세션에서는 resistive random access memory(이하 RRAM)를 인공지능(AI) application에 적용한 사례를 발표한 논문이 3편이 실렸다. RRAM은 저항기반 메모리로 상태에 따라(고저항상태, 저저항상태) 전도도가 바뀌는 특징을 이용하여 0,1을 저장할 수 있다. 특히, 외부전압이 사라져도 상태정보가 남아있는 비휘발성 특성을 가지고 있어 차세대 메모리로 각광받고 있다. 비휘발성 특성과 더불어 빠른 속도, 간단한 구조, 높은 집적도 등으로 주 메모리인 SRAM, DRAM을 대체 할 수 있다고 평가받고 있다. 근래에는 소자특성을 향상시키는 연구뿐만 아니라 기계학습 가속기에 접목시키는 연구가 활발히 이루어지고 있다. 본 세션에 실린 논문 3편 모두 RRAM을 기계학습에 적용한 사례에 관한 내용이다.
#TM2.1 : A SiOx RRAM-based hardware with spike frequency adaptation for power-saving continual learning in convolutional neural networks
본 논문은 SiOx RRAM 기반 하드웨어를 제작하여 기계학습을 수행한 것으로 크게 두가지 특징이 있다. 첫번째는 “stability-plasticity dilemma” 를 극복했다는 것으로 인간의 뇌는 새로운 data가 들어오면 기존 학습했던 정보를 바탕으로 새로운 data를 추가학습하고, 중요도에 따라 단기기억을 장기기억으로 변화시키는 경향이 있다(중요한 data는 오래 기억하려고 함). 그러나 artificial neural networks(이하 ANN)는 새로운 data를 학습시키면 이전 data에 대한 정확도가 낮아지는 현상이 존재했다(catastrophic forgetting 현상). 즉, 새로운 data의 학습은 훌륭하게 해내지만, 지식 전이가 잘 이루어지지 않는 유연성이 떨어진다고 볼 수 있는데 이를 “stability-plasticity dilemma”라고 한다. 따라서 본 논문에서는 이를 극복하기 위해 지도학습(CNN)과 비지도학습(SNN)을 모두 RRAM을 이용하여 수행하여 이 문제를 극복하였다.
두번째는 spike frequency adaptation(신경자가억제)(이하 SFA) 을 구현했다는 것이다. 인간의 뇌는 fire rate가 지나치게 높아지면 자체적으로 낮추려는 경향이 있는데, 이 효과로 불필요한 spike fire을 막아 에너지를 효율적으로 소모할 수 있게 한다. 이를 ANN에서 구현하면 전력소모를 낮출 수 있는데, 이 논문에서는 spike가 fire 되면 RRAM 소자가 자체적으로 set으로 변화하여(LRS 상태)서 내부 임계전압 값이 올라가 fire가 쉽게 되지 못하게 설계하였다.
그림 1(a)는 지도학습단에서 CNN 학습을, 비지도학습단에서는 SFA를 적용한 winner-take-all(WTA) 방식을 표현하였다. CNN 필터는 4bit weight를 matrix vector multiplication(MVM) 연산으로 training을 하였고(그림 1(b),(c)) 그 계산 결과를 FPGA에서 max pooling하여 asynchronous spike-timing-dependent plasticity(A-STDP)로 작업을 수행하게 했다(그림 1(d)).
본 논문에서 제시한 새로운 RRAM 기반 하드웨어를 이용하여 학습시킨 결과 stability-plasticity dilemma를 극복함과 동시에 SFA를 적용해 효율적인 연산을 가능케 하였다. 또한 MNIST, noisy N-MNIST, Fashion MNIST, CIFAR-10 dataset에 대하여 실험한 결과 각각 99.3%, 96%, 93%, 91% 정확도를 확인하였다.
![[그림 1] 본 논문(TM2.1)에서 제시한 RRAM 기반 하드웨어 구조도](./2020/07/resources/images/sub/02/02_10.jpg)
[그림 1] 본 논문(TM2.1)에서 제시한 RRAM 기반 하드웨어 구조도
본 논문은 matrix vector multiplication(이하 MVM) 연산을 voltage sensing 하는 RRAM 기반 회로를 구현한 결과를 발표했다. 기존 MVM 연산은 current를 sensing하여 연산 결과를 확인했지만 이 current sensing 방식은 sensing 하는 동안에는 계속 current를 흘려주어야 하는데 이는 sensing 동안 전력소모가 지속된다는 문제가 있고 더불어 회로에 사용되는 트렌지스터가 너무 많다는 단점이 있었다. 반면에 voltage sensing은 parasitic capacitance의 충전, 방전을 이용하기 때문에 전류를 계속 흘려줄 필요가 없어 전력소모가 낮다. 그러나 기존의 voltage sensing 방식은 MVM 결과가 명확하게 나오지 않는다는 문제가 존재했다.
기존 voltage sensing 방식은 그림 2(a) 처럼 두 source line(SL) 전압차로 sensing하지만 충, 방전 속도가 다르기 때문에 같은 임피던스 조건하에도 결과가 다르게 나오는 문제가 있었다. 따라서 본 논문에서는 그림 2(b)처럼 source line을 한 개만 두어 voltage를 sensing하는 방안을 제안했고 그에따라 충, 방전속도가 다른 문제가 나타나지 않게 되었다.
실험에 사용한 weight scheme은 2가지로 Scheme 1은 양의 conductance와 음의 conductance로 weight를 표현하였고, scheme 2는 중간 conductance(g_m/2)를 기준으로 두 개의 weight를 표현했다. 기본적으로 SNR 성능이 scheme 1이 더 좋았고 두 scheme 모두 row의 개수가 많아질수록 정확도가 떨어짐을 확인했다.
1번의 Multiply-accumulate(MAC) 당 파워 소모는 current sensing 시 10ns의 pulse를 가했을 때, 7.81fJ에 비해, voltage sensing 시에는 scheme 1이 2.32ns pulse를 가했을 때 2.16fJ, scheme 2는 1.78ns pulse를 가했을 때 2.35fJ로 측정되어 약 3.3~3.6배 정도 파워를 절약한 것을 확인하였다.
![[그림 2] 기존 RRAM 기반 voltage sensing 구조(a), 본 논문(TM2.2)에서 제시한 voltage sensing 구조(b)](./2020/07/resources/images/sub/02/02_11.jpg)
[그림 2] 기존 RRAM 기반 voltage sensing 구조(a), 본 논문(TM2.2)에서 제시한 voltage sensing 구조(b)
본 논문은 세계적인 foundry 기업인 TSMC에서 발표한 논문으로 기업체에서 발표한 논문답게 상업적으로 적용할 수 있는 Read Disturb 모델을 제안했다. RRAM은 컨덕턴스에 따라 HRS(고저항상태), LRS(저저항상태)의 두가지 상태를 가지게 되고, 이 두 상태를 이용하여 메모리를 저장한다. 즉, 이 두 상태가 반드시 구분되어야 하는데, 현존하는 RRAM은 메모리 사이즈가 커짐에 따라 tail bits가 존재하여 두 상태의 구분이 어려워지는 경우가 존재한다. 특히 HRS상태에서 이 문제가 두드러지는데 그에 따라 read disturb(읽기 방해) 문제가 생긴다.
즉, RRAM을 상업적으로 상용화시키기 위해서는 이 read disturb를 고려한 설계가 필요한데 본 논문에서는 read disturb현상을 current shift ratio(δ)를 이용하여 수치화했다. 더불어 이 수치화한 데이터를 토대로 어떤 조건에 의해서 read disturb현상이 주로 발생되는지를 알아냈다.
앞서 언급했듯이 tail bits 현상은 HRS에서 나타나고, 또한 외부전압을 여러 번 sweep할수록 덜 나타난다. 따라서 본 논문에서는 HRS상태의 zero sweep(time-zero) 상황에서 δ를 조사했다. δ를 수치화한 식은 그림 3과 같고, 본 논문에서는 read voltage의 pulse width는 20ns이하, amplitude는 0.3V 이하가 mega bit level에서 read disturb현상을 최소화하는 조건이라고 발표하였다.
![[그림 3] 본 논문(TM2.3)에서 제시한 current shift ratio eqn.](./2020/07/resources/images/sub/02/02_12.jpg)
[그림 3] 본 논문(TM2.3)에서 제시한 current shift ratio eqn.
은 남 경 성균관대학교 신소재공학부 학사과정
2020 IEEE VLSI Session TN1에서는 다양하고 새로운 FET기술들과 이를 활용한 장비들이 중점으로 소개되었다. 특히 기존의 2D 평면 구조의 한계를 극복하기 위해 도입된 3D구조의 공정 기술인 FinFET공정을 활용한 신제품들도 상당수 발표되었다.
# TN1.1이 논문에서는 플로팅 게이트 Ion-Sensitivities Field Effect Transistor (ISFET)가 통합된 새로운 모발형 나노 구조가 최초로 시연되었다. 16nm FinFET기술에 내장된 해당 판독회로를 통해 이 이온 검출기는 높은 감도와 넓은 범용성을 가지며 실시간으로 액체 시료에서 pH농도와 나트륨 이온농도를 분석할 수 있는 능력을 갖추고 있다.
![[그림 1] floating gate ISFET과 ion sensor의 TEM 분석사진](./2020/07/resources/images/sub/02/02_13.jpg)
[그림 1] floating gate ISFET과 ion sensor의 TEM 분석사진
Session TN1.2 또한 #1.1과 같이 FinFET기술에 대하여 발표하였으며 neural network (NN)에 관하여 서술하고 있다. Neural network는 주로 복잡한 FinFET회로에서 자체 가열을 모델링하는 데 사용된다. 이러한 네트워크는 특히 설계최적화와 같은 높은 계산속도가 필요한 응용분야에 적합하여 앞으로 FinFET기술을 활용하는 데 더욱 널리 쓰일 것으로 기대된다.
![[그림 2] neural network를 활용한 FinFET회로의 SH prediction](./2020/07/resources/images/sub/02/02_14.jpg)
[그림 2] neural network를 활용한 FinFET회로의 SH prediction
Session TN1.3에서는 충전 트래핑(CT) FinFET장치의 확률적인 단기 복구를 활용하여 난수 생성기의 한 종류인 true random number generator (TRNG)를 구현하였다. 이러한 CT-TRNG는 현재 가장 유망하고 신뢰도가 높은 하드웨어 보안 솔루션의 방향성을 충분히 제시할 수 있는 기틀을 마련하였다는 평가를 받았다.
# TN1.4Session TF1.4 또한 #1.3과 유사하게 매우 고속이면서 제약으로부터 자유로운 TRNG의 설계를 시연하였다. 이는 총 3가지의 결과를 보여주는데 첫 번째로 동기화되지 않은 oscillator와 주입된 동기화 신호 사이의 임의의 위상차는 subharmonic injection locking (SHIL)하에서 2개의 불규칙적이고 안정된 위상으로 붕괴된다는 점이다. 두 번째는 SHIL하에서 양자화된 oscillator는 대칭적이고 메모리가 없다는 점으로 인해 상관이 없는 랜덤의 비트를 발생시킨다는 것이다. 마지막으로 이 oscillator phase TRNG는 oscillator의 플랫폼과 관련없는 일반적인 설계를 따른다는 점을 나타낸다.
# TN1.5Session TF1.5에서는 기존의 VS-FPGA에서 ASIC으로 더욱 빠르고 생산가격이 낮은 방법으로 이주하기 위해 이름의 “VS”를 “On”으로 바꾸는 hard via가 새롭게 제안되었다. 이는 VS-FPGA와 동일한 기본 mask layer를 더욱 저렴한 비용으로 공유할 수 있도록 제작되었다. 또한 매우 광범위한 칩 볼륨을 커버할 수 있는 능력을 가질 것으로 예상된다.
![[그림 3] SRAM-FPGA의 atom switch 와 via switch FPGA로의 발전과정](./2020/07/resources/images/sub/02/02_15.jpg)
[그림 3] SRAM-FPGA의 atom switch 와 via switch FPGA로의 발전과정
Session TF1.6의 저자는 neuromorphic 응용을 위한 FeFET의 메모리효과와 비선형성을 활용한 computing utilizing에 의한 새로운 AI기반 계산 방식을 설명한다. 이는 데이터의 작업 동작을 게이트 전압 입력을 위한 그레인 전류의 시간 응답을 가상의 노드로 취하면서 입증하였다. 따라서 이 기술은 입력된 데이터를 분류하는 능력이 실험적으로 검증되었다고 볼 수 있다.
![[그림 4] FeFET를 활용한 reservoir computing 과정](./2020/07/resources/images/sub/02/02_16.jpg)
[그림 4] FeFET를 활용한 reservoir computing 과정
권 예 린 서울과학기술대학교 전기정보공학과 학사과정
#JFS1.1은 Ayar Labs에서 발표한 논문으로, ASIC 패키지에서 바로 광 I/O 인터페이스를 가능하게 하는 전기광학 플랫폼인 TeraPHY chiplet을 소개했다. 약 51M 트랜지스터와 수백 개의 광디바이스로 구성되어 있는 TeraPHY chiplet은 45nm Silicon-on-Insulator(SOI) CMOS 공정으로 만들어진다. 그림1에서 보면, chiplet은 5.5x8.9㎟ 작은 크기로 호스트인 ASIC과 통신하기 위해 Advanced Interface Bus(AIB)를 사용한다. 고속 디지털/아날로그 회로, 광변조기, 광검출기, 도파관을 통합시키면서 송수신기에서 데이터 전송속도 최대 25Gbps를 가진다. 총 32개의 채널로 구성되며, 각 파장당 16Gbps 그리고 각 포트당 8 동시파장을 가진다고 발표했다. 여러 개로 쪼개진 chiplet 사이의 연결이 느려질 수 있는 칩렛 디자인의 문제점을 극복하여 빠른 연결 속도를 보여준 것에 의의가 있었다.
![[그림 1] TeraPHY chiplet (a) and single-die-package with (b) and without lid (c)](./2020/07/resources/images/sub/02/02_17.jpg)
[그림 1] TeraPHY chiplet (a) and single-die-package with (b) and without lid (c)
#JFS1.2은 Photonics Electronics Technology Research Association와 AIO Cor에서 발표한 논문으로, 높은 온도에서 동작하는 Chip-Scale Silicon-Photonic Transceiver를 제안했다. transceivers가 밀집하게 통합되어 LSI 주변의 임베디드 광학 모듈과 같이 실제 적용을 위해선 고온 환경에서 사용할 수 있어야 한다. 이에 논문에서는 온도 보정 기능을 갖춘 고도로 통합된 고속 silicon-photonic transceivers고온 작동을 입증했다. 광송수신기가 quantum-dot laser diode, optical pins, 28nm CMOS의 하이브리드 통합으로 가능해진 하나의 실리콘 플랫폼으로 통합되었다. 고온에서 동작하기 위해 modulator driver와 transimpedance amplifier에서 온도보상기능이 구현된다. 이 온도보상기능으로 85℃에서 오류없이 25 Gb/s × 4개 채널 데이터 전송을 성공적으로 입증했다고 발표했다.
![[그림 2] Measured 25-Gb/s eye diagrams of the electrical outputs of Rx at 25, 55, and 85°C](./2020/07/resources/images/sub/02/02_18.jpg)
[그림 2] Measured 25-Gb/s eye diagrams of the electrical outputs of Rx at 25, 55, and 85°C
#JFS1.3은 IBM에서 발표한 논문으로, 90nm SOI CMOS에 단일 집적 전기 제어 회로가 내장된 최초의 완전 포장 silicon photonics 8×8 스위치를 제시한다. 상업용 전자 패킷 교환 ASIC는 지난 15년 동안 100배 이상 대역폭 확장을 해왔지만 전력 효율 상승은 이에 미치지 못하고 있다. 이에 논문에서 제시한 8×8 실리콘 광학 스위치는 디지털 직렬 인터페이스로 전기 포장 부담을 줄이고 디지털 모니터링 및 제어 기능을 제공하며 포트 확장성을 가능하게 한다. 스위치는 2×1과 2×2 Mach-Zehnder 스위치(MZS)로 구축된 non-blocking 네트워크다. 180 DAC는 MZS를 조정하고 112 ADC는 피드백 제어를 위해 네트워크를 통해 광전력을 측정한다.
![[그림 3] Block diagram of the 8×8 switch chip](./2020/07/resources/images/sub/02/02_19.jpg)
[그림 3] Block diagram of the 8×8 switch chip
![[그림 4] (a) Photograph of the 8×8 switch chip and (b) packaged switch module mounted on test PCB](./2020/07/resources/images/sub/02/02_20.jpg)
[그림 4] (a) Photograph of the 8×8 switch chip and (b) packaged switch module mounted on test PCB
#JFS1.4는 삼성에서 발표한 논문으로, 타의 추종을 불허하는 CMOS 호환성과 뛰어난 열 관리 기능을 갖춘 III/V-on-bulk-Si 기술을 제시했다. III/V-on-bulk-Si은 적은 비용으로 III/V-on-SOI 기술에 비해 우수한 성능을 발휘한다. CMOS 기반 VLSI가 성공적이었지만, 기기 설계와 프로세스가 더 복잡해지고 비용이 많이 들면서 업계의 수익성이 낮아져 추가적인 기술 발전이 어려워지고 있다. 데이터 대역폭이 폭발적으로 증가하고 에너지 소비량이 증가하면서 소형 기기의 열 관리 문제가 발생하는 것을 극복하기 위해 silicon photonics (Si-P) 기술에 대한 관심이 높아 지고 있다. bulk-Si은 SOI보다 40% 낮은 열 임피던스를 가져 효율적인 방열과 온도에 민감한 III/V 장치의 더 안정적인 작동이 가능하다.
![[그림 5] Brief comparison of the SOI and bulk-Si integration platforms](./2020/07/resources/images/sub/02/02_21.jpg)
[그림 5] Brief comparison of the SOI and bulk-Si integration platforms
#JFS1.5는 Imec사에서 발표한 논문으로, 220nm Si 도파관 플랫폼에 통합되어 결합된 최초의 O-밴드 QCSE-EAM를 제시했다. Quantum-Confined Stark Effect (QCSE) electro-absorption modulator는 초박형 strain-relaxed 완충기로 만들어진 strain-balanced GeSi 양자 우물/장벽 stack을 기반으로 하는 장치이다. Stack 두께가 450nm 밖에 되지 않아 초미세한 실리콘 도파관의 광결합을 가능하게 한다. 1350nm에서 1V 구동 전압에 대해서만 최대 8dB의 소멸율을 보여 저전력, 광대역, 고밀도 광통신의 가능성을 입증했다.
benchmarking of device performance of Ge/GeSi QCSE EAM presented in this work and literature
| Device | Total Stack | Device type | Length | Bias swing | λ (nm) | IL(dB) | ER(dB) | Device FoM |
|---|---|---|---|---|---|---|---|---|
| [4-5] | >10μm | Stand alone | 100 μm | 4Vpp | 1300 | 2.5 | 5 | 2 |
| Dev 1 | <0.5 μm | WG integrated | 40 μm | 1Vpp | 1350 | 16 | 8 | 0.5 |
| Dev 2 | <0.5 μm | WG integrated | 80 μm | 2Vpp | 1465 | 15 | 7.3 | 0.5 |
송 충 석 세종대학교 전자정보통신공학과 학사
초창기의 기계학습은 소프트웨어 기반으로 많은 데이터를 이용해 방대한 양의 연산을 하여 학습시키고 그에 따라 정확도를 올리는 방향으로 개발되어 왔다. 그 결과 현재 많은 Neural Networks가 개발되었고, 정확도는 평균 90퍼센트 이상의 좋은 성능을 보여주고 있다. 그러나 기계학습의 연산은 현재 PC 체계에 적합하지 않은 요소가 있어 전력소모면에서 비효율성을 야기시키고 있다. 이에 따라 하드웨어 측면에서의 발전이 더불어 요구되는 상황이다. 본 세션에서는 기계학습의 연산을 하는데에 있어 전력소모, 칩 면적, latency를 줄이는 방향의 하드웨어 설계 아이디어가 제시되었다.
#CA1.2 : A 617TOPS/W All Digital Binary Neural Network Accelerator in 10nm FinFET CMOS
본 논문은 binary neural network(이하 BNN)을 하드웨어 칩으로 설계하여 구현한 결과를 발표하였다. BNN은 weight와 activation 함수를 binary로 표현하는 것으로 표현용량이 작아짐에 따라 메모리 효율성이 증가하는 장점이 있는 기계학습 네트워크이다. 본 논문에서는 compute near memory(이하 CNM), parallel inner product compute, near-threshold voltage(이하 NTV) 연산을 이용하여 에너지 효율을 증가시켰다.
먼저 NVM은 memory와 MAC 연산하는 부분을 sub-array로 구성하는 것으로 이 sub-array를 하나의 bank라고 하여 이 구성이 4개가 되면 4bank가 되는 구조이다(그림 1(a)). Bank를 많이 둘수록 weight를 access하는 파워와, 저장된 데이터를 찾는 파워도 줄어들게 되는데 본 논문에서는 8bank로 설계하였다. 또한 본 논문이 제시한 BNN 칩은 외적이 아닌 내적을 이용해서 accumulation과 reduction을 수행하는데 외적으로 계산하는 것에 비해 약 13배의 에너지 효율을 만들어 냈다(그림 1(b)). NTV는 설계에 들어가는 트랜지스터의 threshold voltage의 근처에서 작동을 시키는 것으로, threshold voltage보다 훨씬 큰 전압으로 작동을 시키면 에너지측면에서 비효율이 발생한다. 따라서 threshold voltage 근처에서 작동을 시키는 설계를 하였고 그 결과 0.75V 동작 아래 2.3배의 효율을 발생시켰다. 더불어 기존 6T SRAM이 아닌 8T register를 사용했고, 파이프라인을 적용했다(그림 1(c)).
![[그림 1] 본 논문(CA1.2)에서 제시하는 CNM, inner product, NTV의 design point](./2020/07/resources/images/sub/02/02_22.jpg)
[그림 1] 본 논문(CA1.2)에서 제시하는 CNM, inner product, NTV의 design point
본 논문에서 설계된 칩은 10nm FinFET CMOS 공정으로 compute density는 418TOPS/〖mm〗^2 (TOPS : Tera operations per second), memory density는 414KB/〖mm〗^2으로 설계되어 기존의 칩 모델보다 2.8~135배 더 높았고, 에너지효율은 617TOPS/W 로 2.7배 증가시켰다.
#CA1.4 : A 4.45ms Low-latency 3D Point-cloud-based Neural Network Processor for Hand Pose Estimation in Immersive Wearable Devices
본 논문에서는 hand pose estimation(이하 HPE)을 처리하는 Neural Newtork Porcessor를 발표하였다. HPE는 단어 뜻 그대로 손동작을 인식하고 그에 따라 의미 및 의도를 추정하는 기술로 wearable device에 접목시키기에 매우 유용한 기술이다.(예를 들어 상대방이 수화로 대화를 시도할 때, wearable device가 수화로 대화하는 것을 인식하고 의미를 해석하는 과정이 HPE라고 할 수 있다.) 이 기술의 핵심은 단연코 latency(지연)를 줄이는 것에 있는데 현재 GPU는 약 20.5ms의 latency를 가지고 있다. 이는 사용자가 매우 어색함을 느낄 수 있는 시간으로 5ms 이하의 latency를 가지는 것이 핵심이다.
손동작을 인식하기 위해서는 3D depth sensor를 이용하여 센싱하고 point-cloud-based neural network(이하 PNN)로 처리한다. PNN은 센서로부터 받은 무질서하게(unorder) 분산되어 있는(scatter) 3d image raw data를 처리하는 neural network로 본 논문에서는 low latency(<5ms) PNN processor를 제안하였다.
제안된 processor는 3종류의 코어를 병렬로 설계하여 latency를 낮추었다. 첫번째 코어는 window-based sampling-grouping(WSG)을 담당하는 코어(SGC)로 8bit streaming image를 불러들여서 WSG 연산을 하고 두 번째 코어(CC)에서 그 결과를 global weight memory를 이용해 convolution을 한다. 마지막 코어(MPPC)는 max pooling을 하는 코어이다(그림 2).
![[그림 2] 본 논문(CA1.4)에서 제시한 heterogeneous core 구조](./2020/07/resources/images/sub/02/02_23.jpg)
[그림 2] 본 논문(CA1.4)에서 제시한 heterogeneous core 구조
위의 heterogeneous core 구조를 가지는 processor는 65nm CMOS 공정으로 만들어졌고, 1.2V 동작하에 최대 120MHz 클럭 주파수를 가졌다. 프로세스 수행 결과 4.45ms latency 성능을 보였는데 이는 GPU 프로세서보다 4.61배 빠른 것이다.
#CA1.5 : A 〖3mm〗^2 Programmable Bayesian Inference Accelerator for Unsupervised Machine Perception using Parallel Gibbs Sampling in 16nm
지도학습은 많은 데이터를 이용해 정확도를 올려야 하는 한계가 존재하는 반면, 비지도학습은 적거나 정확하지 않은 데이터를 가지고도 학습을 할 수 있기 때문에 미래 AI 기술에 핵심이 될 것이라고 평가받고 있다. 특히, Bayesian model은 이 부분에 강점을 가지고 있지만, 현재 CPU 하드웨어에서 병렬처리가 되지 않는 문제가 있어 새로운 하드웨어 설계가 필요하다.
본 논문에서는 Gibbs sampling(두개의 확률변수를 결합하여 한 개의 표본(결합확률변수)을 생성하는 확률 알고리즘. 결합확률변수를 모를 때 이미 알고 있는 확률분포에 깁스 샘플링을 적용하면 해당 결합확률분포를 알 수 있음.)을 이용한 Bayesian inference 가속기를 제안했고 4가지 2D Markov Random Field(이하 MRF)에 대해서 성능을 분석하였다.
기존의 Gibbs sampling은 순차적으로 MRF를 업데이트하기 때문에(이전의 값이 존재해야만 업데이트가 가능) 병렬화가 어려웠지만, 비동기 Gibbs sampling(AGS)(MRF를 분리하여 update하는 방식)와 동기 Gibbs sampling(CGS)(MRF를 선택적으로 독립시켜 update하는 방식)을 사용하여 병렬처리가 가능하도록 가속기를 설계하였다.
![[그림 3] 본 논문(CA1.5)에서 이용한 MRF와 iteration에 따른 MSE(좌), 여러가지 Gibbs sampling에 대한 MSE(우)](./2020/07/resources/images/sub/02/02_24.jpg)
[그림 3] 본 논문(CA1.5)에서 이용한 MRF와 iteration에 따른 MSE(좌), 여러가지 Gibbs sampling에 대한 MSE(우)
그 결과 3가지(traditional, asynchronous, chromatic(synchronous)) 샘플링 모두 비슷한 결과에 수렴하였다. 비동기 샘플링 방식은 다른 2가지 방식과 같은 정확도가 되기 위해선 더 많은 iteration을 필요로 했지만 비동기 방식은 병렬화가 가능하며, 메모리부분에서 동기방식에 비해 장점이 있기 때문에 단점을 보완할 수 있는 방식이라고 판단된다. 설계하드웨어는 동작전압 0.8V에서 450Mhz 클럭을 가지며 0.88nJ/sample에서 44.6MSamples/s 만들어냈다.
김 관 태 한국과학기술원 전기및전자공학부 박사과정
1.1 논문은 Univ. of Virginia에서 발표된 multi-modal sensor interface에 관한 논문이다. Wearable 심혈관계 질환 (CVD) 모니터링을 위한 low-power PPG/ECG/ozone multi-modal sensor interface의 구현을 target으로 잡았다. Multi-signal sensing platform이면서 전체적인 low-power를 달성했다는 점은 이 논문의 장점이고, nW range의 ozone sensor가 발표되었다는 점에서 의의가 있다. 하지만, 논문에서 제대로 언급되지 못한 review point들이 몇 가지 있다.
첫째로, 이 논문의 핵심인 low-power PPG sensor 회로의 경우, LED의 current driving power를 줄이기 위해 단순히 current 값을 낮추는 접근을 하였다. 이 경우 PPG readout의 SNR도 함께 떨어지기 때문에 오히려 단점이 될 수도 있다고 봐야할 것이다. 이 issue는 ECG/ozone monitoring sensor들의 경우에도 마찬가지인데, comparison table의 다른 work들에 비해 전체적인 noise 성능도 낮은 편이고 ADC의 resolution도 6bit으로 healthcare application 치고는 상당히 낮은 편에 속한다.
둘째로, 제안된 regulated cascode TIA의 핵심은 bias current로 TIA gain을 구현한다는 것인데, resistor를 쓰지 않고도 4MΩ의 높은 gain을 구현하고 resistor-less approach로 인한 low-noise 성능을 달성하였다 (45pARMS over 5Hz BW). 하지만, bias current를 잡아주는 current mirror 단의 PVT variation 때문에 TIA의 gain이 일정하지 않게 구현될 수 밖에 없다는 치명적인 단점이 있다. 이 문제를 어느정도 보상하기 위해 regulated current mirror의 design을 논문에서 제시하고 있지만 이는 완전한 해결책이 아니며 PVT robustness에 대한 어떠한 simulation 및 measurement result도 없기 때문에 TIA의 practical use에 다소 의문이 생긴다.
셋째로, analog-digital DC servo loop을 통한 low-noise cancellation loop의 구현은 이미 지난 논문(U. Ha, JSSC'18, J. Lee, JSSC’19)에서 제안된 scheme이므로 new feature라 할 수 없다. 여담으로, chip photograph의 core circuit block들을 흰 박스로 가려놓은 것이 조금 의아한 (?) 논문이다.
1.2 논문은 IMEC/CMST/Ghent Univ./KU Leuven 에서 발표된 인공 홍채 렌즈에 관한 논문이다. 홍채 질환이 있어 동공의 수축 및 이완이 힘든 환자들을 보조하기 위한 system을 target으로 잡았다. 4개의 동심원 모양 LCD를 인공 홍채로 만들어, light range detector의 출력에 따라 단계적으로 여닫는 방법을 사용하여 수축 및 이완 기능을 구현하였다. Thin film interconnect 등을 사용하며 contact 렌즈 형태의 system으로 구현되었지만, power management unit이 없고 communication circuit 또한 single-chip integration이 되지 않았다는 점에서 지난 해 POSTECH에서 발표된 smart contact 렌즈 system (VLSI’19)에 비해 system 완성도가 다소 떨어지는 부분은 아쉽다.
Light range detector의 구현은 on-chip photo-diode에 흐르는 current를 current DAC와 같은 branch에 흐르도록 하여 결과로 나타나는 voltage를 monitoring하는 방식으로 구현되었다. 총 4-level의 digital output이 나오면 이 signal들이 4개의 동심원 LCD를 control하는 방식이다. LCD controller circuit은 high voltage를 generation하는 charge pump로 구현되어 13V의 output을 driving하며 LCD를 단계적으로 켜거나 끈다.
발표된 IC는 light illumination에 따라 184nW-4.2μW의 전력을 소모하며, ambient light를 1.2lux-190klux range에서 detect할 수 있어 기존 work들에 비해 low-power, high-dynamic range를 달성하였다.
1.3 논문은 Princeton Univ.에서 발표된 소화가능한 알약 IC에 관한 논문이다. 제안된 알약 system은 인체 내로 들어가 fluorescence-based bio-molecular sensing을 하며, 최종적으로는 의사의 진단까지 소모되는 시간을 줄인다. 혈액 샘플 채취 후 bulky한 장비에서 분석을 하는 기존의 lab-based DNA/RNA sensing 및 진단 방식에 비해 더 편리하고 더 자주 진단이 가능한 형태를 기대할 수 있고, 이는 올해의 가장 큰 issue 중 하나였던 COVID-19 진단 방식과도 연관이 되어 있다. 제안된 system은 FDA 승인을 받은 capsule 알약 내에 1.55V/12.5mAh의 battery, fluorescence sensing을 위한 laser LED 및 readout chain, 인체 외부와의 통신을 위한 915MHz ISM band TRx 및 antenna 등이 구현된 형태를 갖고 있다. 본 논문에서 IC에 on-chip integration part는 fluorescence readout과 RF TRx이다. 제안된 IC의 power는 Rx mode에서 0.86mW, Tx mode에서 1.4mW를 소모한다.
이 논문의 아쉬운 점이 있다면, capsule 형태의 알약 system은 인체 내에 들어갔을 때에도 정상적인 동작을 하는 것을 증명해주는 것이 중요한데, 관련한 in-vivo 혹은 in-vitro demonstration report가 전혀 없다는 것이다. w/ person, w/o person 환경에서 (w/ 혹은 w/o person이 무엇을 뜻하는 것인지도 제대로 설명이 되어있지 않다) Tx power 및 BER 측정 결과는 report가 되어있으나 캡슐이 인체 내에서 동작하는 환경을 제대로 modeling하고 측정이 이루어진 것인지 의문이 든다.
1.4 논문은 UCSD/Harvard Univ./KAIST에서 발표된 neural interface system에 관한 논문이다. 1024 array (32×32)로 구성된 이 chip은 multi-channel bio-potential signal recording에만 focus를 두던 기존 논문들과는 달리, 1024개의 element마다 voltage/current clamp, recording이 가능한 회로들을 구현하여 2mm×2mm single-chip으로 선보였다는 점에서 의의가 있다. Recorded signal은 column access를 통하여 32개의 ADC로 digitization된다.
특히, 이 chip의 ADC array는 LSB-first incremental SAR 구조로 구현되었는데, 소개된 ADC의 energy 소모량은 signal slope에 dependency를 가지므로 slow signal에 대해서는 cycle 개수가 줄어든다는 특징이 있다. 즉, 빠르게 변화하는 input에 대해서는 energy가 높아지고 느리게 변화하는 input에 대해서는 energy saving이 가능하며, 이 논문에서는 11 ENOB 기준 일반 SAR ADC에 비해 60%의 energy saving이 가능하다고 말한다. Application도 neural interface인데, 마침 소개하는 feature 자체도 input sparsity dependent power gating과 관련이 있고 이 feature는 최근 deep neural network (DNN) accelerator 논문들의 가장 큰 design approach 중 하나이기도 하기 때문에 더욱 흥미롭게 느껴진다.
이 chip에서 소개하는 incremental SAR ADC는 1mV/ms 이하의 slope을 가지는 대부분의 neural recording signal (LFP, EcoG, dopamine 등)들에 대해 일반 SAR ADC보다 2배 이상 낮은 2fJ/level의 FoM을 가진다. 구현된 ADC와 함께, 이 논문의 voltage/current clamp front-end IC는 0.82μW/ch의 power, 0.0039mm2/ch의 area, 12.5kHz의 BW, 2.88의 NEF를 달성하였다.
다만, 같은 group에서 2년전 소개된 ISSCC’18 work과는 달리, demonstration이 in-vitro 환경에서 진행되었다는 점은 아쉬운 부분이다.
1.5 논문은 invite를 받아 Sony/Tohoku institute of technology에서 발표된, neuronal network analysis를 위한 multi-electrode array (MEA)에 관한 논문이다. 선보인 system에는 236,880개의 electrode가 집적되었는데, element 당 pitch가 11.72μm 수준이다. 236,880개의 electrode가 집적된 만큼, 전체 chip area도 32.5mm×25.1mm에 달한다. Chip내 집적된 ADC 회로들은 65nm die와 90nm die로 분리하여 분포되어 있는데, analog part는 65nm die에, digital part는 90nm die에 집적하여 stacking을 하는 형태로 연결을 하였다. Single slope ADC로 구현된 이 chip은 1.336GHz의 clock frequency에서 동작하며, 12bit/5.5μVRMS over 300Hz-10kHz(Action potential)의 performance를 보인다. 실제 쥐의 neural recording을 통해 imaging 결과까지 report를 하였는데, 높은 집적도에서 많은 electrode를 구현한 덕분에 neuronal firing과 axonal propagation의 imaging이 성공적으로 이루어질 수 있었다고 말한다.
김 유 빈 한국과학기술원 전기및전자공학부 학사과정
본래 automotive SoC는 여러 외부적 요인과 넓은 범위의 OPP를 포괄하는 안전성과 효율성을 필요로 한다. 빠르고 정확한 모니터링을 위해 AVS와 ABB, SoC-integrated BiMA 등이 제시되었으나, 성능을 제한하는 AVS 최고 전압, 넓은 OPP 범위에 따른 낮은 효율성 등 여러 문제점이 존재했다. 이번 연구는 AVS 최고 전압 근처에서 SoC가 동작하도록 non-body biased에 의한 속도 포화를 없애고, 높은 에너지 효율을 구현하도록 ABB의 누출을 막았다. 그림1은 LP, MP, HP일 때 OPP 모드의 여러 특징을 보여준다. 연구가 제시한 design optimization에 의하면, AVS, ABB, BiMA를 혼합함으로써 SoC의 에너지 효율을 올릴 수 있다.
![[그림 1] Multi OPP optimization table and measured results](./2020/07/resources/images/sub/02/02_25.jpg)
[그림 1] Multi OPP optimization table and measured results
기존의 linear/buck/shunt regulators는 시간에 종속적인 SCA suppression을 제공했다. 하지만, 랜덤 마스킹 같은 arithmetic countermeasures나 이종의 Galois-fields는 주파수를 바꾸어 시간에 종속적이지 못하다. 이번 연구는 AES 스펙트럼을 바꾸어 기존의 선형적 LDO에 가까울 만큼 band leakage를 줄여냈는데, 모든 시간과 주파수에 일정한 side-channel suppression를 갖고 있는 AES 엔진을 개발했기에 가능한 일이었다. 1900×와 1100× SCA 저항이 각각 사용되었으며, 아래 그림은 기존의 randomized NL-DLDO에 최종적으로 AES engine을 이어주었을 때 trace 개수와 상관관계의 변화를 보여준다.
![[그림 2] Randomized NL-DLDO cascaded with arithmetic countermeasures](./2020/07/resources/images/sub/02/02_26.jpg)
[그림 2] Randomized NL-DLDO cascaded with arithmetic countermeasures
Strong Physically Unclonable Functions (PUF)는 비용이 적은 IoT edge device의 보안을 보장한다. 아래 그림에서 보이듯이, PUF 회로에는 많은 쌍의 Challenge-Response Pairs (CRP)가 내재될 수 있다. 각각의 CRP는 검증되지 않은 channel을 보증하는 역할을 수행할 수 있으며, 하나는 한번의 replay attack을 방어할 수 있다. 전형적인 PUF는 ML이나 DNN에 기반한 modeling attack에 취약하나, 이번 연구는 이러한 한계를 어느 정도 극복하였다는 데 그 의의가 있다.
![[그림 3] Randomized NL-DLDO cascaded with arithmetic countermeasures](./2020/07/resources/images/sub/02/02_27.jpg)
[그림 3] Randomized NL-DLDO cascaded with arithmetic countermeasures
Public-key의 암호화는 교환이나 디지털 서명의 무결성을 뒷받침하는 중요한 알고리즘이다. 512b 이하의 짧은 ECC의 경우, 낮은 latency에도 동일한 수준의 보안이 가능하나 양자 컴퓨터의 공격은 막을 수 없다. 4096b 보다 긴 길이의 키를 사용하는 RSA 암호 시스템이 등장한 이유다. 하지만 이런 암호 시스템도 power/EM SCA에는 취약했고, exponent/message binding countermeasures는 단일 추적 공격을 막아내지 못했다. 이번 연구는 단일/중복 추적 공격을 모두 방어할 수 있는 14nm CMOS RSA-512/1K/2K/4K crypto 프로세서를 제안한다. 아래 그림은 해당 프로세서의 구조도다.
![[그림 4] SCA-resistant RSA crypto-processor organization](./2020/07/resources/images/sub/02/02_28.jpg)
[그림 4] SCA-resistant RSA crypto-processor organization
송 주 미 성균관대학교 신소재공학부 석사과정
물리적 센서(physical sensors)는 신호를 이용하여 주변의 물리적 공간을 측정하는 수단을 제공한다. #3.1에서는 평판 디스플레이의 다양한 터치 감지 방법 중, 상호 정전 용량 방식 터치 스크린 패널 (TSP) 시스템서의 센서에 대해 언급한다. 기존 연구에서 획득 한 터치 신호를 판독하기 위해 최첨단 터치 컨트롤러 IC가 성공적으로 개발되었으며 터치 감지 외에도 3D 호버 감지, 스타일러스 펜, 압력 감지등과 같은 새로운 기능을 TSP에 추가하려는 여러 시도가 있었다. 본 논문에서는 기존 상용 TSP를 사용하여 사용자가 인식 할 수 는 터치 센서 IC를 제시하고 있다. 또한 공명 중심 FRE 기술과 클램핑 줌인 통합기는 넓은 동적 범위 (DR)를 달성하기 위해 활용됨을 제시하고 있다. 프로토 타입 칩은 TS 및 FRE 모드에서 각각 6.7 인치 TSP로 측정 된 37.5dB-SNR 및 50.7dB-DR을 제공하며 FRE 데이터에 SVM (Support Vector Machine) 학습을 적용하여 500 개의 학습주기 후 5개의 서로 다른 사용자 핑거 프린터를 97.7 %의 정확도로 성공적으로 분류하여 다중 사용자 협업 터치 인터페이스에 신뢰할 수 있는 사용자 차별화 기능을 제공함을 제시하고 있다. #3.2에서는 저전력 IoT 애플리케이션을 위한 에너지 효율적인 압-저항 압력 감지 시스템을 제시 하고 있다. 압-저항 센서는 저렴한 비용과 내구성으로 인해 가장 널리 사용되어 왔으나 전원을 공급해야 한다는 점이 다른 유형의 센서와 비교할 때 중요한 단점이 된다. 이는 센서 크기 (1–10 kΩ)에 따라 브리지 저항이 감소하여 전력 소비가 증가함에 따라 폼 팩터가 작은 IoT 시스템에 특히 중요합니다. 소형 IoT 배터리의 높은 내부 저항으로 인해 이 문제가 더욱 악화된다는 문제가 있으며 최근 이 문제를 해결하기 위해 브리지의 듀티 사이클 구동에 관한 제안이 되었다. 이 논문은 소형 IoT 시스템을 위한 높은 듀티 사이클 하위 범위의 휘스톤-브리지 (WhB) 기반 압력 센서를 제시하고 있다. 샘플링 된 브리지 출력을 증폭시키고 비율 계량 오프셋 시프트를 사용하여 하위 범위와 ADC 동작을 가능하며 오프셋 시프트 및 ADC는 LDO에 의해 구동되는 샘플링 된 여기 전압을 사용하고 있다. 제안된 센서는 듀티 사이클링 및 하위 범위를 채택하여 높은 에너지 효율과 정확성을 달성함을 실험적으로 보여주고 있다. #3.3은 터치 응용 제품을 위한 저전력 와전류 변위 센서에 대해 설명하고 있다. 와전류 센서(ECS)는 종종 고해상도 변위 감지에 사용되는데 용량성 센서와 비교하여 습도와 먼지에 강하고 갈바닉 절연도 가능하다는 장점이 있다. 이것은 안전이 중요시되는 터치 어플리케이션에서 좋은 요소이지만 이전의 고해상도 설계의 높은 전력 소비(> 10mW) 및 여러 센서 노드가 필요한 것이 단점으로 작용합니다. Fig 1a에 도시 된 바와 같이, 갈바닉 절연 터치 센서는 LC 발진기의 일부를 형성하는 감지 코일 근처에 금속 호일을 배치함으로써 실현 될 수 있다. 코일의 AC 전류는 호일에 와상 전류를 유도하여 터치가 호일 / 코일 간격을 줄이면 진폭이 증가된다. 이를 통해 코일의 인덕턴스 및 품질 계수가 감소하고 발진기의 출력 진폭 및 주파수가 변경된다. 논문에서는 500μm의 스탠드 오프 거리에서이 센서는 43μm 범위에서 3kHz 대역폭으로 6.7nm 분해능을 달성합니다. 1.8V 전원에서 200μW를 소비하는데, 이는 최신 기술에 비해 35 배 향상된 성능을 나타냅니다. #3.4에서는 기본 파운드리 패시베이션 층이 이온 민감층으로 사용되는 이온 민감 전계 효과 트랜지스터 (ISFET)와 기준 전계 효과 트랜지스터 (REFET)쌍을 사용하는 완전 통합형 pH 센서 IC를 제시한다. 많은 생체 의학 응용 분야에서, 이식 가능한 pH 센서는 생체 내에서 pH 변화의 장기적이고 정확한 판독 값을 제공하기 위해 작은 변위 부피, 낮은 전력 소비 및 높은 감도를 가져야 한다. 기존의 pH 센서는 이온 교환막으로 덮인 전극을 채택하는데, 이 전압 출력은 pH 버퍼 매체에서 동일한 전극에 대해 선형으로 변화하여 cm 스케일 부피가 큰 계측으로 이어진다. ISFET 장치의 도입으로 상용 IC 파운드리에서 하나의 칩에 있는 데이터 처리 전자 장치 및 무선 전송 회로와 pH 센서를 직접 통합하여 크기와 비용을 최소화 할 수 있는 기회가 제안되었으며 ISFET와 REFET를 쌍으로 연결하면 pH에 대한 무시할만한 감도를 보여 주면서 용액의 잠재적 인 변화를 추적하는 REFET과 함께 이러한 센서의 pH 특이성을 더 증가시킨다. 본 논문에서는 FET의 딥 서브 레스 홀드 영역의 I-V 특성을 활용하는 의사 차동 소스 팔로워 (pseudo-differential-source-follower)와 유사한 ISFET 프론트 엔드 토폴로지를 제안하여 pH 감도 손실없이 초 저전력을 가능하게 한다. 완전 집적 회로는 0.85 mm2의 영역 내에서 0.72 nW 만 소비하므로 전력, 샘플링 주파수 및 감도가 4000 배 이상인 pH 데이터를 제공하므로 최소 침습적 생체 내 pH 감지에 이상적인 결과를 보여주고 있다. #3.5에서는 빔 포밍 및 피처 추출에 대해 안정적인 음성 인식에 필요한 높은 SNR을 제공한다. 심층 신경망의 발전으로 인해 자동 음성 인식 (ASR)이 실용화 되었지만 실제 응용 시나리오에서 환경 소음과 간섭을 억제하려면 여러 마이크를 사용한 음향 빔 포밍이 필수적이다. 매우 넓은 주파수 범위는 주파수 의존적 인 빔 포밍 및 특징 추출을 위해 광범위한 DSP를 필요로 한다. 본 논문에서는 (i) 주파수 선택 비트 스트림 빔 포밍, (ii) 비트 스트림 Mel 주파수 대역 특징 추출 및 (iii) 면적 / 전력 집약적 데시 메이션이 없는 효율적인 연속 시간 SDM 어레이와 같은 특징을 보이고 있다. DNN과 결합 된 시제품 시스템은 Tensorflow 데이터 세트에서 음성 단어를 인식하는 데 95.3 %의 정확도를 보임을 실험적으로 보이고 있다.
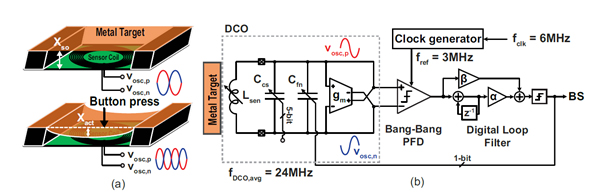
Figure 1. ECS touch sensor application (a) and system block diagram (b)
김 관 태 한국과학기술원 전기및전자공학부 박사과정
4.1 논문은 UCSD에서 발표된 sensor front-end용 VCO-based ΔΣ ADC이다. 이 work의 novelty는 differential pulse-code modulation (DPCM) scheme을 feedback loop내 virtual GND node에 적용시켜 VCO의 nonlinearity를 크게 감소시킨 것이다. 논문에 따르면 DPCM의 digital prediction 기능을 통해 1st-order ΔΣ ADC의 noise transfer fuction (NTF)을 2nd-order로 만드는 것이 가능하다. 그 결과, 32x의 oversampling ratio (OSR)만으로도 VCO input node의 signal swing을 4mVPP이내로 제한할 수 있고 이로 인한 전체 ADC의 peak performance는 88.1/105.1/94.2dB의 SNDR/SFDR/DR에 도달해, 비슷한 power의 sensor용 VCO-based ΔΣ ADC로서는 state-of-the-art를 기록하였지만 (연세대학교에서 올해 발표된 ISSCC’20까지 포함) 낮은 BW로 인해 SNDR FoM은 기존 논문들과 비슷한 수준에 그쳤다. 이 논문의 추가적인 review point들을 짚어보자면 아래와 같다.
첫째, analog supply voltage가 1.2V라는 점인데, 이는 비교 대상인 CICC’19에 비해 1.5x인 수치로, 기존 work들과의 fair-comparison을 흐리게 만든다. Analog supply가 높을수록 VCO-based ADC의 linearity는 점점 더 향상되기 때문이다. 다른 work들과의 power-noise-efficiency를 비교하기 위해 사용한 NEF도 최근 trend에 맞지 않는다는 점도 짚어볼 필요가 있다. PEF=NEF2VDD로 비교를 하는 것이 total power에 대한 fair comparison에 있어 올바른 접근이며, 이 경우 이 논문의 power-efficiency 성능은 크게 떨어진다.
둘째, 논문에서 강조하는 high-input-impedance는 낮은 BW에서의 비교이므로 fair하지 못하다. CICC’19와 비교할 때, 이 논문의 BW는 20배 낮기 때문에 같은 BW를 가정하면 오히려 더 낮은 input impedance를 갖게 된다. 동일 BW를 갖는 ISSCC’18과 비교해보아도 이는 6배 낮은 값이다.
셋째, DPCM의 digital prediction은 ISSCC’18에서 발표된 방법과 유사하다. ISSCC’18에서 사용된 추가적인 ΔΣ noise-shaping 방법 또한 digital domain prediction에 기반을 두기 때문이다. 다만, 어떤 방식이 더 효율적인 접근인지는 설계자의 판단에 맡기는 것이 좋을 것 같다.
4.2 논문은 TU/e에서 발표된 capacitance-to-digital converter (CDC)이다. 같은 group의 같은 저자가발표했던 JSSC’19을 더욱 발전시킨 형태인데, capacitor detection에 사용되는 bridge front-end의 매우 큰 energy 소모량 때문에 SAR ADC 기반의 architecture임에도 불구하고 FoM 성능이 크게 저하되어 있던 기존 work들의 문제점(16fJ/conv.-step)을 charge-reuse로 해결하고, 3배 이상 낮은 4.3fJ/conv.-step의 state-of-the-art FoM을 달성하였다. 이는 CDC 내부에서 사용된 SAR ADC와 비슷한 수준의 FoM이다 (<4.4fJ/conv.-step). CDC내 capacitor detection bridge의 target sensing range는 수 pF 수준이지만, SAR ADC에서 사용되는 total capacitance는 10배 이하 range인 128fF (10b 기준)까지도 내려갈 수 있기 때문에 (Harpe, JSSC’19) 각각의 sub-block에서 소모하는 power consumption에는 차이가 심했고, 기존 work들의 CDC FoM이 ADC의 FoM까지 향상되는데에는 한계가 존재했다. 해당 논문에서는 charge reuse를 통해 detection bridge의 power를 줄였는데, detection bridge의 reset을 SAR ADC 단의 conversion이 일어날 때마다 하는 것이 아니라 한 번 reset후 여러 번의 conversion을 하는 방법을 통해 average power를 낮췄다. 일종의 duty-cycled reset이라고 볼 수 있다. 또한, 설계된 asynchronous 구조의 ADC는 conversion이 끝나면 다음 clock edge가 올 때까지 automatic power gating을 되도록 하여 (Pelzers, SSC-L’20) 전체적인 CDC power를 더욱 줄일 수 있었다. 다만, CDC의 SNR이 48dB, resolution이 7fF 정도로 기존 work들에 비해 (76dB & 0.29fF, Tang, ISSCC’19) 다소 낮은 값이기 때문에, 한정된 application에서만 power-efficiency의 이점이 효과를 볼 수 있을 것으로 보인다.
CB4.3
4.3 논문은 KAIST에서 발표된 bio-impedance (Bio-Z) sensor용 sinewave current generator이다. Bio-Z의 측정은 인체에 소량의 current를 주입한 후 결과로 나타나는 voltage를 측정하여 옴의 법칙에 따라 역산을 하는 방식으로 이루어지기에 current 주입 waveform이 매우 중요한데, 이 논문에서는 0.088%의 낮은 THD와 6.2μW의 ultra-low-power를 소모하는 chip을 발표하였다. 이는 Bio-Z sensor용 current generator로서는 최초로 sub-0.1% THD, sub-10μW power 수치를 달성한 것인데, 측정 오류가 다소 높음에도 불구하고 구현이 쉽고 전력을 적게 소모한다는 이유로 종종 쓰이던 square-wave modulation 방식이 점차 완전히 대체될 수 있을 것으로 기대된다.
이 논문의 핵심 idea는 sinewave를 생성하는 look-up table에 digital ΔΣ modulation을 적용하여 DAC를 포함한 analog stage에서의 overhead를 줄이겠다는 것이다. 기존 논문들의 경우, sinewave의 quantization step 개수를 늘리면 DAC stage의 design overhead도 그에 비례해 증가한다는 문제점이 있어 power efficiency에 손해를 볼 수밖에 없었는데, digital ΔΣ modulation을 거치면 DAC의 구현이 간편해짐과 동시에 dynamic element matching의 hardware cost도 크게 줄어든다는 장점이 있다. 여기에 추가로, analog stage의 overhead가 digital stage로 넘어오면서 발생하는 issue는 0.5V의 near-threshold operation을 통해 low-power로 구현을 하였다. ΔΣ modulated DAC의 뒷 단으로 따라붙는 LPF 및 V-I converter의 경우 이 논문에서는 소개되지 않았으나 같은 group의 ISSCC’19 및 JSSC’20 논문에서 0.5V의 낮은 supply 및 low-power로 구현하여 소개된 바가 있다.
제안된 Bio-Z용 current generator의 digital core의 power는 2.56MHz clock frequency에서 1.29μW만을 소모하며, 이는 대부분의 power가 V-I converter에 집중될 수 있도록 도와주어 overall sensor의 power-noise efficiency를 끌어올려준다.
다만 아쉬운 점이 있다면, 이 논문에서 선보인 output current의 frequency는 20kHz로, 좀 더 높은 frequency의 current generation에 대한 report가 없다는 점이다. 이는 100kHz 이상의 frequency를 요구하는 electrical impedance tomography (EIT)와 같은 application에 필수적인 요소이다.
4.4 논문은 Univ. of Texas at Austin에서 발표된 portal nuclear magnetic resonance (NMR) system에 관한 논문이다. NMR은 원자핵에 특정 energy가 주입되면 이에 반응하여 내뿜는 resonance를 측정하는 방식으로 이루어진다. Resonance frequency는 원자핵의 spin frequency에 의해 결정되는데, 기존 논문들에서는 Rx stage에서 spin frequency보다 충분히 낮은 frequency로 demodulation을 하여 (lock-in amplification) baseband signal을 측정하는 방식으로 이루어졌다. 이 경우 Tx stage의 leakage로 인한 offset, baseband의 낮은 frequency 때문에 발생하는 1/f noise issue등으로 인한 문제 등이 제기된다. 이를 해결하기 위해, 이 논문에서는 spin frequency와 같은 Tx frequency를 사용하는 대신, demodulation에 사용하는 local oscillator의 frequency와 Tx frequency를 다르게 두어 baseband frequency가 높은 range에 위치하도록 하였다. 이 때, TRx의 frequency가 달라지면 phase 차이로 인한 signal loss가 생길 수 밖에 없는데, Tx oscillator와 Rx oscillator의 phase를 align하기 위해 PFD와 LPF, DFF으로 간단한 phase coherence detector를 구현하는 방식으로 이를 해결하였다. 그 결과, 50kHz의 baseband frequency로 현재까지 보고된 논문들 중 가장 높은 수치를 유지하면서도 안정적인 NMR sensing을 구현할 수 있었다.
하지만, 논문에서 주장하는 highest integration level과는 별개로 Tx oscillator 및 Rx oscillator가 off-chip으로 구현되었다는 점은 아쉬운 부분이며, baseband Rx chain의 dead-time을 줄이기 위해 feature로 제시된 fast-settling 개념은 이미 수많은 bio-potential amplifier 논문들에서 언급된 scheme이기 때문에 전혀 새로운 구조가 아니다. NMR 측정의 start-up 부터 어떤 방법으로, 혹은 어떤 기준을 통해 settling mode switching을 할 것인지에 대한 구체적인 설명 또한 없기 때문에 더욱 아쉬움이 남는다.
김 유 빈 한국과학기술원 전기및전자공학부 학사과정
높은 성능의 LiDAR은 자율주행 자동차에 반드시 필요하다. 측정 거리가 길고, 내열성이 좋으며, 저렴하고 이미지 해상도가 좋아야 함은 물론이다. 최대 레이저 파워는 제한되어 있으므로, 높은 SBR을 갖고 있는 LiDAR 아키텍처가 중요하다고 볼 수 있겠다. 아래 그림에서 볼 수 있듯이, 낮은 SBR의 Flash I-ToF LiDAR 대신 Scanning D-TOF를 사용할 때 높은 SiPM PDE/gain을 얻을 수 있겠으나, 해상도는 비교적 낮다는 단점이 존재한다. 이번 연구는 dual-data converter와 in-sensor scanning active quenching SPAD array를 통해 앞서 언급한 장단점을 극복했다는 데 그 의미가 있다.
![[그림 5] D-ToF/I-ToF LiDAR overview](./2020/07/resources/images/sub/02/02_30.jpg)
[그림 5] D-ToF/I-ToF LiDAR overview
낮은 가격대의 LiDAR의 경우, SPADs와 TDCs를 혼합한 여러 CMOS LiDar 센서가 존재한다. SPAD는 어두운 전자와 배경 조명으로 인한 소음 펄스를 생성하기 때문에, 여러 TOF 측정치를 기반으로 히스토그래밍 할 수 있는 분리된 DSP가 중요하다. 하지만 이를 위해 디지털 카운터나 SRAM의 배열을 사용하다 보면 픽셀 해상도에 따른 코어 사이즈가 커진다는 한계가 존재했다. 또한, inter-LiDAR IF를 억제하기 위한 최적의 방법론이 부족했다. 이번 연구가 새롭게 제시한 LiDAR 센서 아키텍처는 아래 그림과 같다. 앞서 언급한 한계들을 어느정도 개선했다는 의의를 갖는다.
![[그림 6] The proposed LiDAR system architecture and operation principle of the interference filter](./2020/07/resources/images/sub/02/02_31.jpg)
[그림 6] The proposed LiDAR system architecture and operation principle of the interference filter
ADC footprint를 제한하고, 최적의 4T pixel을 보존하며, on-chip 파워 소비를 피하는 것은 wake-up imager를 설계할 때 다뤄야하는 한계였다. 확장 가능한 판독 체계가 개발되면서 digital pipeline operator의 복잡도를 낮출 수 있는, 온도와 유사한 bitstream 형태가 사용되었다. 3-level awakening 기법은 4b/6b 모션을 감지할 수 있고, 6b 물체를 감지할 수 있다. 아래 그림은 이와 같은 아키텍처를 보여준다.
![[그림 7] Top-level wake-up CIS architecture](./2020/07/resources/images/sub/02/02_32.jpg)
[그림 7] Top-level wake-up CIS architecture
인터넷 뱅킹 등 사용자 자격증명이 필요한 분야가 늘어나면서, FP 센서의 필요성이 높아지고 있다. 축전기나 초음파를 통한 FP 센서의 경우 넓은 범위의 센서에 적합하지 않고, 광학 FP 센서의 경우 CMOS에 센서를 탑재하기 위한 넓은 면적이 단점이었다. 이러한 단점을 해결한 것이 TFT optical area FP sensor이다. 이번 연구는 최초로 게이트 드라이버가 탑재된 ROIC를 제안한다. 디스플레이 드라이버 IC와 터치 센서 패널 IC를 함께 사용할 경우, 다양한 손가락 샘플과 주변 노이즈에도 안정적인 감광도를 보임이 확인되었다. 관련 시스템의 모형도는 아래와 같다.
![[그림 8] The proposed optical fingerprint sensor system](./2020/07/resources/images/sub/02/02_33.jpg)
[그림 8] The proposed optical fingerprint sensor system
센서는 제한된 배터리 용량을 갖고 있음에도 불구하고, IoT나 AR/VR로 인해 상시 작동할 수 있는 센서에 대한 필요성이 제기되고 있다. 이미지 퀄리티를 위해선 가장 적은 에너지를 소비하는 센서가 필요하다. 하지만 이미지 퀄리티의 개선은 곧 많은 에너지 소비로 이어져 관련 연구에 어려움이 존재했다. 또한, ADC power, 메모리 사이즈, I/O power를 줄이기 위해서는 기존의 데이터 압축과 달리 픽셀 디지털화 이전에 관련 작업들이 이루어져야 했다. 이번 연구는 높은 에너지 효율의 SC CS인코더를 제시함으로써 이러한 문제점에 접근했다는 의의를 갖는다.
![[그림 9] Proposed CMOS imager architecture](./2020/07/resources/images/sub/02/02_34.jpg)
[그림 9] Proposed CMOS imager architecture
송 주 미 성균관대학교 신소재공학부 석사과정
#3.1에서는 두 가지 온칩 서브 시스템 (저전력, 클록리스, 이벤트 중심의 AR) 및 에너지 효율적인 온 디맨드 (on-Demand)를 활용하여 처리 및 에너지의 격차를 극복하는 다목적 IoT 노드를 제시한다. 짧은 산발적 컴퓨팅에 최적화 된 207ns의 웨이크 업 시간을 갖춘 1.7MOPS 이벤트 중심의 비동기식 웨이크 업 컨트롤러 (WuC)가 포함되어 있으며 OD는보다 복잡한 작업을 위해 딥 슬립 RISC-V CPU와 1.3TOPS / W 머신 러닝 (ML) 및 암호 가속기를 결합함을 보여준다. 노드는 최대 36GOPS를 수행하면서 최대 전력 소비에서 15,000배 감소를 달성 할 수 있습니다. 이 다목적 아키텍처의 관심은 적용 분류 시나리오에서 일일 평균 105μW의 전력으로 입증됨을 보여주고 있다. 이벤트 중심 IoT 노드는 산발적인 컴퓨팅의 전력 소비를 줄이는 방법중 하나로 AR 서브 시스템에서 비동기 로직을 사용하여 이벤트 중심 WuC와 OD의 특수 가속기를 포함하는 에너지 효율적인 동기식 RISC-V CPU를 결합하고 있다. #3.2에서는 SCμM에서 전체 6TiSCH 스택을 실행하는 데 필요한 2 단계 교정 루틴에 대해 설명하고 있다. 단일 칩 마이크로 모트(SCμM,)는 ARM Cortex-M0 및 IEEE802.15.4 및 BLE와 호환되는 2.4GHz 무선 장치를 포함하는 시스템 온 칩으로 기존 라디오와 달리 외부 수정 발진기가 없는 안테나와 전원만 필요하다. SCμM은 표준 준수를 제공하여 "스마트 더스트" 비전을 실현할 수 있다. 스마트 웨어러블 또는 마이크로 로보틱스와 같은 애플리케이션에는 SCμM 칩간에 신뢰할 수있는 네트워킹이 필요하며 표준화 된 사물 인터넷 프로토콜 스택은 외부 수정 발진기를 사용하여 SCTiM에서 6TiSCH 스택을 실행할 수 있음을 가장 먼저 보여준다. #3.3에서는 필터가 없는 65nm CMOS MEMS에서 -99dBm 감도, 260nW 434MHz ISM 대역 웨이크 업 수신기 (WuRX)에 대해 설명하고 있다. 무선 센서의 효율적 에너지를 위한 사물 인터넷 (IoT) 네트워크를 실현하려면 장거리 및 대기 시간이 짧은 서브 와트 웨이크 업 수신기 (WuRX)가 필수적이다. 기존 발표된 연구에서 Envelope-Detector-First WuRXs는 전력 목표를 달성했지만 입력 정합 인덕터의 품질 계수에 의해 감도가 -82dBm 미만으로 제한되었다. 또한, Tuned-RF (TRF) WuRX는 최근 듀티 사이클 활성 RF 게인을 추가하여 100dBm의 감도를 능가했지만 개선 된 감도는 부피가 큰 오프 칩 MEMS를 필요로 하므로 IoT 노드의 통합 크기와 비용이 증가된다는 문제점이 존재한다. 이전의 WuRX 솔루션은 멀티 채널 작동을 제공 할 수 없었기 때문에 전력 소모가 큰 PLL 또는 멀티 톤 전송 없이 채널 효율과 노드 밀도를 높혀왔다. 본 논문에서는 MEMS없이 260nW에서 -99dBm 감도를 달성하고 새로운 단일 톤 채널 내장형 OOK (CE-OOK) 신호 방식으로 멀티 채널 작동을 허용하는 비트 레벨 듀티 사이클 TRF WuRX로 언급되 기존의 문제를 극복하고 있다. #3.4에서는 BLE 및 Wi-Fi 표준을 모두 지원하는 최초의 이중 모드 웨이크 업 수신기 (WuRX)를 제안하고 있다. 새로운 등급의 IoT 장치에는 이상적으로 다음과 같은 WuRX가 필요합니다. 1) 저가 배치를 위해 상용 라디오와 직접 통신. 2) 메인 라디오와 유사한 감도를 제공 3) 간섭자에게 탄력적 4) 완전한 통합 5) 저전련 작동. 대부분의 표준 부과 변조 방식에는 높은 데이터 전송률 / 전력이 필요하기 때문에, 이전 연구에서는 저전력 하드웨어에서 전송을 디코딩 할 수 있도록 해킹 호환 변조기를 제안하고 있었다. 이러한 백 채널 WuRX는 전술 한 사양 중 하나 이상을 달성 할 수 있게 해주었다. 그러나 모든 사양의 동시 달성은 여전히 해결되지 않은 상태이다. 본 논문에서는 지연 시간이 낮은 구성 가능 전력에서 간섭 복원력 및 감도에서 기존의 기술과 일치하거나 능가하는 최초의 듀얼 모드 WiFi / BLE WuRX를 제시하고 있으며 제안된 WuRX는 BLE 광고 채널 호핑을 지원하는 주파수 계획을 통해 최첨단 전력 (4.4μW), 감도 (-92dBm) 및 간섭 복원력 (SIR = -67dB)을 달성하였다. #3.5에서는 에너지 효율적인 광역 네트워킹을 가능하게 하는 16-FSK 수신기의 저전력 IC 구현을 최초로 소개하고 있다. 산업 IoT 또는 스마트 농업과 같이 물리적으로 분산 된 Ad-hoc 네트워크를 통해 배포되는 배터리 구동식 IoT 장치는 장거리 통신하고 합리적인 데이터 속도로 작동하면서 낮은 (이상적으로 mW 미만) 전력을 소비하는 트랜시버를 필요로 한다. TX와 RX 모두에서. 1km에 걸쳐 920MHz에서 경로 손실은 91.5dB이므로 TX 출력 전력이 -3dBm이므로 낮은 복잡도의 이진 FSK를위한 링크 예산을 닫기 위해서는 달성 할 수 없는 0dB의 RX 잡음 지수 (NF)가 필요로 하다. Figure 1a에 도시 된 바와 같이 변조 (BFSK) 대신 16-FSK 변조를 사용하여 BFSK에 비해 고유 한 5.1dB Eb / N0 이점을 제공합니다(그림 1b). 6-FSK는 동일한 데이터 속도에 대해 42 % 더 많은 대역폭을 요구하지만 1.5dB 더 높은 통합 잡음 플로어는 Eb / N0의 장점보다 훨씬 뛰어나므로 순 3.6dB 개선으로 훨씬 더 합리적인 3.6dB NF를 보이고 있다. 잠재적 인 PVT 변동을 고려할 때, 이 작업은 작고 효율적이며 쉽게 조정 가능하며 PVT에 내성이 있는 복조를 위해 Miller-증강 커패시터가 있는 N-경로 필터를 사용하는 16 채널 필터 뱅크를 제안하고 있다.
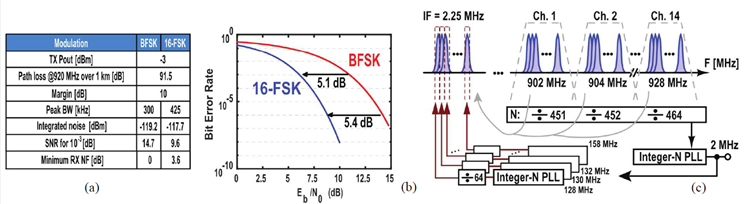
Figure 1. (a) Link budget, (b) waterfall curve for 16-FSK and BFSK, and (c) frequency plan.
권 예 린 서울과학기술대학교 전기정보공학과 학사과정
Zheng Guo, Jami Wiedemer, Yusung Kim, Prithvee Sundararajan Ramamoorthy, Prateeksha Bindiganavile Sathyaprasad, Smita Shridharan, Daeyeon Kim, Eric Karl (Intel)
A 10nm SRAM Design using Gate-Modulated Self-Collapse Write Assist Enabling 175mV VMIN Reduction with Negligible Power Overhead#CM1.1은 인텔에서 발표한 논문으로, 10nm CMOS 기술에 0.0367um2 HCC 비트셀을 사용한 21Mb/mm2 SRAM 디자인을 제시했다. SoC 에너지 효율 목표를 달성하기 위해 저전력 구동이 필수적이지만 SRAM VMIN이 보통 제한적이다. 음극 비트라인과 voltage collapse write assist 기술이 저전력 SRAM 운전을 가능하게 하지만 상당한 active power overhead가 발생한다. 이를 보완하기 위해, Gate-modulated self-collapse (GSC) write assist를 활용하여 energy overhead를 최소화하면서 VMIN을 175mV 감소하는 것을 가능하게 했다. 10nm CMOS 기술에서 최소 energy overhead로 낮은 구동 전압을 가능하게 한 것이다.
![[그림 1] Measured VMIN distributions at -10C from 9Mb HCC arrays with different assist options, at 25MHz and 450MHz.](./2020/07/resources/images/sub/02/02_36.jpg)
[그림 1] Measured VMIN distributions at -10C from 9Mb HCC arrays with different assist options, at 25MHz and 450MHz.
Yoshisato Yokoyama, Miki Tanaka, Koji Tanaka, Masao Morimoto, Makoto Yabuuchi, Yuichiro Ishii and Shinji Tanaka (Renesas Electronics)
A 29.2 Mb/mm2 ultra high density SRAM macro using 7nm FinFET technology with dual-edge driven wordline/bitline and write/read-assist circuit#CM1.2은 Renesas Electronics사에서 발표한 논문으로, 7nm CMOS FinFET 기술을 사용한 29.2Mb/mm2 초고밀도 SRAM 매크로를 제안했다. 소형 SoC칩에 대용량 SRAM이 탑재되면서 모바일, 인공지능, 자율주행이 가속화될 수 있었다. 하지만 7nm 이하 비용이 엄청나게 상승하고 있다는 것이 문제점이다. 일반적으로 칩 내부의 50% 이상을 차지하는 SRAM은 높은 금속-와이어 저항력을 가진다. 이로 인해 긴 비트라인(BL)과 워드라인(WL)은 SRAM 매크로 사이즈가 줄어드는 것을 막는다. 이러한 문제점을 해결하기 위해 논문에서는 비트 밀도 29.2Mb/mm2를 달성하는 BL과 WL 양쪽에 듀얼 드라이브 회로를 사용함으로써 매크로를 분할하지 않는 512x 512 SRAM을 제안한다.
![[그림 2] Word-line (WL) delay vs. WL length and write margin dependence on bit-line (BL) length in 7nm Fin-FET process](./2020/07/resources/images/sub/02/02_37.jpg)
[그림 2] Word-line (WL) delay vs. WL length and write margin dependence on bit-line (BL) length in 7nm Fin-FET process
![[그림 3] Block diagram of proposed SRAM (512 x 512 array)](./2020/07/resources/images/sub/02/02_38.jpg)
[그림 3] Block diagram of proposed SRAM (512 x 512 array)
J. P. Kulkarni, A. Malavasi, C. Augustine, C. Tokunaga, J. Tschanz, M. M. Khellah, V. De (Intel)
Low Swing and Column Multiplexed Bitline Techniques for Low-Vmin, Noise-Tolerant, High-Density, 1R1W 8T-bitcell SRAM in 10nm FinFET CMOS#CM1.3은 인텔에서 발표한 논문으로, 1R1W 8T SRAM에서 Vmin을 낮추고 노이즈 tolerance를 개선하는 LS 및 LS+CM BL 기법을 제안한다. 비트 셀이 1-Fin 트랜지스터로 확장되면서 1R1W 8T-SRAM 어레이는 이전 FinFET 노드에서 비트셀 밀도 확장 문제에 직면해있다. 최소 크기의 HD 비트셀은 증가하는 프로세스 변화에 취약하여 높은 Vmin과 낮은 노이즈 tolerance를 갖는다. 이를 해결하기 위해 직렬 NMOS 클리퍼와 분할 입력 NAND를 사용하여 읽기 Vmin과 noise tolerance를 개선했다. 측정결과, 제안된 LS(LS+CM) BL 구성에서 30(40)mV 낮은 read-Vmin, 18(30)% 낮은 BL 전력을 보여주었으며 noise tolerance와 최소 면적 overhead가 개선되었다.
![[그림 4] Baseline 1R1W 8T SRAM with hierarchical read bitline path and butterfly 512x224 array floorplan supporting 32 bits/LBL](./2020/07/resources/images/sub/02/02_39.jpg)
[그림 4] Baseline 1R1W 8T SRAM with hierarchical read bitline path and butterfly 512x224 array floorplan supporting 32 bits/LBL
![[그림 5] (a) Proposed Low Swing Bitline (LS BL) Technique with series NMOS clipper and Spilt Input NAND driven keeper stack (b) Proposed Low Swing + Column Multiplexed Bitline (LS+CM BL) technique with 2:1 column muxing and spilt input NAND driven keeper](./2020/07/resources/images/sub/02/02_40.jpg)
[그림 5] (a) Proposed Low Swing Bitline (LS BL) Technique with series NMOS clipper and Spilt Input NAND driven keeper stack (b) Proposed Low Swing + Column Multiplexed Bitline (LS+CM BL) technique with 2:1 column muxing and spilt input NAND driven keeper
Charles Augustine, Somnath Paul, Turbo Majumder, James Tschanz, Muhammad Khellah, Vivek De (Intel)
2X-Bandwidth Burst 6T-SRAM for Memory Bandwidth Limited Workloads#CM1.4는 인텔에서 발표한 논문으로, 10nm CMOS의 20KB 6T-SRAM 어레이를 제시한다. 10nm CMOS의 20KB 6T-SRAM 어레이는 버스트 모드 작동에서 2배 더 높은 읽기 대역폭을 보여준다. 대역폭을 2배로 증가시키는 것이 층 수를 2배 증가하는 것보다 주파51% 더 높은 에너지 효율과 30% 더 나은 면적 효율을 가진다.
![[그림 6] (a) Baseline, (b) Baseline-2F, (c) Baseline-2Banks, (d) Burst, (e) Burst-1X, (f) serial to parallel conversion for (b)&(d), (g) 2X clock generation for (d)](./2020/07/resources/images/sub/02/02_41.jpg)
[그림 6] (a) Baseline, (b) Baseline-2F, (c) Baseline-2Banks, (d) Burst, (e) Burst-1X, (f) serial to parallel conversion for (b)&(d), (g) 2X clock generation for (d)
Makoto Yabuuchi, Masao Morimoto, Yasumasa Tsukamoto, Shinji Tanaka (Renesas Electronics)
A 7nm Fin-FET 4.04-Mb/mm2 TCAM with Improved Electromigration Reliability using Far-Side Driving Scheme and Self-Adjust Reference Match-Line Amplifier#CM1.5는 Renesas Electronics사에서 발표한 논문으로, ternary content-addressable memory (TCAM)을 사용하여 EM resistance를 60% 향상시킨 솔루션을 제한한다. 또한 새로운 회로가 포함된 7nm Fin-FET 공정에서 고밀도 TCAM 매크로를 설계했다. 측정결과 제안된 매크로에서 총 유효전력이 기존 유효전력 보다 15% 적었다. 7nm 공정 기술을 기반으로 4.04Mb/mm2는 현재 메모리 밀도가 세계 최고 수준이다. 가장 빠른 1.6G search/s를 256-entry/80-bit TCAM 매크로에서 달성함을 언급하고 있다.
[표 2] Comparison of this work to previously published work
| [2] | [3] | [4] | [5] | This work | |
|---|---|---|---|---|---|
| Process | 28nm | 16nm | 12nm | 14nm | 7nm |
| Entry (ML#) | 1K | 128 | 128 | 256 | 256 |
| BIT (SL#) | 80 | 80 | 80 | 160 | 80 |
| Density (Mb/mm2) | 0.61 | 1.80 | 1.08 | 2.01 | 4.04 |
| Search speed(search/s) | 0.4G | 1.25G | 1.5G | 1.4G | 1.6G |
송 충 석 세종대학교 전자정보통신공학과 학사
기존의 CMOS를 이용한 주메모리 SRAM, DRAM은 좋은 성능을 자랑하여 널리 사용되어 왔지만 휘발성 메모리라는 치명적인 단점이 존재한다. 따라서 data를 전원이 꺼진 상태에서도 저장하기 위해 storage(SSD,HDD)가 추가로 필요하고 각 device마다 속도차이 때문에 병목현상(bottle neck)을 야기한다. 이러한 문제점을 없애기 위해 많은 학계, 산업계에서 차세대 메모리를 연구중에 있는데 대표적으로 언급되는 메모리 소자가 Ferroelectric RAM(FRAM), Resistive RAM(RRAM), Phase-change RAM(PcRAM), Magnetic RAM(MRAM) 등이 있다. 본 세션에서는 MRAM의 일종인 spin-trasfer torque MRAM(STT-MRAM) 한편과 STT-MRAM과 구조는 흡사하지만 동작원리가 달라 STT-MRAM의 단점을 보완할 수 있다고 평가받고 있는 SOT-MRAM에 관한 논문 한편, 다른 차세대 메모리에 비해 역사가 길고 여전히 연구가 활발히 진행되고 있는 RRAM 두편으로 총 4편이 게재되었다.
#CM2.2 : Dual-Port Field-Free SOT-MRAM Achieving 90-MHz Read and 60-MHz Write Operations under 55-nm CMOS Technology and 1.2-V Supply Voltage
일반적인 MRAM은 STT-MRAM을 일컬으며 이는 전자의 spin방향과 자성체의 spin 방향에 따라서 저항이 달라지는 것을 이용하여 자성체에 자기장을 걸어주어 spin방향을 조절해 저항을 바꾼다. 그러나 STT-MRAM은 대기상태에서의 소비 전력은 낮으나 동작시 소비 전력이 높고, write latency가 길어 아직 개선해야 할 점이 많은 소자이다. 이를 대신해 SOT-MRAM 소자가 개발되었는데 STT-MRAM구조와 매우 흡사하지만 직접 높은 전류를 흘러주어 spin 방향을 바꾸는 STT-MRAM에 비해 SOT-MRAM은 스핀 홀 효과(spin Hall effect)를 이용하여 spin 방향을 바꾸기 때문에 STT-MRAM의 단점을 보완할 수 있는 소자이다. 더불어 STT-MRAM은 2터미널 소자이기 때문에 read disturbance 문제가 존재하지만 SOT-MRAM의 경우 3터미널 소자로 읽기, 쓰기를 독립적으로 구분되어지기 때문에 이러한 문제가 없어 cache같은 빠른 속력을 요구하는 application에 적합하다.
본 논문에서는 SOT-MRAM과 CMOS를 결합해 4kB 메모리를 최초로 제작하였다. CMOS와 결합하여 read와 write path를 다르게 할 수 있었고, 이는 read 동작시 저항변화를 야기시키지 않아 read disturbance 효과가 발생하지 않는다. 또한 앞서 언급했듯이 read, write path가 구분되어 있어 dual port로 구성하기가 매우 쉽다. Dual port로 구성하여 read와 write를 동시에 할 수 있으며, 이는 단일 port로만 만들 수 있는 STT-MRAM에 비해 memory bandwidth가 더 넓음을 알 수 있다. Bandwidth가 넓기 때문에 멀티 코어 CPU 혹은 FPGA에 사용되기 적합하다.
또한 read 동작시 낭비되는 에너지를 줄이기 위해 dummy bit line을 설계하여(self termination scheme) 읽고자 하는 memory cell을 낭비되는 시간 없이 바로 읽을 수 있도록 하였다. 그 결과 scheme을 사용할 때가 사용하지 않을 때보다 25MHz에서 28퍼센트, 75MHz에서 10퍼센트정도 감소하였다.
![[그림 1] 본 논문(CM2.2)에서 제시한 SOT-MRAM의 prototype과 spec](./2020/07/resources/images/sub/02/02_42.jpg)
[그림 1] 본 논문(CM2.2)에서 제시한 SOT-MRAM의 prototype과 spec
본 논문에서는 RRAM의 reset 동작을 개선시키기 위해 PMOS selector를 이용하고 bit당 집적도를 높이기 위해 1T2R RRAM 구조를 제안하였다. NMOS selector를 사용할 경우에는 트렌지스터의 threshold voltage만큼 전압강하(voltage loss)가 생기기 때문에 reset 동작에서 상대적으로 큰 reset 전압이 필요하다. 그러나 동작전압이 커질수록 소모전력은 제곱에 비례하여 증가하기 때문에 무한정 큰 동작전압을 사용할 수 없는 문제가 존재한다. 따라서 이를 해결하기 위해 selector 트렌지스터를 PMOS로 사용하여(threshold voltage가 음의 값을 갖기 때문에 voltage loss가 생기지 않음) 충분한 reset voltage를 확보하였다.
더불어 집적도를 올리기 위하여 1T2R 구조를 사용하였는데 기존 1T1R 구조에 비해 소자를 한 개 더 사용하였기 때문에 cell 당 면적은 커지지만, 1T2R구조를 이용하여 총 3가지 상태(1.5bit)를 구현하였기 때문에 bit 당 면적을 감소시켜 집적도를 향상시켰다. 2개의 resistor가 각각 HRS, LRS 두가지 상태를 만들 수 있고, 그에 따라 총 4가지 조합을 만들 수 있다. 그 4가지 중 sneaking current의 영향이 매우 큰 (LRS,LRS) 조합을 제외한 3가지((HRS,LRS), (HRS,HRS), (LRS,HRS))로 three-state-storage(1.5bit)를 구현했다. 특히, (LRS,LRS) 조합을 사용하지 않기에 sneaking path에 적어도 한 개의 resistor가 HRS상태인 cell이 존재하므로 sneak current를 1T1R 구조에 비해 큰 폭으로 줄일 수 있었다(약 90% 감소).
Memory cell과 더불어 주변회로에 대한 설계에도 눈여겨볼점이 있었다. 본 논문에서 사용된 bipolar RRAM은 set과정에서 일정전류 이상 흐르지 못하게 compliance current(이하 CC)를 걸어줘야 하는데, array 구조로 RRAM cell을 만들 경우 sneaking current 때문에 정확한 CC가 전달되지 않을 수 있다. 이를 보상하기 위해 self-adaptive write driver를 설계하여 95퍼센트 이상의 정확한 CC를 전달할 수 있게 되었다. 추가로 PMOS selector를 사용하기 때문에 bit line(RRAM의 top electrode 방향)에 read voltage를 걸어주는 것이 아니라 source line(RRAM의 bottom electrode 방향)에 read voltage를 걸어주어 sense amplifer가 memory cell 상단에 존재하게 설계하였다(reverse read scheme).
본 논문에서 PMOS selector를 이용해 1T2R RRAM을 설계한 결과 read disturbance는 LRS, HRS에서 각각 125mV, 340mV 이하였고, sense margin은 1ns에 85mV 이상이었다. 칩 제작은 28nm logic 하에 진행되었고 14.8Mb/〖mm〗^2 storage density를 가져 이전 연구에 비해 40퍼센트 커진 것을 알 수 있다.
![[그림 2] 본 논문(CM2.3)에서 제시한 1T2R RRAM 구조](./2020/07/resources/images/sub/02/02_43.jpg)
[그림 2] 본 논문(CM2.3)에서 제시한 1T2R RRAM 구조
-
 명예기자 강우석
명예기자 강우석- 소속 성균관대학교 신소재공학부 학사과정
- 이메일 kws8643@naver.com
-
 명예기자 권예린
명예기자 권예린- 소속 서울과학기술대학교 전기정보공학과 학사과정
- 이메일 tb_elec_engineer@naver.com
-
 명예기자 김관태
명예기자 김관태- 소속 한국과학기술원 전기및전자공학부 박사과정
- 이메일 kwantae.kim@kaist.ac.kr
-
 명예기자 김유빈
명예기자 김유빈- 소속 한국과학기술원 전기및전자공학부 학사과정
- 이메일 betty4003@kaist.ac.kr
-
 명예기자 송충석
명예기자 송충석- 소속 세종대학교 전자정보통신공학과 학사
- 이메일 scs940430@naver.com
-
 명예기자 송주미
명예기자 송주미- 소속 성균관대학교 신소재공학부 석사과정
- 이메일 joomsong@skku.edu
-
 명예기자 은남경
명예기자 은남경- 소속 성균관대학교 신소재공학부 학사과정
- 이메일 nkeun1122@naver.com
